Hinweis: Dieser Artikel beschreibt die ZFS-Verschlüsselung unter Solaris 11 und OpenIndiana. Unter OpenZFS (FreeBSD 13+, Linux) gibt es seit 2019 native Verschlüsselung mit zfs create -o encryption=aes-256-gcm -o keyformat=passphrase pool/dataset — das funktioniert ohne die Solaris-spezifischen PAM-Module. Für verschlüsselte Backups auf FreeBSD mit geli siehe ZFS-Backup auf USB-Platte mit geli.
Verschlüsseltes Dataset anlegen
Ab ZFS Version 30 lässt sich ein Dataset beim Erstellen verschlüsseln — mit AES-128, AES-192 oder AES-256. Bei Schlüsseln größer 128 Bit macht eine Hardwarebeschleunigung Sinn (SPARC T2/T3, Intel AES-NI). Für die meisten Szenarien reicht AES-128 völlig aus.
zfs create -o encryption=on rpool/export/home/kernel/DatenSafe Enter passphrase for 'rpool/export/home/kernel/DatenSafe': Enter again:
Nach einem Reboot wird das verschlüsselte Dataset nicht automatisch eingehängt — man muss es manuell mounten:
zfs mount rpool/export/home/kernel/DatenSafe Enter passphrase for 'rpool/export/home/kernel/DatenSafe':
Schlüssel als Datei
Statt einer Passphrase kann der Schlüssel auch als Datei auf einem USB-Stick liegen:
zfs create -o encryption=on -o keysource=raw,file:///media/usb-stick/schluessel \ rpool/export/home/kernel/DatenSafe
Dann den USB-Stick getrennt vom System aufbewahren — und eine Kopie des Schlüssels an einem sicheren dritten Ort. Ohne Schlüssel oder Passphrase sind die Daten nicht wiederherstellbar.
PAM-Integration: Verschlüsselte Homedirectories (Solaris 11)
Unter Solaris 11 gibt es ein PAM-Modul (pam_zfs_key.so.1), das den Encryption Key des ZFS-Homedirectories an das Unix-Passwort des Benutzers koppelt. Beim Login wird das Homedirectory automatisch entschlüsselt und eingehängt — transparent für den Benutzer, funktioniert mit Konsole, SSH und GDM.
Konfiguration in /etc/pam.conf:
login auth required pam_zfs_key.so.1 create other password required pam_zfs_key.so.1 sshd-kbdint auth requisite pam_authtok_get.so.1 sshd-kbdint auth required pam_unix_cred.so.1 sshd-kbdint auth required pam_unix_auth.so.1 sshd-kbdint auth required pam_zfs_key.so.1 create gdm auth requisite pam_authtok_get.so.1 gdm auth required pam_unix_cred.so.1 gdm auth required pam_unix_auth.so.1 gdm auth required pam_zfs_key.so.1 create
Neuen Benutzer anlegen und beim ersten Login zur Passwortänderung zwingen — dabei wird das verschlüsselte Homedirectory automatisch erstellt:
useradd sebastian passwd sebastian passwd -f sebastian
Beim ersten Login passiert alles automatisch:
login: sebastian Password: Choose a new password. New Password: Re-enter new Password: login: password successfully changed for sebastian Creating home directory with encryption=on. Your login password will be used as the wrapping key.
Prüfen:
zfs get encryption,keysource rpool/export/home/sebastian NAME PROPERTY VALUE SOURCE rpool/export/home/sebastian encryption on local rpool/export/home/sebastian keysource passphrase,prompt local
So sieht der Vorgang im GDM (Gnome Display Manager) aus:


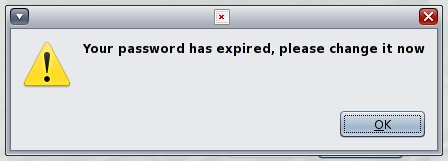


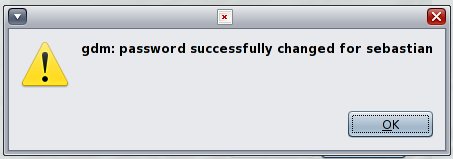
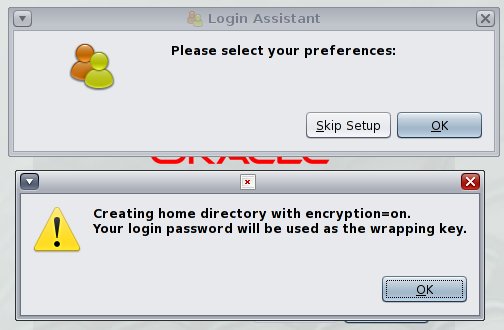
Bestehendes Homedirectory nachträglich verschlüsseln
Ein bestehendes ZFS-Dataset lässt sich nicht nachträglich verschlüsseln. Der Weg: Dataset umbenennen, Benutzer zur Passwortänderung zwingen (erstellt neues verschlüsseltes Home), Daten zurückkopieren:
# Als anderer Admin mit root-Rechten: zfs rename -f rpool/export/home/kernel rpool/export/home/kernel-alt passwd -f kernel # Nach dem Login (neues verschlüsseltes Home wurde angelegt): cp -rp /export/home/kernel-alt/* /export/home/kernel/ zfs destroy rpool/export/home/kernel-alt
Wichtig: Die alten unverschlüsselten Daten liegen nach dem Destroy noch physisch auf der Platte und werden erst nach und nach überschrieben. Für echte Sicherheit müsste man die gesamte Platte überschreiben — oder besser: gleich bei der Installation verschlüsseln.
Mehr zu ZFS: ZFS Compression und Deduplication. Fragen? Einfach melden.
 So ging es mir mit allem was man so mal eben in die Kiste stopfen kann. Ob es nun ein USB-Stick, eine CD/DVD oder eine Wechselplatte ist. Sie wird sauber erkannt und automatisch eingebunden. Es gibt ein schönes Symbol auf dem Gnome Desktop und in dessen Dateiverwaltung. Selbst der Zugriff auf alles klappt tadellos. Aber wehe man möchte das Teil wieder los werden.
Sobald man auf „Aushängen“ klickt, springt einem das System mit der GUI-Meldung an: cannot unmount volume
Sehr nervig…. Konsole aufmachen, su, unmount…..
Dass dieses ein Problem mit irgendeiner Berechtigung sein muss ist schnell klar, aber welcher? Google konnte mir schnell helfen. Das Problem besteht seit 147 bzw. Solaris Express, soll aber inzwischen gefixt sein. Ist es auch, nur taucht es inzwischen durch eine andere Änderung wieder auf. Das ganze ist bekannt und soll gelöst werden. Bisher gibt es einen Workaround.
Einfach nachstehende Zeile in die folgende Datei packen:
So ging es mir mit allem was man so mal eben in die Kiste stopfen kann. Ob es nun ein USB-Stick, eine CD/DVD oder eine Wechselplatte ist. Sie wird sauber erkannt und automatisch eingebunden. Es gibt ein schönes Symbol auf dem Gnome Desktop und in dessen Dateiverwaltung. Selbst der Zugriff auf alles klappt tadellos. Aber wehe man möchte das Teil wieder los werden.
Sobald man auf „Aushängen“ klickt, springt einem das System mit der GUI-Meldung an: cannot unmount volume
Sehr nervig…. Konsole aufmachen, su, unmount…..
Dass dieses ein Problem mit irgendeiner Berechtigung sein muss ist schnell klar, aber welcher? Google konnte mir schnell helfen. Das Problem besteht seit 147 bzw. Solaris Express, soll aber inzwischen gefixt sein. Ist es auch, nur taucht es inzwischen durch eine andere Änderung wieder auf. Das ganze ist bekannt und soll gelöst werden. Bisher gibt es einen Workaround.
Einfach nachstehende Zeile in die folgende Datei packen:

 Der OpenSolaris fork Openindiana und gPodder
Der OpenSolaris fork Openindiana und gPodder