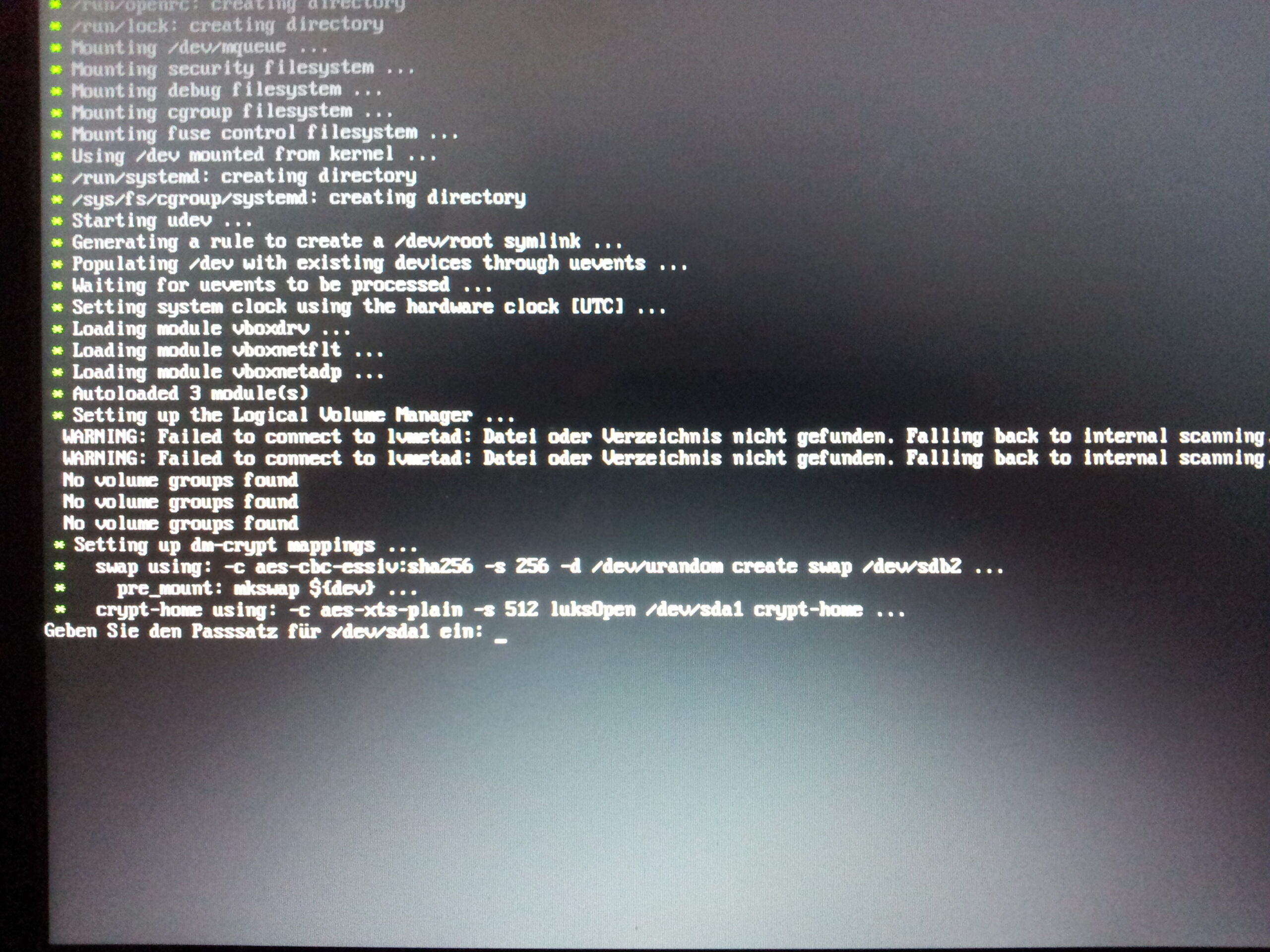
Festplattenverschlüsselung mit LUKS ist eine feine Sache. Bis man beim Booten sein Passphrase eingibt, es dreimal falsch ist und sich fragt ob man den Verstand verloren hat. Man hat sein Passphrase mit deutscher Tastatur eingerichtet, aber beim Booten lädt Linux die Keymap erst nach der LUKS-Abfrage. Also tippt man auf einer englischen Tastatur und wundert sich, warum Y und Z vertauscht sind und die Umlaute fehlen.
Ich hab mich davon auch schon verarschen lassen. Nicht nur einmal. Die Lösung ist je nach Distribution unterschiedlich, aber das Grundprinzip ist immer dasselbe: Man muss dem initramfs beibringen, die richtige Keymap zu laden bevor die Passphrase-Abfrage kommt.
Lösung: vconsole.conf + initramfs
Auf systemd-basierten Distributionen (Debian, Ubuntu, Fedora, Arch) setzt man die Keymap in /etc/vconsole.conf:
# /etc/vconsole.conf
KEYMAP=de-latin1
Danach das initramfs neu bauen, damit die Keymap beim Booten verfügbar ist:
Nach grub-mkconfig -o /boot/grub/grub.cfg greift das beim nächsten Boot. dokeymap weist das initramfs an, die Keymap sofort zu wechseln.
Wenn es zu spät ist
Wer sein Passphrase bereits mit der falschen Keymap eingegeben hat und nicht mehr reinkommt: Das Passphrase auf einer US-Tastatur tippen. Also mental die deutschen Sonderzeichen auf ihre US-Positionen mappen. Z und Y sind vertauscht, ö ist ; und ä ist ‚, Bindestrich liegt woanders. Oder man schließt eine externe USB-Tastatur an und stellt sie auf US. Sobald man drin ist, die Keymap wie oben beschrieben fixen.
Mein Notebook bietet glücklicherweise die Möglichkeit zwei Festplatten zu betreiben. Eine Platte ist eine SSD mit knapp 120GB für das System. Die andere habe ich heute gegen eine Western Digital Scorpio Black mit 750GB ausgetauscht. Hier liegt nun mein „home“.
Ich habe mich beim anlegen der Partitionen dagegen entschieden noch Platz für die Windows Spielepartition zu lassen. Ich habe einfach in den vergangenen Monate kaum noch Zeit zum Zocken gefunden. Irgendwas hatte einfach immer eine höhere Priorität. Nun ist also meine Homedir um 200GB größer und natürlich ganz brav mit luks verschlüsselt. Festplattenverschlüssellung mit Linux wwwwwööööööööööhhhhhhhhyyyyyyy.
Wenn eine Datei gelöscht wird, entfernt das Dateisystem nur den Eintrag aus seinem Inhaltsverzeichnis. Die Speicherblöcke werden als überschreibbar markiert — aber der Datenträger selbst erfährt davon nichts. Bei klassischen Festplatten ist das egal. Bei Flash-Speicher (SSDs, USB-Sticks, Speicherkarten) wird es zum Problem.
Flash-Speicher verteilt Schreibvorgänge gleichmäßig über alle Zellen — das nennt sich Wear Leveling und verlängert die Lebensdauer. Dafür muss der Controller aber wissen, welche Blöcke frei sind. Ohne diese Information kann er irgendwann nur noch den kleinen Reservebereich nutzen und wird spürbar langsam. Genau hier kommt TRIM ins Spiel: Es teilt dem Datenträger mit, welche Blöcke nicht mehr gebraucht werden.
Methode 1: fstrim (manuell oder per Cronjob)
Informiert den Datenträger nur zum Zeitpunkt der Ausführung
Funktioniert ab Kernel 2.6.33
Lässt sich einfach per Cronjob automatisieren
Einmalig ausführen:
fstrim -v /
Täglich per Cronjob — ein Script unter /etc/cron.daily/hdd-trim anlegen:
Die meisten Linux-Distributionen bringen mittlerweile einen systemd-Timer fstrim.timer mit, der wöchentlich TRIM ausführt. Ob er aktiv ist: systemctl status fstrim.timer
Methode 2: discard (Echtzeit-TRIM per fstab)
Informiert den Datenträger in Echtzeit bei jedem Löschvorgang
Erzeugt minimal mehr I/O als periodisches fstrim
Bei modernen SSDs und Kerneln problemlos nutzbar
In der /etc/fstab die Option discard zu den Mount-Optionen hinzufügen:
Device, Mountpunkt und Dateisystem natürlich an das eigene Setup anpassen.
Welche Methode?
Für die meisten Setups reicht der wöchentliche fstrim.timer — das ist heute die empfohlene Methode. discard in der fstab ist sinnvoll, wenn der Datenträger permanent voll ist und sofort von freigegebenen Blöcken profitieren soll. Für ZFS gibt es eine eigene TRIM-Konfiguration — siehe TRIM im ZFS-Pool aktivieren.
Achtung: TRIM sagt dem Datenträger, dass er Blöcke überschreiben darf. Wenn hier etwas schiefgeht, sind Daten weg. Vorher prüfen, ob Kernel, Dateisystem und SSD-Firmware TRIM korrekt unterstützen — und ein Backup haben.
Man man man… Da bittet ein Kollege um ein Zertifikat, ich schraube das schnell zusammen und schiebe es im als .PEM – Base64-kodiertes Zertifikat, umschlossen von „—–BEGIN CERTIFICATE—–“ und „—–END CERTIFICATE—–“ zu.
Nun versucht dieser das Zertifikat auf seinem Windows Server zu importieren. Klappt aber so einfach nicht. Microsoft hätte nämlich gerne das Zertifikat als .PFX (.P12 – PKCS#12, kann öffentliche Zertifikate und private Schlüssel (Kennwort-geschützt) enthalten.) Macht ja auch Sinn wenn es eh in einer Zertifikatsverwaltung liegt und dass ganze Kennwortgeschützt ist. So ist es etwas sicherer, wenn die Datei mal jemanden in die Hände fällt, der es nicht haben soll!
Wie also nun aus PEM ein PFX machen? Openssl hilft:
telefon.de.key sowie telefon.de.crt sollten wir beim einfachen erstellen des Zertifikates per Openssl ja bereits haben. CACert.crt ist einfach der Zertifikat der CA, mit welchem unsere CSR unterschrieben wurde. Noch Fragen?
Veraltet: Dieser Beitrag bezieht sich auf IPv6 Neighbor Discovery unter Solaris/OpenIndiana. Das Konzept (NDP statt ARP) gilt weiterhin, die gezeigten Befehle sind aber Solaris-spezifisch. Unter Linux: ip -6 neigh show.
Damit IPv4 im Ethernet funktioniert braucht man das ARP (Address Resolution Protocol) als Unterbau. Denn sonst würden die IPv4 Pakete ja ihren Weg nicht zur richtigen Netzwerkkarte finden. ARP und IPv4 sind dabei völlig unabhängige Protokolle, sie arbeiten nur seit Jahrzenhten Hand in Hand. Das vergessen viele schnell.
Möchte man also nun herausfinden welche MAC Adresse das System (im gleichen Ethernet-Netzwerk) hat, mit welchem man sich gerade unterhält… Ja, dann bemüht man das ARP.
Unter Linux:
$ arp
Address HWtype HWaddress Flags Mask Iface
errorgrab.kernel-error. ether 00:ff:c9:05:01:c7 C enp2s0
wurstsuppe.kernel-error. ether 50:ff:5d:85:73:48 C enp2s0
Unter Openindiana/Solaris 11:
$ arp -a
Net to Media Table: IPv4
Device IP Address Mask Flags Phys Addr
------ -------------------- --------------- -------- ---------------
rge0 router.kernel-error 255.255.255.255 00:ff:42:72:2b:a6
rge0 192.168.1.31 255.255.255.255 00:ff:b0:ae:0b:eb
rge0 sebastian-solaris.kernel-error 255.255.255.255 SPLA 80:ff:73:4a:38:c7
rge0 all-routers.mcast.net 255.255.255.255 S 01:ff:5e:00:00:02
Bei IPv6 schaut es nun etwas anders aus. Man könnte sagen, hier wurde ARP direkt mit in IPv6 integriert. Es findet sich im Neighbor Discovery wieder. Möchte man hier seine „Nachbarn“ sehen klappt es so:
Unter Linux:
$ ip -6 neigh show
fe80::1 dev enp2s0 lladdr 50:ff:5d:85:73:48 router STALE
fe80::2ff:c9ff:fe05:1c7 dev enp2s0 lladdr 00:ff:c9:05:01:c7 router REACHABLE
Unter Openindiana/Solaris 11:
$ netstat -pf inet6
Net to Media Table: IPv6
If Physical Address Type State Destination/Mask
----- ----------------- ------- ------------ ---------------------------
rge0 33:33:ff:00:00:01 other REACHABLE ff02::1:ff00:1
rge0 00:ff:42:72:2b:a6 dynamic REACHABLE router.kernel-error
rge0 33:33:00:00:00:01 other REACHABLE ff02::1
rge0 33:33:00:01:00:02 other REACHABLE ff02::1:2
rge0 33:33:ff:00:00:06 other REACHABLE ff02::1:ff00:6
rge0 33:33:ff:10:98:82 other REACHABLE ff02::1:ff10:9882
rge0 33:33:ff:ad:7a:dd other REACHABLE ff02::1:ffad:7add
rge0 33:33:ff:00:00:11 other REACHABLE ff02::1:ff00:11
rge0 33:33:00:00:00:16 other REACHABLE ff02::16
rge0 46:ff:91:30:98:3d dynamic REACHABLE 2001:7d8:8001:0:ffff:bdb9:6810:9882
rge0 80:ff:73:4a:38:c7 local REACHABLE sebastian-solaris.kernel-error
rge0 80:ff:73:4a:38:c7 local REACHABLE fe80::ffff:73ff:fe4a:38c7
rge0 00:ff:42:72:2b:a6 dynamic REACHABLE fe80::fff:42ff:fe72:2ba6
rge0 33:33:ff:4a:38:c7 other REACHABLE ff02::1:ff4a:38c7
Früher war es mit dem ARP „einfacher“. Zumindest musste man sich nur einen Befehl merken und dann halt die für das jeweilige Betriebsystem nötigen Schalter herausfinden. Mit IPv6 ist es nun mit in die jeweiligen IP-Tools gewandert. Ich halte es für sauberer auch wenn man sich nun nicht mehr mit den Befehlt „arp“ behelfen kann.
BSD und ihre Ableger nutzen „ndp„. Bei Linux verschwindet alles in den iproute2-Tools mit dem Befehl: „ip“ (ifconfig, route, usw. usw…. alles im Tool ip) Microsoft wirft alles in „netsh„. Unixbasierendes hält sich ans gute alte „netstat„.
Veraltet: Solaris und OpenIndiana werden kaum noch eingesetzt. Unter Linux: ip link show, unter FreeBSD: ifconfig.
Es ändert sich im Laufe der Zeit ja mal immer wieder etwas. So auch der Weg mit Netzwerkkarten umzugehen unter Solaris. Wer also gerade versucht die MAC Adresse seiner lokalen Netzwerkkarte / NIC herauszufinden, dem wird folgender Command helfen:
Benutzer wollen ihr E-Mail-Postfach einrichten. Sie geben E-Mail-Adresse und Passwort ein — den Rest soll der Client erledigen. Bei Exchange mit Active Directory funktioniert das seit Jahren automatisch. Aber was, wenn der Mailserver Postfix und Dovecot heißt und kein Exchange in Sicht ist?
Microsoft Outlook unterstützt auch für IMAP und SMTP die automatische Konfiguration per Autodiscover. Man muss nur wissen, wo Outlook nachschaut — und dort die richtigen Antworten bereithalten.
Wo Outlook nach der Konfiguration sucht
Outlook arbeitet eine feste Reihenfolge ab. Sobald ein Schritt eine gültige Konfiguration liefert, ist die Einrichtung fertig. Schlägt ein Schritt fehl, geht es zum nächsten:
1. Active Directory (SCP) — Ist der Rechner Domänenmitglied, fragt Outlook per LDAP nach einem Service Connection Point. Dort steht normalerweise die URL des Exchange-Servers. Für reine IMAP-Setups irrelevant.
2. HTTPS auf der E-Mail-Domain — Outlook versucht https://example.org/autodiscover/autodiscover.xml. Funktioniert nur, wenn der Webserver der Domain den Pfad bedient.
3. HTTPS auf autodiscover.<domain> — Outlook versucht https://autodiscover.example.org/autodiscover/autodiscover.xml. Das ist der Weg, den wir nutzen. Ein Webserver unter diesem Hostnamen mit gültigem TLS-Zertifikat — mehr braucht es nicht.
4. HTTP-Redirect — Outlook versucht http://autodiscover.example.org/autodiscover/autodiscover.xml und folgt einem 301/302-Redirect. Weniger sicher, aber ein Fallback.
5. DNS SRV-Record — Outlook fragt _autodiscover._tcp.example.org und folgt dem SRV-Eintrag. Bei einem SRV-Verweis auf eine andere Domain zeigt Outlook eine Sicherheitsabfrage: „Konfiguration von dieser Webseite zulassen?“ Einmalig bestätigen, danach läuft es.
6. Lokale XML-Datei — Outlook sucht auf dem Rechner nach einer vorinstallierten Konfigurationsdatei. Für Firmenumgebungen mit Software-Verteilung relevant.
7. Manueller Assistent — Wenn nichts funktioniert hat, öffnet Outlook den Konfigurationsassistenten. Genau das wollen wir vermeiden.
Was Outlook per POST schickt und erwartet
Outlook macht einen HTTP-POST auf /autodiscover/autodiscover.xml und schickt im Body ein XML mit der E-Mail-Adresse des Benutzers:
Die Antwort enthält IMAP- und SMTP-Einstellungen. Der Clou: Weil Outlook die E-Mail-Adresse im POST mitschickt, kann ein PHP-Script sie auslesen und als <LoginName> in die Antwort einsetzen. Ohne diesen Trick würde Outlook nur den Teil vor dem @ als Benutzernamen verwenden — bei Mailservern, die die volle E-Mail-Adresse als Login erwarten, ein Problem.
Multi-Domain per DNS SRV-Record
Ein Autodiscover-Webserver reicht für beliebig viele Maildomains. Jede zusätzliche Domain braucht nur einen SRV-Record im DNS:
_autodiscover._tcp.example.org. IN SRV 0 0 443 autodiscover.kernel-error.de.
Outlook folgt dem SRV-Record, zeigt einmalig die Sicherheitsabfrage, und hat danach die komplette Konfiguration. Das PHP-Script auf dem Zielserver beantwortet Anfragen für alle Domains — die E-Mail-Adresse kommt ja im POST mit.
Umsetzung und aktuelle Konfiguration
Die konkrete Einrichtung — nginx-Konfiguration, PHP-Script und DNS — beschreibe ich im Nachfolgebeitrag: Outlook Autodiscover für IMAP und SMTP konfigurieren. Dort steht auch das Update von 2026 mit den Korrekturen am PHP-Script (GET-Absicherung, XSS-Schutz) und der Zusammenlegung mit Thunderbird Autoconfig.
Wer seine Konfiguration testen will: Microsoft bietet unter testconnectivity.microsoft.com den „Microsoft Remote Connectivity Analyzer“ an. Dort den Autodiscover-Test auswählen und die eigene E-Mail-Adresse eingeben.
Veraltet: Citrix XenServer wird seit 2024 nicht mehr in dieser Form angeboten. Die Storage-Konfiguration hat sich grundlegend geändert. Alternativen: Proxmox VE oder XCP-ng.
Hat man in seinem Citrix XenServer eine Festplatte welche größer ist als 2 Terabyte, egal ob logisch durch RAID oder physikalisch als echte Hardware. So wird diese vom XenServer nicht vollständig genutzt. Das liegt daran, dass der XenServer noch aufs alte Pferd MBR setzt.
Der eingesetzte Kernel kann aber bereits mit GUID Partition Table (GPT) partitionierten Speichern umgehen. Alleine die mitgelieferten Boardmittel (fdisk….) können es auch nicht.
Zusammengefasst bedeutet es:
– Ich kann am Citrix XenServer einen lokalen Speicher der größer ist als 2TB einbinden und benutzen.
– Ich kann diesen Speicher aber nicht anlegen 🙁
Damit wäre also nur das Problem des Anlegens zu lösen!
Voraussetzung ist dass es sich dabei um eine weitere HDD handelt, also nicht die Platte auf welcher das eigentliche Hostsystem Dom0 installiert wurde. Diesen weitern Speicher schraubt man nun also in seinen XenServer. Nun bootet man diesen mit der Hilfe von Parted Magic. Dieses Livesystem ist darauf ausgelegt mit Platten und Partitionen umzugehen. Daher ist es selbst kein Problem auf ein bereits eingerichtetes Linux Sofwareraid zuzugreifen und es bringt das Programm gparted mit.
Gparted wird nun die Hauptarbeit übernehmen, denn es ist schon länger in der Lage GUID Partition Tables (GPT) anzulegen.
Festhalten, es geht los…
– gparted öffnen
– den >2TB Datenspeicher auswählen
– über den Menüpunkt Device den Unterpunkt Create Partition Table auswählen
– unter Advanced den Type der neuen Partitionstabelle auf gpt setzten und (Warnung beachten) anwenden
– den neuen unallocated Speicher markieren
– über den Menüpunkt Partition den Unterpunkt New auswählen
– nun den File system Type auf lvm2 pv setzten und Hinzufügen
– Abschließend noch diese Änderungen anwenden über den Button Apply
Jetzt haben wir eine GUID Partitionstabelle auf der großen Festplatte mit einer Partition größer 2TB und diese bereits mit dem Dateisystem Logical Volume Manager (LVM). Nun können wir wieder den Citrix XenServer booten und ihn mit seinem neuen 3TB oder 4TB oder was weiß ich Storage bekannt machen.
Nachdem der XenServer hochgefahren ist melden wir uns als Root auf der Shell an. Um den Speicher nutzbar zu machen genügen nun zwei kleine Befehle:
Ich bin inzwischen ja von ZFS schon sehr verwöhnt… Vor allem was so Dinge angeht sich Kombinationen aus Laufwerk, Partition, Mountpunkt und SATA-Port zu merken. Man denkt einfach nicht mehr darüber nach 🙁 Heute bin ich damit mal wieder auf die Nase gefallen. Ok ok…. Natürlich kann man zur Konfiguration auch einfach die UUID nutzen, diese ist dann eindeutig und man kann ähnlich wie bei ZFS die ganzen Zusammenhänge „vergessen“….. Ich finde die UUID-Geschichte aber anstrengend. Diese viel zu lange Nummer zu tippen geht überhaupt nicht, sich diese erst in Konfigurationsfiles zu schieben und dann…. bäääähhhh. Dann kann ich mir die Nummer auch nur wieder schlecht merken.
Wie auch immer. Der Ansatz ist gut und wenn es Konfiguriert ist, geht es ja auch. Um mir nicht noch ein Komando mehr merken zu müssen friemel ich die Zuordnung UUID ==> Devicename immer wie folgt heraus:
Ein Scrub ist die Integritätsprüfung von ZFS — jeder Block im Pool wird gelesen und seine Checksumme verifiziert. Beschädigte Blöcke werden automatisch aus der Redundanz repariert (Mirror oder RAID-Z). Ohne Redundanz erkennt ZFS den Fehler immerhin, kann ihn aber nicht korrigieren.
Empfehlung: Einmal pro Woche oder mindestens einmal im Monat. Auf Produktivsystemen am besten per Cronjob.
Scrub starten
zpool scrub backup
Fortschritt prüfen
zpool status backup
pool: backup
state: ONLINE
scan: scrub in progress since Sun May 27 11:11:00 2012
4.20G scanned out of 74.5G at 102M/s, 0h11m to go
0 repaired, 5.64% done
Scrub abbrechen
Braucht man die I/O-Leistung gerade für etwas anderes:
zpool scrub -s backup
Im Status sieht man dann den Unterschied — stopped statt completed:
# Abgebrochen
scan: scrub stopped after 0h7m with 0 errors on Sun May 27 11:18:52 2012
# Normal beendet
scan: scrub completed after 0h7m with 0 errors on Sun May 26 10:52:13 2012
Ein abgebrochener Scrub setzt beim nächsten Start nicht dort fort, sondern beginnt von vorne.
Scrub per Cronjob
# Jeden Sonntag um 02:00 alle Pools scrubben
0 2 * * 0 /sbin/zpool scrub backup
Unter FreeBSD läuft der Scrub standardmäßig über periodic daily — dort muss man nichts extra einrichten. Unter Linux gibt es je nach Distribution einen systemd-Timer (zfs-scrub-weekly.timer) oder man legt den Cronjob selbst an.