Wenn ein Browser eine HTTPS-Verbindung aufbaut, braucht er normalerweise mehrere DNS-Lookups und Round-Trips, bevor er überhaupt weiß, welche Protokolle der Server unterstützt. Erst A/AAAA-Record abfragen, dann TCP-Verbindung, dann TLS-Handshake, dann Alt-Svc-Header parsen für HTTP/3. Das ist ineffizient und seit November 2023 gibt es mit RFC 9460 eine saubere Lösung dafür: den HTTPS Resource Record.
Die großen Browser Hersteller unterstützen das ebenfalls schon, eigentlich mehr aus Eigeninteresse, denn viele Vorschläge kommen sogar direkt von ihnen. Oh, natürlich sollte die jeweilige Zone auch per DNSSec geschützt sein, denn wir wollen uns hier ja auf´s DNS verlassen können. Richtig?! Wenn ihr also noch kein DNSsec für eure Domain aktiviert habt (warum nicht?) dann bitte jetzt, wir haben bald 2026!
Ich habe das jetzt auf meiner DNS-Infrastruktur (BIND 9.20, FreeBSD, Master-Slave-Setup) für alle relevanten Dienste ausgerollt und dabei auch gleich SVCB-Records für die DNS-Server selbst gesetzt. Hier die Details.
Was ist der HTTPS RR?
Der HTTPS Resource Record (Typ 65) ist in RFC 9460 definiert („Service Binding and Parameter Specification via the DNS“, November 2023). Die Idee ist simpel: ein einziger DNS-Lookup liefert dem Client alles, was er für den Verbindungsaufbau braucht. IP-Adressen, unterstützte Protokolle wie HTTP/2 oder HTTP/3, Ports, und perspektivisch auch die ECH-Konfiguration für verschlüsselten SNI.
Ohne HTTPS RR sieht der Ablauf so aus: Der Client fragt A und AAAA ab, baut eine TCP-Verbindung auf, macht den TLS-Handshake, und erfährt erst aus dem Alt-Svc-Header oder durch ALPN im TLS, dass der Server auch HTTP/3 kann. Beim nächsten Request kann er dann QUIC probieren. Das sind mindestens zwei Verbindungsversuche, bis er auf dem optimalen Protokoll landet.
Mit HTTPS RR weiß der Client schon nach dem DNS-Lookup: „Dieser Server spricht h3 und h2, ist unter diesen IPs erreichbar, und hier ist die ECH-Config.“ Er kann direkt mit QUIC/HTTP/3 starten, ohne vorher TCP probiert zu haben.
Die SvcParams im Detail
Ein HTTPS RR besteht aus einer Priorität (SvcPriority), einem Zielnamen (TargetName) und einer Reihe von Service Parameters (SvcParams). Hier ein Überblick über alle definierten Parameter:
alpn (Application-Layer Protocol Negotiation): Signalisiert welche Protokolle der Server unterstützt. Typische Werte sind h2 (HTTP/2 über TLS), h3 (HTTP/3 über QUIC) oder dot (DNS over TLS). Der Client weiß damit vor dem Verbindungsaufbau, welche Protokolle zur Verfügung stehen.
ipv4hint / ipv6hint: IP-Adressen als Hint. Der Client kann diese nutzen, statt einen separaten A/AAAA-Lookup zu machen. Das spart einen Round-Trip. Wichtig: das sind Hints, keine autoritativen Antworten. Der Client darf und sollte trotzdem den normalen A/AAAA-Record prüfen.
ech (Encrypted Client Hello): Enthält den öffentlichen Schlüssel und die Parameter für ECH. Damit verschlüsselt der Client den SNI (Server Name Indication) im TLS-Handshake, sodass ein Beobachter auf dem Netzwerkpfad nicht sehen kann, welche Domain angefragt wird. Das ist der größte Privacy-Gewinn, den HTTPS RR bieten kann. Dazu später mehr.
port: Falls der Service auf einem nicht-Standard-Port läuft. Bei normalen Webservern auf 443 nicht nötig.
no-default-alpn: Signalisiert, dass die Standard-ALPNs (die sich aus dem Schema ergeben) nicht gelten. Wird benötigt wenn ein Server z.B. nur h3, aber nicht h2 unterstützt.
mandatory: Listet Parameter auf, die ein Client zwingend verstehen muss, um den Record nutzen zu können. Ein Client, der einen mandatory-Parameter nicht kennt, muss den ganzen Record ignorieren.
SvcPriority: Die Priorität des Records. 0 bedeutet AliasMode (Weiterleitung auf einen anderen Namen, ähnlich CNAME), Werte größer 0 sind ServiceMode. Mehrere Records mit unterschiedlichen Prioritäten ermöglichen Fallback-Ketten.
TargetName: Der Zielserver. Wenn er sich vom abgefragten Namen unterscheidet, leitet der Client die Anfrage an diesen Host weiter. Das ermöglicht Indirektion, ähnlich wie bei SRV-Records.
SVCB: Das generische Pendant
Der SVCB Resource Record (Typ 64) kommt aus demselben RFC 9460, ist aber nicht auf HTTPS beschränkt. HTTPS RR ist technisch gesehen nur eine spezialisierte Variante von SVCB für das HTTPS-Schema. SVCB kann für beliebige Protokolle genutzt werden.
Besonders interessant wird SVCB für die DNS Service Discovery nach RFC 9461 („Service Binding Mapping for DNS Servers“, ebenfalls 2023). Damit kann ein DNS-Server per DNS-Record signalisieren, dass er DoT (DNS over TLS) und DoH (DNS over HTTPS, RFC 8484) unterstützt. Der Record liegt unter dem Prefix _dns. vor dem Servernamen.
Der dohpath-Parameter aus RFC 9461 teilt dem Client direkt den URI-Pfad zum DoH-Endpoint mit, z.B. /dns-query{?dns}. Damit braucht der Client keine separate Konfiguration mehr, wo der DoH-Endpoint liegt. Zusammen mit RFC 9462 („Discovery of Designated Resolvers“, DDR) kann ein Client damit automatisch erkennen, dass sein Resolver verschlüsselte Protokolle unterstützt, und automatisch upgraden.
Was ich konkret deployt habe
Insgesamt 5 neue Records in zwei Zonen. Für www.kernel-error.de und cloud.kernel-error.com existierten bereits HTTPS RRs.
Zone kernel-error.de:
Apex HTTPS RR für kernel-error.de selbst:
dig HTTPS kernel-error.de +short 1 kernel-error.de. alpn="h3,h2" ipv4hint=148.251.30.200 ipv6hint=2a01:4f8:262:4716::443
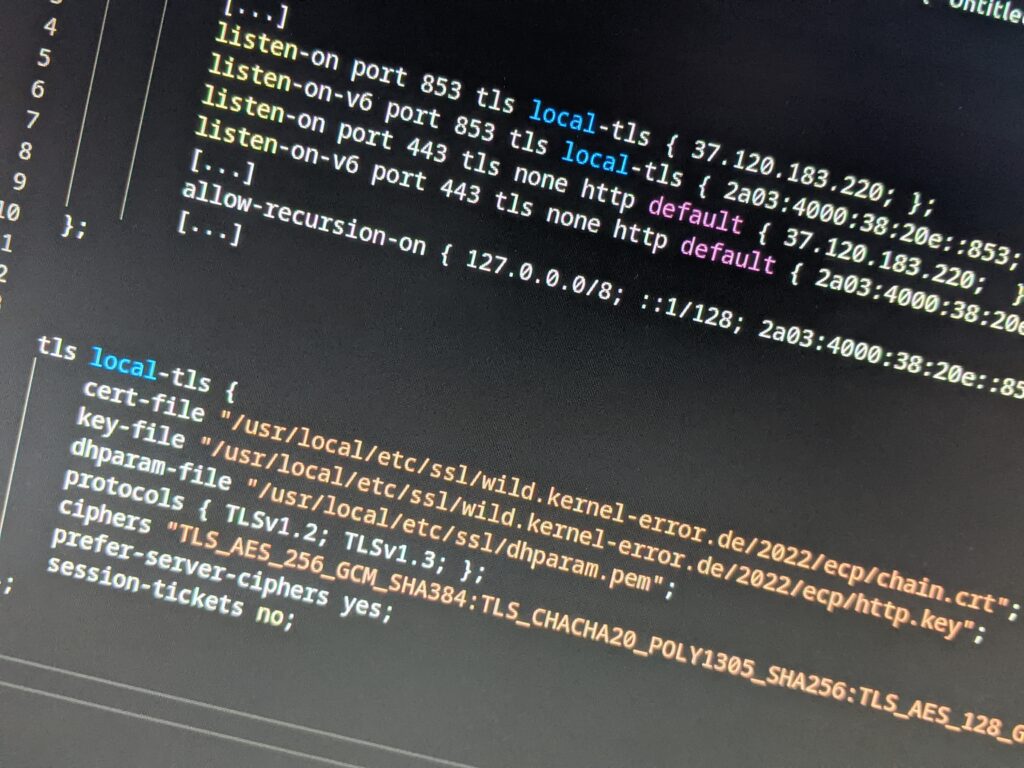
HTTPS RR für den DoH-Endpoint dns.kernel-error.de:
dig HTTPS dns.kernel-error.de +short 1 dns.kernel-error.de. alpn="h3,h2" ipv4hint=37.120.183.220 ipv6hint=2a03:4000:38:20e::853
SVCB Records für DNS Service Discovery nach RFC 9461. Zwei Records mit unterschiedlichen Prioritäten, DoH bevorzugt vor DoT:
dig SVCB _dns.dns.kernel-error.de +short
1 dns.kernel-error.de. alpn="h2,dot" dohpath=/dns-query{?dns} port=443
2 dns.kernel-error.de. alpn="dot" port=853
Priorität 1 bietet DoH über HTTP/2 (Port 443), Priorität 2 reines DoT (Port 853). Ein DDR-fähiger Client (RFC 9462) kann damit automatisch erkennen, welche verschlüsselten DNS-Protokolle mein Resolver unterstützt.
Zone kernel-error.com:
Apex HTTPS RR für kernel-error.com (Matrix Federation und Web):
dig HTTPS kernel-error.com +short 1 kernel-error.com. alpn="h3,h2" ipv4hint=148.251.30.204 ipv6hint=2a01:4f8:262:4716::52
HTTPS RR für matrix.kernel-error.com (Synapse Reverse Proxy). Über CNAME-Auflösung deckt dieser Record auch chat.kernel-error.com und admin.kernel-error.com ab:
dig HTTPS matrix.kernel-error.com +short 1 matrix.kernel-error.com. alpn="h3,h2" ipv4hint=148.251.30.204 ipv6hint=2a01:4f8:262:4716::52
CNAME-Interaktion: Ein wichtiges Detail
Laut RFC 9460 können HTTPS RR und CNAME nicht am selben DNS-Namen koexistieren. Das hat direkte Auswirkungen auf mein Setup: chat.kernel-error.com und admin.kernel-error.com sind CNAMEs auf matrix.kernel-error.com. Ein separater HTTPS RR für diese Namen ist also nicht möglich und auch nicht nötig. Der Client folgt dem CNAME und nutzt dann den HTTPS RR des Ziels.
Gleiches gilt für signaling.kernel-error.com, das ein CNAME auf rtc.kernel-error.com ist.
Was bewusst nicht umgesetzt wurde
ECH (Encrypted Client Hello): Wäre der größte Privacy-Gewinn. ECH verschlüsselt den SNI im TLS-Handshake, sodass ein Beobachter nicht sehen kann, welche Domain der Client anfragt. OpenSSL 3.5 hat die API dafür, aber nginx nutzt sie nicht. Selbst in Version 1.29.7 gibt es keine native ECH-Unterstützung. Dafür bräuchte es entweder Patches für nginx oder einen anderen Reverse Proxy. Sobald sich das ändert, kommt der ech-Parameter in die HTTPS RRs.
DoQ (DNS over QUIC, RFC 9250): DoQ ist ein eigenes Protokoll, das DNS direkt über QUIC transportiert, ohne HTTP-Overhead. Das ist nicht dasselbe wie DoH über HTTP/3! BIND 9.20 unterstützt kein DoQ. Dafür müsste man ein separates Frontend wie dnsproxy oder AdGuard DNS davor setzen.
SVCB für SMTP/IMAP: Es gibt IETF-Drafts, die SVCB auf Mail-Protokolle ausweiten wollen (SMTP Submission, IMAPS). Da diese aber noch kein finaler RFC sind und aktuell kein MTA oder Client sie auswertet, habe ich darauf verzichtet. Die bestehenden SRV-Records (_imaps._tcp, _submission._tcp, _submissions._tcp) sind heute das Richtige.
HTTPS RR für turn.kernel-error.com: Der primäre Zweck ist TURN/STUN, nicht Web. Clients bekommen den Server aus der Synapse-Konfiguration, ein HTTPS RR bringt hier keinen Vorteil.
HTTPS RR für rtc.kernel-error.com: Kein HTTP/3 auf diesem Server, da der nginx dort ohne h3-Modul läuft. Ein HTTPS RR mit nur alpn="h2" würde kaum Mehrwert bringen.
Deployment in DNSSEC-signierten Zonen
Beide Zonen sind mit DNSSEC signiert (ECDSAP256SHA256, inline-signing). Der Workflow für Änderungen an signierten Zonen ist immer derselbe:
rndc freeze kernel-error.de # Zonendatei editieren, Serial hochzählen named-checkzone kernel-error.de /path/to/zone/file rndc thaw kernel-error.de
Nach dem thaw signiert BIND die neuen Records automatisch und der Slave (ns1) übernimmt die Änderungen sofort per NOTIFY und AXFR. BIND 9.20 unterstützt HTTPS und SVCB Records nativ, es ist also kein TYPE65-Workaround mit generischer Record-Syntax nötig.
Records prüfen
Wer sich die Records anschauen will:
dig HTTPS kernel-error.de +short dig HTTPS dns.kernel-error.de +short dig SVCB _dns.dns.kernel-error.de +short dig HTTPS kernel-error.com +short dig HTTPS matrix.kernel-error.com +short
Ausblick
Die offensichtlichste Lücke ist ECH. Sobald nginx native Unterstützung bekommt, wird der ech-Parameter in alle HTTPS RRs eingetragen. Das wäre dann echte SNI-Verschlüsselung für alle Dienste.
SVCB für SMTP und IMAP wäre der nächste logische Schritt, sobald die aktuellen IETF-Drafts zu finalen RFCs werden und MTAs/Clients anfangen, sie auszuwerten. Immer mal wieder setzte ich auch IETF-Drafts in meinem Setup oder Labor Setup um. In diesem speziellen Fall sehe ich darin aber keinen Nutzen. Aus irgendeinem Grund schaffen es solche IT Security Themen bei E-Mails nur sehr selten in eine „schnelle“ Umsetzung. Die Browserhersteller machen da bei HTTPS wohl genug selbst. Viele Ideen kommen ja sogar von diesen.
Und DoQ (RFC 9250) steht auf der Liste, sobald BIND oder ein brauchbarer Proxy es unterstützt. Dann würden die SVCB-Records um alpn="doq" ergänzt. Ich möchte nicht wieder etwas vor meinen DNS stellen. Das wird aber bereits von den großen Browsern unterstützt!
Siehe auch:
- BIND auf FreeBSD: DoT & DoH einrichten — das DoH/DoT-Setup, auf das die SVCB-Records verweisen
- Post-Quantum TLS für Nginx — X25519MLKEM768, HTTP/3 und QUIC auf derselben Infrastruktur
- Jetzt mit HTTP/3 und QUIC — alpn=h3 im HTTPS RR verweist auf dieses Feature
- DNSSEC einrichten: Zonen signieren mit BIND — Voraussetzung, damit HTTPS RR vertrauenswürdig ist
- DNSSEC und DANE: TLSA-Records absichern — gleiches Prinzip: Security-Informationen im DNS
Bei Fragen oder Anmerkungen, einfach fragen.