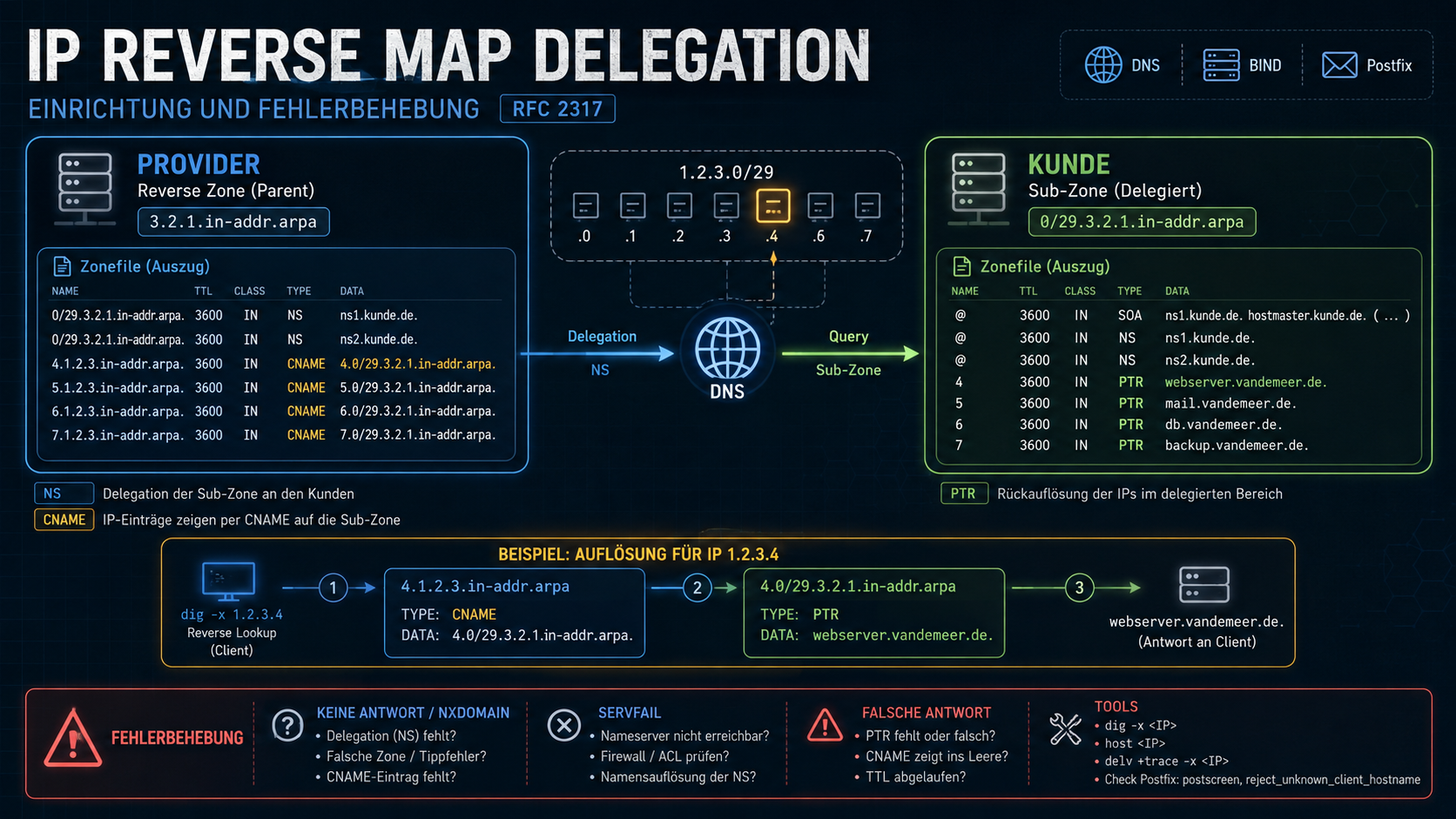
Reverse Map Delegation nach RFC 2317 klingt komplizierter als es ist. Es löst ein konkretes Problem: Wer ein kleines IP-Netz hat (kleiner als /24), kann normalerweise keine eigene PTR-Zone betreiben. Mit Reverse Map Delegation geht es doch.
Warum man es braucht
In der guten alten Zeit bekam man ein /24 (256 Adressen). Da legt man einfach eine Zone 3.2.1.in-addr.arpa. an und fertig. Heute bekommt man, wenn überhaupt, ein /29 (8 Adressen). Und da liegt das Problem: DNS-Zonen werden am Punkt getrennt. Bei einem /24 passt das, bei einem /29 gibt es keinen Punkt an dem man die Zone aufteilen kann.
Der Provider behält also die /24-Zone und richtet für das kleine Subnetz CNAMEs ein, die auf eine „Sub-Zone“ des Kunden zeigen. Der Kunde kann dann seine PTR-Records selbst verwalten.
Die Provider-Seite
In der /24-Zone des Providers wird für das Subnetz 1.2.3.0/29 eine Delegation eingerichtet. Jede IP-Adresse bekommt einen CNAME in die Sub-Zone des Kunden:
$ORIGIN 3.2.1.in-addr.arpa.
$TTL 1D
@ 1D IN SOA ns1.kernel-error.de. hostmaster.kernel-error.de. (
2014101701 ; serial
6H ; refresh
30M ; retry
2W ; expiry
1D ) ; minimum
IN NS ns1.kernel-error.de.
IN NS ns2.kernel-error.org.
; Delegation für 1.2.3.0/29 an den Kunden
0/29 IN NS ns1.vandemeer.de.
0/29 IN NS ns2.vandemeer.de.
0 IN CNAME 0.0/29.3.2.1.in-addr.arpa.
1 IN CNAME 1.0/29.3.2.1.in-addr.arpa.
2 IN CNAME 2.0/29.3.2.1.in-addr.arpa.
3 IN CNAME 3.0/29.3.2.1.in-addr.arpa.
4 IN CNAME 4.0/29.3.2.1.in-addr.arpa.
5 IN CNAME 5.0/29.3.2.1.in-addr.arpa.
6 IN CNAME 6.0/29.3.2.1.in-addr.arpa.
7 IN CNAME 7.0/29.3.2.1.in-addr.arpa.
Die Kunden-Seite
Der Kunde richtet auf seinem DNS-Server die Sub-Zone ein und kann dort seine PTR-Records setzen wie gewohnt:
$ORIGIN 0/29.3.2.1.in-addr.arpa.
$TTL 1D
@ 1D IN SOA ns1.vandemeer.de. hostmaster.vandemeer.de. (
2014101701 ; serial
6H ; refresh
30M ; retry
2W ; expiry
1D ) ; minimum
IN NS ns1.vandemeer.de.
IN NS ns2.vandemeer.de.
0 IN PTR netzadresse.vandemeer.de.
1 IN PTR router.vandemeer.de.
2 IN PTR mailin.vandemeer.de.
3 IN PTR imap.vandemeer.de.
4 IN PTR webserver.vandemeer.de.
5 IN PTR frei.vandemeer.de.
6 IN PTR frei.vandemeer.de.
7 IN PTR broadcastadresse.vandemeer.de.
Ergebnis
Eine Reverse-Lookup-Abfrage für 1.2.3.4 läuft jetzt über den CNAME zum DNS des Kunden und liefert den gewünschten PTR-Record:
dig -x 1.2.3.4 +short 4.0/29.3.2.1.in-addr.arpa. webserver.vandemeer.de.
Probleme
Wäre ja zu schön, wenn es keine gäbe.
Laut RFC darf ein PTR-Record eigentlich kein CNAME sein, außer in genau diesem Fall. Das RFC ist von 1998, aber es hat sich nicht überall herumgesprochen. Man muss seinem Gegenüber gelegentlich RFC 2317 erklären, bevor die Diskussion weitergeht.
Außerdem macht Postfix Ärger, wenn man reject_unknown_client in den smtpd_restrictions hat. Diese Prüfung erwartet, dass PTR und A/AAAA-Record zueinander passen. Bei Reverse Map Delegation tun sie das nicht, weil der CNAME dazwischen steht:
450 4.7.1 Client host rejected: cannot find your hostname, [4.5.6.7]
Wer einen größeren Mailserver betreibt, sollte auf der Mail-IP kein Reverse Map Delegation einsetzen, sondern den PTR direkt beim Provider setzen lassen. Spart Arbeit und Ärger.
Fragen? Einfach melden.





