Etwas über ein Jahr betreibe ich nun bereits meinen eigenen Matrix Homeserver. Als Client dazu nutze ich Riot. Diesen Client gibt es für alle gängigen Geräte, egal ob Smartphone, Laptop oder Browser. Nun ist er in der Version 1.0 veröffentlicht worden.
Nachdem Frankreich nun die Idee verfolgt Matrix zu nutzen. Bin ich sehr gespannt welche Auswirkungen dieses auf Matrix und natürlich Riot haben wird. Wir setzten diese Konstellation schon länger als alternative zu anderen Messangern für Familie, Freunde und Bekannte ein. Der neue Client gefällt allen wirklich gut und er ist sogar noch etwas einfacher und angenehmer zu bedienen als sein Vorgänger. Schaut euch Matrix / Riot doch einfach mal an, ich bin erreichbar über: @kernel-error:kernel-error.com
Mir ist ein weiteres Onlinetool zum scannen seiner Domain durch den Browser gerutscht. https://www.hardenize.com/
Wie immer darf man nicht bild jedem Tool trauen und sich ohne denken darauf verlassen! Die Ergebnisse müssen immer mit dem nötigen Hintergrundwissen und Feingefühl interpretiert werden…. Hardenize testet nach der Eingabe einer Domain etwas umfassender. Es schaut sich die TLS Konfiguration der Webseite, sowie des Mailservers an. Prüft auf wichtige Policys, schaut in den DNS und bewertet somit etwas das Gesamtbild.
Die netten Leute von Thomas Krenn haben uns ihr OpenPOWER-Testsystem zur Verfügung gestellt. Wir wollten dieses System schon länger in die Finger bekommen. Jetzt hat es endlich geklappt.
Die Hardware
Der Server zieht mit seinen zwei 1200-Watt-Netzteilen in der Spitze etwa 370 Watt (im Normalbetrieb um die 230 Watt) und soll laut Thomas Krenn 1.325 BTU/h produzieren. Verbaut sind 128 GB RAM und eine POWER8-CPU:
root@ubuntu:~# lscpu
Architecture: ppc64le
Byte Order: Little Endian
CPU(s): 64
Thread(s) per core: 8
Core(s) per socket: 8
Socket(s): 1
Model name: POWER8 (raw), altivec supported
CPU max MHz: 3857.0000
L1d cache: 64K
L1i cache: 32K
L2 cache: 512K
L3 cache: 8192K
64 Threads auf 8 Cores, SMT8. Das Betriebssystem war ein Ubuntu 16.04 LTS (ppc64le).
Storage-Anpassung
Die mitgelieferten Festplatten (3,5″ Nearline SAS mit 7,2k) waren für unseren Datenbanktest zu langsam. Also haben wir ein paar ältere 15k-SAS-Platten aus dem Lager verbaut und in ein RAID 10 geworfen. Damit war das lokale Storage laut pg_test_fsync vergleichbar mit unseren anderen Testsystemen. Wir wollten ja CPU-Leistung vergleichen, nicht Festplatten.
Alltagsvergleich
Als Erstes ein paar alltägliche Operationen im Vergleich mit Intel-Systemen:
CPU
SHA256 500 MB
bzip2 500 MB
AES 500 MB
2× Xeon E5-2665 @ 2.40 GHz
3,859 s
5,445 s
1,337 s
1× POWER8 @ 3.86 GHz
3,803 s
7,868 s
0,866 s
1× Core i7-6700 @ 3.40 GHz
2,370 s
4,207 s
0,831 s
2× Xeon E5-2650 v4 @ 2.20 GHz
2,652 s
5,413 s
1,585 s
2× Xeon E5-2650 v3 @ 2.30 GHz
2,484 s
5,217 s
1,500 s
AES-Verschlüsselung: POWER8 vorn. SHA256: gleichauf. bzip2: Intel deutlich schneller. Ein gemischtes Bild.
UnixBench
Das OpenPOWER-System gegen ein Dell-System mit zwei Intel Xeon E5-2665 (nur CPU/RAM relevant):
Benchmark
2× Xeon E5-2665
1× POWER8
Dhrystone 2
34.551.077 lps
27.167.564 lps
Double-Precision Whetstone
4.082 MWIPS
4.092 MWIPS
Execl Throughput
2.124 lps
2.776 lps
Pipe Throughput
2.067.851 lps
465.884 lps
Process Creation
4.278 lps
7.391 lps
Shell Scripts (1 concurrent)
5.543 lpm
7.085 lpm
Shell Scripts (8 concurrent)
6.090 lpm
4.357 lpm
System Call Overhead
4.186.840 lps
344.157 lps
Index Score
1.629,6
851,8
Process Creation und Shell Scripts (single): POWER8 vorn. System Calls und Pipe Throughput: Intel massiv besser. Der Index-Score geht klar an Intel, wobei der Vergleich nicht ganz fair ist (Dual-CPU gegen Single-CPU).
PostgreSQL-Restore
Die hohe Thread-Anzahl und die breite Speicheranbindung machen die POWER8 theoretisch zum guten Datenbankprozessor. Wir arbeiten viel mit PostgreSQL, also haben wir unsere Testdatenbank restored:
CPU
Restore-Zeit
2× Xeon E5-2650 v3 @ 2.30 GHz
129 min 34 s
1× POWER8 @ 3.86 GHz
120 min 43 s
Knapp 9 Minuten schneller als das Dual-Xeon-System. Bei Datenbank-Workloads macht sich die Speicheranbindung bemerkbar.
Fazit
Die POWER8 ist ohne Zweifel leistungsstark. Die Speicheranbindung und die 64 Threads merkt man bei Datenbank-Workloads. Im Single-CPU-Vergleich macht das System bei Datenbanken den Stich. Aber: Das OpenPOWER-System von Thomas Krenn gibt es nur mit einem CPU-Socket, preislich liegt es aber auf dem Niveau eines Dual-Xeon-Systems. In diesem Vergleich hat Intel die Nase vorn.
IBM hat die POWER8 2013 vorgestellt, unser Test war 2018. Die Vergleichssysteme waren ebenfalls nicht brandneu. Unterm Strich: Tolle CPU, aber im Preis-Leistungs-Verhältnis für einen Datenbankserver gegenüber Intel der Verlierer. Im HPC-Bereich oder bei der Anbindung von Nvidia-Beschleunigern sieht das sicher anders aus. Dual-CPU-Systeme oder direkt POWER9 (mit einem Hardware-GZIP-Accelerator und erweiterten Crypto-Instructions, AES gab es in POWER8 allerdings schon in Hardware) wären spannend gewesen. Da IBM von diesen CPUs im Vergleich zu Intel nur geringe Stückzahlen verkauft, bleibt der Preis hoch.
Update 2026: was sich seitdem getan hat
Der Test ist von 2018, die Server-Landschaft hat sich seitdem gedreht. IBM hat 2021 die POWER10 vorgestellt (Power E1080, S1014, S1022), inklusive Matrix Math Assist Instructions für AI-Inferenz. Die OpenPOWER-Foundation ist seit 2019 unter dem Dach der Linux Foundation, und für Workstations jenseits der reinen IBM-Welt ist RaptorCS mit den Talos-II-Boards (POWER9) die Community-Anlaufstelle geblieben. ppc64le-Linux lebt ebenfalls, Debian, Fedora, NixOS und diverse andere Distributionen pflegen die Architektur weiter.
Die größere Veränderung kommt allerdings aus der Konkurrenz. AMD EPYC (Genoa, Turin) dominiert heute im x86-Server-Bereich, Intel hat mit Sapphire Rapids und Granite Rapids nachgezogen, und vor allem ARM ist im Rechenzentrum angekommen: Ampere Altra und AmpereOne, AWS Graviton in der dritten und vierten Generation, NVIDIA Grace für HPC und AI. Die Nische für POWER liegt damit 2026 eher bei AIX-Legacy, HPC mit NVLink-Integration und bei Projekten, denen Architektur-Unabhängigkeit wichtig ist. Für den klassischen Datenbank- oder Webserver-Einsatz ist ppc64le ein Exot geworden.
Wer FreeBSD auf anderer Hardware ausprobieren will: FreeBSD auf dem Desktop beschreibt die Grundinstallation mit MATE. Und mit bhyve und vm-bhyve lassen sich Windows-VMs auf FreeBSD betreiben.
Heute mal komplett weg von der IT. Ich lasse mich gerne von gutem Werkzeug beeindrucken, und mein neuer Kreisschneider hat das geschafft. Es war selbst 2018 nicht einfach, ihn zu bekommen. Das Teil ist regelmäßig schneller ausverkauft als der Hersteller nachliefern kann. Gekauft habe ich ihn bei feinewerkzeuge.de. Bei Amazon gibt es sehr ähnliche Modelle, mit denen viele ebenfalls zufrieden sind.
Das Problem mit Topfkreisbohrern
Für kleine Löcher nimmt man einen Bohrer, für größere einen Forstnerbohrer. Wird es noch größer, greift man zum Topfkreisbohrer. Ein ordentlicher kostet schnell 40 bis 100 Euro. Trotzdem hat man ähnliche Probleme wie mit billigen: Das Holz verbrennt, es reißt aus, und das ausgeschnittene Stück klemmt im heißen Bohrkopf. Wer verschiedene Lochgrößen abdecken will, hat ein kleines Vermögen in der Werkstatt liegen und braucht es vielleicht dreimal im Jahr. Natürlich hat man dann doch keine passende Größe. Ein Millimeter zu klein oder zu groß. Also kleiner bohren und dann schleifen. So wird man die Brandstellen gleich mit los. Oder auch nicht.
STAR-M Kreisschneider Nr. 36 HSS
Ein Bekannter hat mir irgendwann zu diesem Kreisschneider geraten. Er lässt sich komplett stufenlos einstellen, man hat also immer die passende Größe. Die Messer und die Zentrierspitze lassen sich einzeln und günstig tauschen, das Werkzeug selbst ist gut bezahlbar. Statt eines großen Bohrkopfs arbeiten nur zwei kleine Messer in massiven Metallhaltern. Weniger Kontaktfläche bedeutet weniger Reibung und weniger Hitze. Die Metallhalter führen die Restwärme zusätzlich ab. Die Japaner wissen, wie man gutes Holzwerkzeug baut.
Praxistest: 18 mm Buche-Leimholz
Hier ein paar Bilder vom Einsatz an einer 18 mm Leimholzplatte aus Buche:
Racktables ist zur Dokumentation seiner Assets im Rack nicht das schlechteste Tool. Es hat ganz klar seine Grenzen aber oft erfüllt es die Anforderungen.
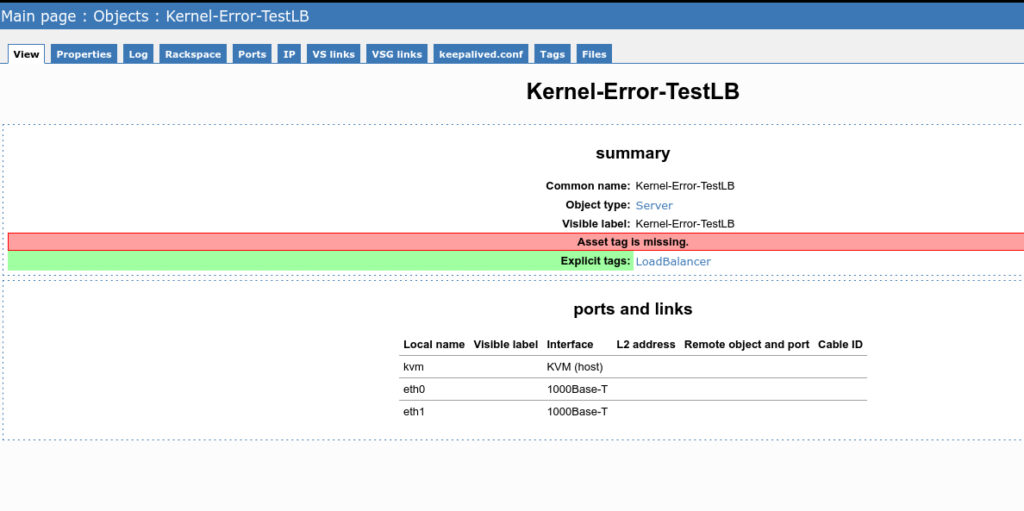
Wie füge ich in Racktables einen Load Balancer hinzu? Vor dieser Frage stand ich vor einiger Zeit. Mein erster Anlaufpunkt war natürlich das Racktables Wiki. Leider wurde ich daraus nicht wirklich schlauer. Die google Suche: „How to add LoadBalancers to racktables“ hat mir ebenfalls nicht geholfen. Irgendwann bin ich auf den Hinweis zur User Interfaceconfiguration „IPV4LB_LISTSRC“ gestoßen. Ab da öffneten sich meine Augen.
Die Option ist im default mit einem false deaktiviert. Aktiviert man sie mit einem einfachen true, tauchen einfach alle Hardwareserver als Load Balancer unter IP SLB ==> Load balancers auf. Das ist fast gut. Fast… ja fast weil dort eigentlich nur die Load-Balancer auftauchen sollten. Da kam mir die Funktion der Tags in den Sinn. Nach diesen lässt sich bei Racktables nicht nur filtern, sondern man kann darauf aufbauend auch Dinge im Interface umorganisieren. Einfachstes Beispiel ist sicher der Tag „Poweroff“, welcher ausgeschaltete Systeme in der Rackübersicht andersfarbig darstellt, wenn man dem Tag eine andere Farbe zugewiesen hat.
Genau so bekommt man nun ebenfalls die Load balancers ins IP SLB von Racktables. Als erstes legt man also einen Tag an, der jedem Load balancer zugewiesen wird: Configuration ==> Tag tree ==> Edit tree
Nun weißt man dieses Tag dem jeweiligen Load Balancer Object zu.
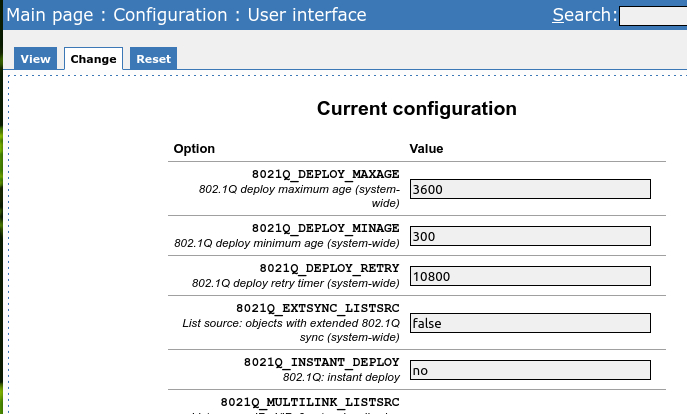
Nun geht es weiter unter Configuration ==> User Interface ==> Change
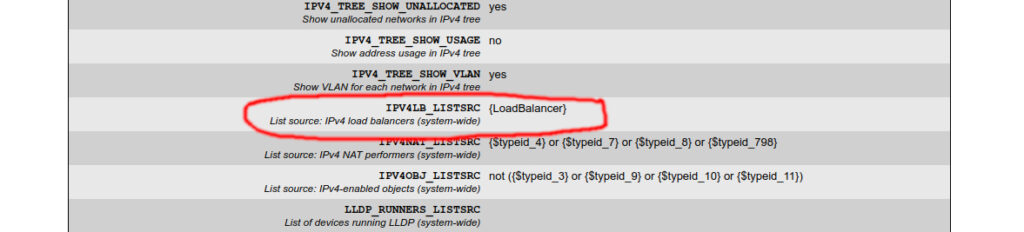
Dort muss die Option IPV4LB_LISTSRC so geändert werden, dass unser neues Tag in geschweiften Klammern steht. In meinem Beispiel ist es das Tag LoadBalancer und dieses findet sich wie folgt in der Konfiguration:
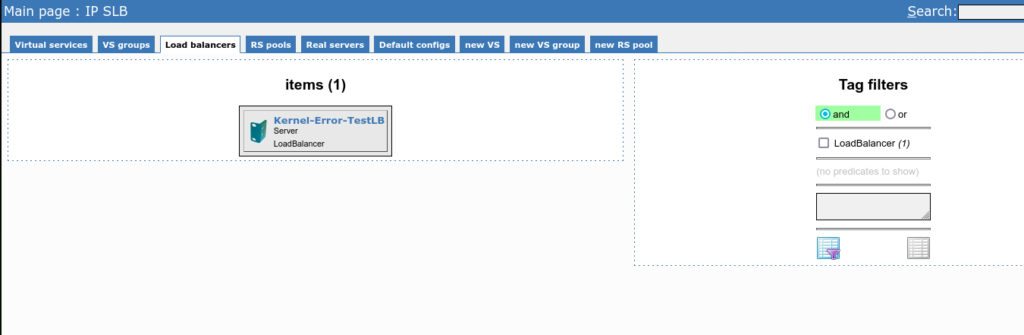
Das war es auch schon. Ab jetzt wird jedes Object unter Racktables ==> IP SLB ==> Load balancers auftauchen, welches das Tag LoadBalancer bekommen hat.
Wenn man es einmal verstanden hat, ganz einfach oder? Viel Spaß.
Für ausführliche Storage-Benchmarks gibt es Tools wie bonnie++ oder fio. Wenn man nur schnell die Read- oder Write-Latency eines Dateisystems prüfen will, reicht ioping — ein einzelner Befehl, Ergebnis in Sekunden.
ioping -s 256k -T 120 -D -c 20 ./
256 KiB <<< ./ (zfs tanksmeer/usr/home): request=1 time=16.0 us (warmup)
256 KiB <<< ./ (zfs tanksmeer/usr/home): request=2 time=35.7 us
256 KiB <<< ./ (zfs tanksmeer/usr/home): request=3 time=45.8 us
...
--- ./ (zfs tanksmeer/usr/home) ioping statistics ---
19 requests completed in 853.7 us, 4.75 MiB read, 22.3 k iops, 5.43 GiB/s
generated 20 requests in 19.0 s, 5 MiB, 1 iops, 269.2 KiB/s
min/avg/max/mdev = 35.7 us / 44.9 us / 52.8 us / 3.85 us
Die Parameter im Detail:
-s 256k — Blockgröße pro Request (hier 256 KiB)
-T 120 — Timeout in Sekunden, Requests die länger brauchen werden ignoriert
-D — Direct I/O, umgeht den Kernel-Cache (misst die echte Disk-Latency)
-c 20 — Anzahl der Requests
./ — Pfad zum Dateisystem das gemessen werden soll
Die Summary am Ende zeigt min/avg/max/mdev — genau wie bei ping. Hier: durchschnittlich 44,9 µs Read-Latency auf einem ZFS-Dataset.
Write-Latency messen
Für die Write-Latency kommt ein einziger Parameter dazu — -W:
ioping -s 256k -T 120 -D -W -c 20 ./
256 KiB >>> ./ (zfs tanksmeer/usr/home): request=1 time=27.0 us (warmup)
256 KiB >>> ./ (zfs tanksmeer/usr/home): request=2 time=54.4 us
256 KiB >>> ./ (zfs tanksmeer/usr/home): request=3 time=60.6 us
...
--- ./ (zfs tanksmeer/usr/home) ioping statistics ---
19 requests completed in 3.86 ms, 4.75 MiB written, 4.93 k iops, 1.20 GiB/s
generated 20 requests in 19.0 s, 5 MiB, 1 iops, 269.5 KiB/s
min/avg/max/mdev = 51.6 us / 202.9 us / 2.65 ms / 577.9 us
Write ist hier erwartungsgemäß langsamer — 202,9 µs im Schnitt gegenüber 44,9 µs beim Lesen. Die höhere Standardabweichung (577,9 µs vs. 3,85 µs) zeigt, dass einzelne Writes deutlich länger dauern können (hier ein Ausreißer mit 2,65 ms — vermutlich ein ZFS Transaction Group Commit).
Weitere nützliche Optionen
# Fortlaufend messen (wie ping ohne -c)
ioping -D ./
# Nur die Summary nach 10 Requests
ioping -D -c 10 -q ./
# Bestimmte Blockgröße (4k für Random I/O)
ioping -s 4k -D -c 20 ./
# Netzlaufwerk / NFS-Mount testen
ioping -D -c 20 /mnt/nfs-share/
Praktisch für einen schnellen Vergleich: Lokale SSD, NFS-Share und USB-Platte mit dem gleichen Befehl messen — die Unterschiede werden sofort sichtbar. Fragen? Einfach melden.
Beim Identiy Server bin ich einfach mal bei https://matrix.org geblieben! Alles ist noch sehr beta. Dafür tut es aber schon ganz ordentlich. Schreiben und Dateien verschicken funktioniert problemlos. Videocalls gehen so mäßig. Das Bild hängt halt immer mal wieder. Einfache Voicecalls klappten dafür richtig gut, sowohl zu zweit als auch in der Konferenz.
Etwas hakelig war das Einfügen von E-Mail Adresse und Rufnummer über den Andoid Client… Das war etwas verwirred. Hier ist der Workflow und die UI auf dem iOS besser. Insg. tut es aber….
Zuletzt habe ich nun den nginx als proxy for den matrix-synapse Server gesetzt. Dem vertraue ich an der Stelle einfach etwas mehr. Oh es läuft in einer FreeBSD 11 jail und dort auch recht Problemlos.
Sobald es mehr zu berichten gibt schreibe ich mehr! Wer es ebenfalls nutzt und mich anschreiben möchte: @kernel:matrix.kernel-error.com
Inzwischen hat ja fast jeder bei uns „schnelles“ Internet…. So lassen sich per E-Mail auch mal etwas größere Dateien verschicken. Dennoch sollte man so ab 5MB ein schlechtes Gefühl haben und sich ab 10MB Anhängen nicht mehr über abgewiesene E-Mails ärgern.
Das Problem mit großen Dateianhängen bei E-Mails ist ja nicht nur die Verstopfung der Leitungen… Mailserver arbeiten sich daran ab, der absendende und empfangende Client ebenfalls. Hängt dann noch ein Virenscanner dazwischen rechnet noch jemand. Dann liegt die Datei auf dem System des Absenders, in dessen Postfach, im Postfach dem Empfängers und natürlich noch auf dem System des Empfängers. Bei einem 500MB Anhang sind das schon mal 2GB für nix.
Inzwischen gibt es 1000 Möglichkeiten um große Dateien schnell und einfach auszutauschen. Selbst ohne seine Daten auf irgendeinen Server bei irgendeinem Anbieter zu legen. So zum Beispiel über owncloud….. Hochladen muss man die Datei ja in jedem Fall zu seinem Mailserver, warum also nicht lieber in die „Cloud“? Ok, es ist etwas aufwendig. Erst hochladen, dann teilen, dann den Link kopieren und in die E-Mail packen, usw. usw…
Für Anwender des Mailclients Thunderbird gibt es in diesem Zusammenhang eine noch schönere Lösung. Sie nennt sich filelink. Im Grunde nichts weiter als eine kleine Funktion, welche dem Anwender etwas Arbeit abnimmt!
Hängt der Anwender eine Datei an seine E-Mail an, welche einen einstellbaren Schwellwert überschreitet, schlägt Thunderbird diesem vor, den Anhang für den Anwender in einen dieser „Austauschservices“ zu laden. Stimmt der Anwender zu, schiebt Thunderbird die Datei hoch und verlinkt sie automatisch in den E-Mail Body. Dieses hält die E-Mai klein und der Empfänger kann selbst entscheiden, ob und wann er den „Anhang“ herunterladen möchte.
Aktuell bringt Thunderbird aus dem Karton leider nur die Verknüpfung zu den bekannten großen Anbietern wie z.B.: dopbox mit. Dort möchte man ja nicht unbedingt seine Daten ablegen. Für owncloud habe ich vor kurzem eine gut funktionierendes Thunderbird Plugin gefunden:
Einfach herunterladen, installieren, zwei drei Kleinigkeiten in der eigenen Cloud einstellen und glücklich sein. Mit zwei/drei erklärenden Sätzen in der E-Mail versteht es zudem fast jeder Empfänger. Noch Fragen?