Mein FreeBSD 15 kommt mit OpenSSH 10.0p2 und OpenSSL 3.5.4.
Beide bringen inzwischen das mit, was man aktuell als quantensichere Kryptografie bezeichnet. Oder genauer gesagt das, was wir Stand heute für ausreichend robust gegen zukünftige Quantenangriffe halten.

Quantensicher? Nein, das hat nichts mit Füßen zu tun, sondern tatsächlich mit den Quanten aus der Physik. Quantencomputer sind eine grundlegend andere Art von Rechnern. Googles aktueller Quantenchip war in diesem Jahr bei bestimmten Physiksimulationen rund 13.000-mal schneller als der derzeit leistungsstärkste klassische Supercomputer. Der chinesische Quantencomputer Jiuzhang wurde bei speziellen Aufgaben sogar als 100 Billionen Mal schneller eingestuft.
Kurz gesagt: Quantencomputer sind bei bestimmten Berechnungen extrem viel schneller als heutige klassische Rechner. Und genau das ist für Kryptografie ein Problem.
Als Vergleich aus der klassischen Welt: Moderne Grafikkarten haben die Zeit zum Knacken von Passwörtern in den letzten Jahren drastisch verkürzt.
- Nur Zahlen: Ein 12-stelliges Passwort wird praktisch sofort geknackt.
- Nur Kleinbuchstaben: wenige Wochen bis Monate.
- Groß- und Kleinschreibung plus Zahlen: etwa 100 bis 300 Jahre.
- Zusätzlich Sonderzeichen: 2025 noch als sehr sicher einzustufen mit geschätzten 226 bis 3.000 Jahren.
Quantencomputer nutzen spezielle Algorithmen wie den Grover-Algorithmus, der die effektive Sicherheit symmetrischer Verfahren halbiert. Ein ausreichend leistungsfähiger Quantencomputer könnte damit die benötigte Zeit drastisch reduzieren. Was heute Jahrhunderte dauert, könnte theoretisch auf Tage oder Stunden schrumpfen.
Stand 2025 sind solche Systeme zwar real und in der Forschung extrem leistungsfähig, werden aber noch nicht flächendeckend zum Brechen realer Kryptosysteme eingesetzt.
Heißt das also alles entspannt bleiben? Jein.
Verschlüsselte Datenträger lassen sich kopieren und für später weglegen. Gleiches gilt für aufgezeichneten verschlüsselten Netzwerkverkehr. Heute kommt man nicht an die Daten heran, aber es ist absehbar, dass das in Zukunft möglich sein könnte. Genau hier setzt quantensichere Kryptografie an. Ziel ist es, auch aufgezeichnete Daten dauerhaft vertraulich zu halten.
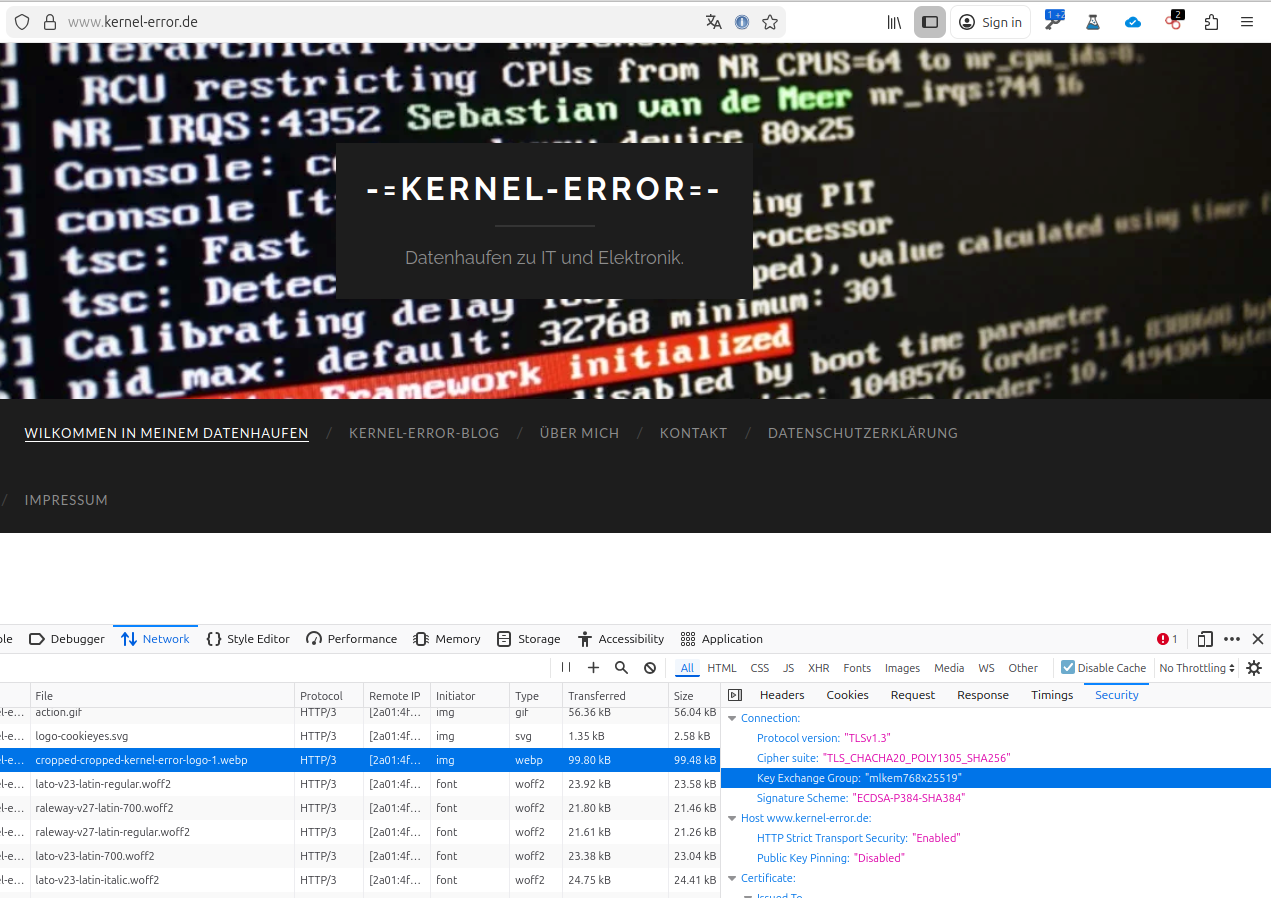
Ein praktisches Beispiel ist der Schlüsselaustausch mlkem768x25519. Wenn ihr diese Seite nicht gerade über Tor lest, ist die Wahrscheinlichkeit hoch, dass euer Browser bereits eine solche hybride, post-quantum-fähige Verbindung nutzt. Im Firefox lässt sich das einfach prüfen über F12, Network, eine Verbindung anklicken, dann Security und dort die Key Exchange Group. Taucht dort mlkem768x25519 auf, ist die Verbindung entsprechend abgesichert. Richtig, auf dem Screenhot seht ihr auch HTTP/3.
Für diese Webseite ist das nicht zwingend nötig. Für SSH-Verbindungen zu Servern aber unter Umständen schon eher. Deshalb zeige ich hier, wie man einen OpenSSH-Server entsprechend konfiguriert.
Ich beziehe mich dabei bewusst nur auf die Kryptografie. Ein echtes SSH-Hardening umfasst deutlich mehr, darum geht es hier aber nicht.
Die zentrale Konfigurationsdatei ist wie üblich: /etc/ssh/sshd_config
Stand Ende 2025 kann ich folgende Konfiguration empfehlen:
KexAlgorithms mlkem768x25519-sha256,sntrup761x25519-sha512@openssh.com,curve25519-sha256,curve25519-sha256@libssh.org,diffie-hellman-group16-sha512,diffie-hellman-group18-sha512,diffie-hellman-group-exchange-sha256 Ciphers chacha20-poly1305@openssh.com,aes256-gcm@openssh.com,aes128-gcm@openssh.com,aes256-ctr,aes192-ctr,aes128-ctr MACs hmac-sha2-256-etm@openssh.com,hmac-sha2-512-etm@openssh.com,umac-128-etm@openssh.com HostKeyAlgorithms ssh-ed25519,ssh-ed25519-cert-v01@openssh.com,sk-ssh-ed25519@openssh.com,sk-ssh-ed25519-cert-v01@openssh.com
Die Zeilen werden entweder an die bestehende Konfiguration angehängt oder ersetzen vorhandene Einträge. Da wir nicht einfach blind kopieren wollen, hier kurz die Erklärung.
Schlüsselaustausch:
Bevorzugt werden hybride Verfahren wie mlkem768 kombiniert mit x25519 sowie sntrup761 kombiniert mit x25519. Diese verbinden klassische elliptische Kryptografie mit post-quantum-resistenten Algorithmen. Damit ist die Verbindung sowohl gegen heutige Angreifer als auch gegen zukünftige Store-now-decrypt-later-Szenarien abgesichert. Curve25519 dient als bewährter Fallback. Klassische Diffie-Hellman-Gruppen sind nur aus Kompatibilitätsgründen enthalten.
Verschlüsselung:
Es werden ausschließlich moderne Algorithmen eingesetzt. Primär kommen AEAD-Ciphers wie ChaCha20-Poly1305 und AES-GCM zum Einsatz, die Vertraulichkeit und Integrität gleichzeitig liefern und bekannte Schwächen älterer Modi vermeiden. Ältere Verfahren wie CBC sind bewusst ausgeschlossen.
Integrität:
Zum Einsatz kommen ausschließlich SHA-2-basierte MACs im Encrypt-then-MAC-Modus. Dadurch werden klassische Angriffe auf SSH wie Padding-Oracles und bestimmte Timing-Leaks wirksam verhindert.
Serveridentität:
Als Hostkey-Algorithmus wird Ed25519 verwendet. Optional auch mit Zertifikaten oder hardwaregestützten Security Keys. Das bietet hohe kryptografische Sicherheit bei überschaubarem Verwaltungsaufwand.
Wichtig: Das funktioniert nur, wenn Server und Client diese Algorithmen auch unterstützen. Wer bereits mit SSH-Keys arbeitet, sollte prüfen, dass es sich um Ed25519-Keys handelt. Andernfalls sperrt man sich im Zweifel selbst aus.
Auf dem Server lässt sich die aktive Konfiguration prüfen mit:
sshd -T | grep -Ei 'kexalgorithms|ciphers|macs|hostkeyalgorithms'
Auf dem Client geht es am einfachsten mit:
ssh -Q kex ssh -Q cipher ssh -Q mac ssh -Q key
So sieht man schnell, welche Algorithmen tatsächlich verfügbar sind.
Zur externen Überprüfung der SSH-Konfiguration kann ich außerdem das Tool ssh-audit empfehlen. Aufruf einfach per:
ssh-audit hostname oder IP -p PORT
Das liefert eine brauchbare Einschätzung der aktiven Kryptografie und möglicher Schwachstellen. Oh, wenn ihr schon dabei seit, vergesst nicht:
- MFA mit Google Authenticator einrichten
- SSH-Hostkey-Verifikation erklärt
- SSH Host Keys in DNS Zone
Hinweis zur Einordnung der Quantensicherheit:
Die hier gezeigte Konfiguration verbessert ausschließlich den Schlüsselaustausch (Key Exchange) durch hybride post-quantum-fähige Verfahren. Hostkeys und Signaturen in OpenSSH basieren weiterhin auf klassischen Algorithmen (z. B. Ed25519 oder ECDSA); standardisierte post-quantum-Signaturalgorithmen sind in OpenSSH aktuell noch nicht implementiert. Es existieren zwar experimentelle Forks (z. B. aus dem Open-Quantum-Safe-Projekt), diese gelten jedoch ausdrücklich nicht als produktionsreif und sind nicht Bestandteil des OpenSSH-Mainlines. Die hier gezeigte Konfiguration ist daher als pragmatischer Übergangsschritt zu verstehen, um „store-now-decrypt-later“-Risiken beim Schlüsselaustausch bereits heute zu reduzieren, ohne auf instabile oder nicht standardisierte Komponenten zu setzen.
Weiterführende Informationen zum aktuellen Stand der post-quantum-Unterstützung in OpenSSH finden sich in der offiziellen Dokumentation: https://www.openssh.com/pq.html
Siehe auch: Post-Quantum TLS für E-Mail — Postfix und Dovecot mit X25519MLKEM768 auf FreeBSD 15, Post-Quantum TLS für Nginx — X25519MLKEM768 auf FreeBSD 15 konfigurieren
Viel Spaß beim Nachbauen. Und wie immer: bei Fragen, fragen.