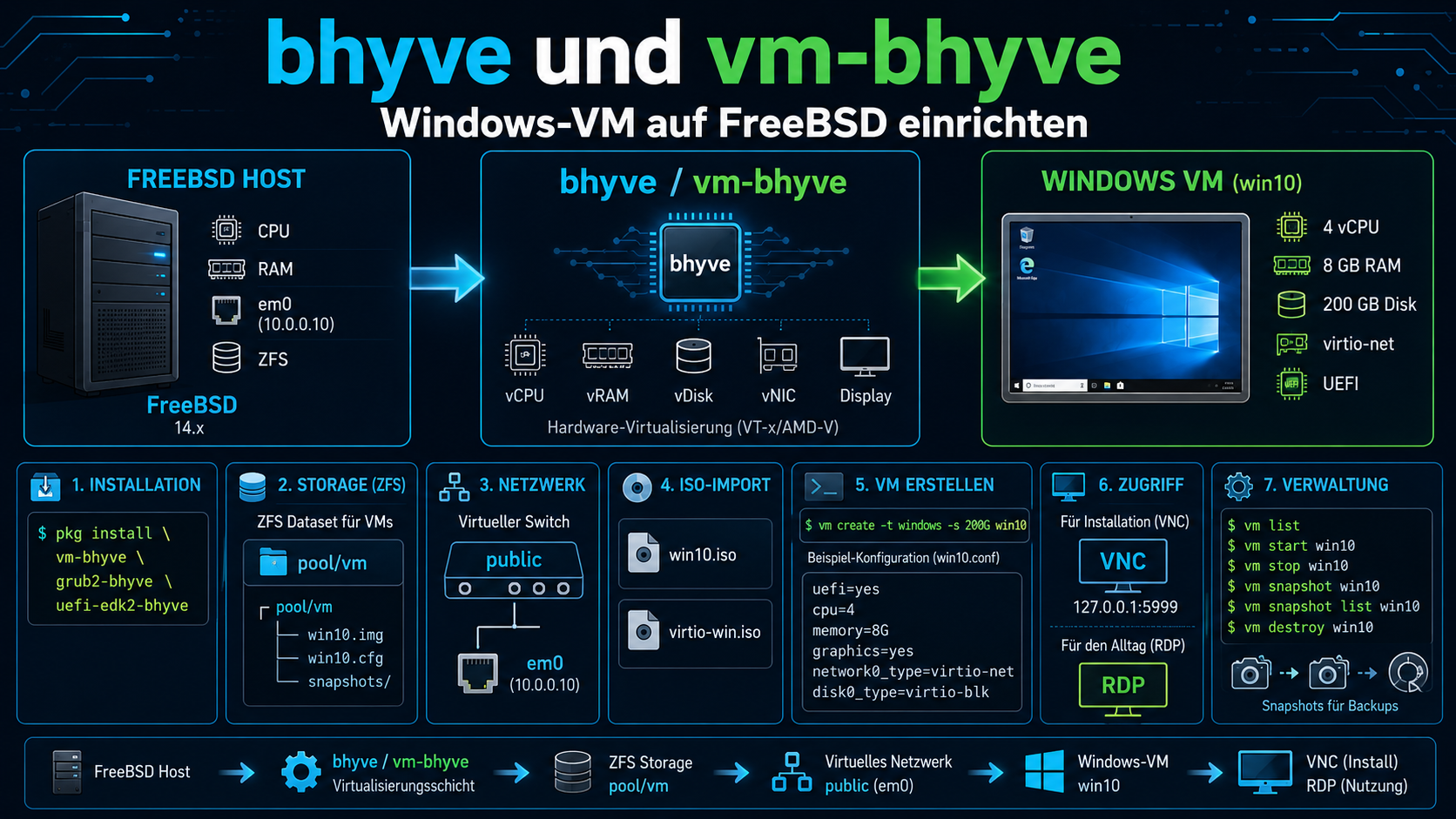
FreeBSD bringt seit Version 10.0 einen eigenen Typ-2-Hypervisor mit: bhyve. Für den täglichen Umgang empfiehlt sich vm-bhyve als Verwaltungstool, damit lässt sich eine Windows-VM in wenigen Minuten einrichten, ohne sich mit den bhyve-Basistools herumschlagen zu müssen.
vm-bhyve installieren und einrichten
# Installation pkg install vm-bhyve grub2-bhyve uefi-edk2-bhyve # ZFS-Dataset für VMs anlegen zfs create pool/vm # Autostart aktivieren sysrc vm_enable="YES" sysrc vm_dir="zfs:pool/vm" # Initialisieren und Templates kopieren vm init cp /usr/local/share/examples/vm-bhyve/* /pool/vm/.templates/ # Netzwerk-Switch erstellen und physisches Interface anhängen vm switch create public vm switch add public em0
Windows-VM erstellen
ISO-Dateien importieren, die Windows-ISO und die virtio-Treiber für die Netzwerkkarte:
# Windows-ISO importieren vm iso /home/kernel/Download/win10.iso # virtio-net Treiber (für die Netzwerkkarte in der VM) fetch https://fedorapeople.org/groups/virt/virtio-win/direct-downloads/stable-virtio/virtio-win.iso vm iso /home/kernel/Download/virtio-win.iso
VM aus dem mitgelieferten Windows-Template erstellen:
vm create -t windows -s 200G win10
VM-Konfiguration anpassen
Das Windows-Template kommt mit 2 CPUs und 2 GB RAM. Für eine brauchbare Windows-VM besser anpassen:
vm configure win10
uefi="yes" cpu=4 memory=8G graphics="yes" graphics_port="5999" graphics_listen="127.0.0.1" graphics_res="1280x1024" graphics_wait="auto" xhci_mouse="yes" network0_type="virtio-net" network0_switch="public" disk0_type="ahci-hd" disk0_name="disk0.img"
Die wichtigsten Optionen: graphics="yes" aktiviert einen VNC-Server für die Grafikausgabe, xhci_mouse="yes" sorgt für eine brauchbare Maus in der VM, network0_type="virtio-net" nutzt den schnelleren paravirtualisierten Netzwerktreiber statt einer emulierten Karte.
Installation und Zugriff
# VM starten und ISO einlegen vm install win10 win10.iso
Dann mit einem VNC-Viewer auf 127.0.0.1:5999 verbinden und Windows installieren. Nach der Installation die virtio-Treiber-ISO einlegen (vm install win10 virtio-win.iso) und Windows die Netzwerktreiber dort suchen lassen.
Für den täglichen Zugriff RDP in der VM aktivieren, dann braucht man den VNC-Viewer nur noch für die Ersteinrichtung.
VM verwalten
# Laufende VMs anzeigen vm list NAME DATASTORE LOADER CPU MEMORY VNC AUTOSTART STATE win10 default uefi 4 8G , No Running (10638) # VM stoppen / starten vm stop win10 vm start win10 # Snapshot erstellen (ZFS-Snapshot der VM-Disk) vm snapshot win10
Details und weitere Optionen im vm-bhyve Wiki. Fragen? Einfach melden.