Alt, tot, überholt, schlecht, nicht nachmachen 🙂
Dieses soll eine kleine Beschreibung über die Gründe, die eigentliche
Installation und Einrichtung meines privaten ProxyServers werden. Also kein HowTo!
Sollte jemand Fragen oder Anregungen haben, freue ich mich natürlich über jede
EMail. Solltest du Fragen stellen achte bitte darauf deine Frage so genau wie irgend
möglich zu stellen. Beschreibe kurz dein Problem, haue mich nicht mit log und configs
zu und habe etwas Geduld. Ich bekomme nicht nur eine EMail am Tag. Darum werde ich ganz
sicher nur auf unfreundliche und ungenaue Fragen antworten. KEINER hat ein Recht drauf von mir
Support zu bekommen!!
Nun, die Situation bei mir schaut ca. so aus: Meine Familie, der Nachbar und ich selbst sitzen
zusammen im Netzwerk. Zu dem kommt immer mal wieder Besuch zu uns. Da wir auch etwas mehr
Platz als der normale Durchschnitt haben, finden auch oft irgendwelche LANs usw. bei uns stat.
Zu dem hängt noch eine Firma und ein geschlossenes WLAN mit drin.
Da ist ein Problem mit der Sicherheit natürlich vorprogrammiert und den überblick kann
man da so einfach auch nicht mehr behalten. Das Netzwerk ist daher in mehrere Bereiche, mit
unterschiedlichen Rechten aufgeteilt worden. Das Netzwerk ist zum Internet hin durch eine Firewall,
Proxy und MTA abgeschirmt. Zu MTA und Firewall sind andere Projektbeschreibungen zu finden.
Die Hauptgründe für die Einrichtung des ProxyServers sind also folgende:
Zentraler check der vom User angeforderten Webseiten auf z.B.: jugendgefährdende Inhalte
Zentraler check der vom User angeforderten Dateien auf Viren
Keine zusätzliche Software auf den Clients
Schneller Zugriff auf oft abgefragte Internetseiten
Mein ProxyServer sollte also folgendes leisten können. Zum einen sollte er die
angeforderten Webseiten auf bestimmte Worte in dessen Text durchsuchen können. Findet er
dort Worte welche nur auf Internetseiten vorkommen sollten welche nicht….. sagen wir mal,
für die tägliche Arbeit am Rechner sinnvoll sind, sollte dieser dann den Zugriff auf
diese Seite verweigern. Bei mir bereits als „bedenkliche“ oder gefährliche Webseiten
bekannte Domains, sollte der Proxy natürlich in jedem Fall den Zugriff verweigern. Es kommt in einem
Netzwerk oft vor, dass ein und die selbe Quelle im Internet mehrmals von verschiedenen Usern angefragt wird.
Warum sollte man also diese Seite für jeden Rechner einmal und vor allem immer wieder aufs Neue vom
Webserver herunterladen? Der ProxyServer sollte also auch in der Lage sein, Webseiten bzw. deren
Inhalte sinnvoll zu cachen. Leider kommen Viren und kleine aber sehr lästige Progämmchen nicht
nur als EMails oder auf Grund von Angriffen ins System, sondern leider auch sehr oft durch unbedachte
Downloads von Dateien der User. Um diese mal wieder vor sich selbst schützen zu können, müssen
alle angeforderten Daten auf Viren und der gleichen getestet werden. Ich selbst habe auf alenl meinen Systemen das
Antivirenprogramm Antivir der Firma H+BEDV Datentechnik GmbH installiert. Ich kann dieses Programm für
Unix, besonders aber für Linux Umgebungen nur empfehlen. Daher ist es logisch, dass ich dieses
Programm am liebsten auch zum Testen der Proxydaten einsetzten möchte. So erspare ich mir die Arbeit
gleich mehrere Virenprogramme zu warten.
Folgendes habe ich mir nun also eingerichtet.
Um sicher zu stellen, dass keine normalen Internetseiten mehr, ohne Zwischenspeicherung, Auswertung und
Virentest bei den User ankommt, habe ich über die Firewall alle direkten Verbindungen auf Port 80
und 21 verboten. Meine Erfahrung hat gezeigt, dass Viren und bedenkliche Webinhalte kaum über
verschlüsselte Seiten (also Port 445) gefunden werden. Diese habe ich auch weiterhin durchgelassen.
Als ProxyServer setze ich das Programm Squid ein. Zur Weitergabe der Daten an den Virenscanner nutze
ich das Programm Squirm. Hier kann ich mir sicher sein, dass alles ohne Probleme zusammenarbeiten wird.
Das eigentliche Scannen der Daten übernimmt, wie schon angedeutet, das Programm Antivir. Das eigentliche
Handling der Daten übernimmt aber das Programm ANDURAS SurfProtect.
Nun aber zur Konfiguration des ganzen!
Beginnen wir mit der Wortfilterung. Um diese zu realisieren und auch ständig erweitern zu können
habe ich mir eine Datei mit dem namen domains.deny im Ordner /etc/squid angelegt. In diese Datei müssen
nun untereinander die Worte geschrieben werden, welche nicht erwünscht sind. Hier ein Auszug aus der Datei:
############ /etc/squid/domains.deny ## Anfang ############
gay
sex
farmsex
nutte
hure
sperma
fotze
arsch
trojaner
hacker
hackertools
crack
keygen
warez
nuke
nuketools
dildo
masturbating
fucking
slut
emule
xmule
edonkey
Kazza
arschficken
spermaschleuder
kindersex
fotzenschleim
############ /etc/squid/domains.deny ## Ende ############
Sollte sich ein User über diese „Einschränkung“ beschweren druckt man am besten die Liste
aus und klärt mit ihm im öffentlichen Gespräch warum er welches Wort denn unbedingt benötigt.
Um dieses nun in den ProxyServer Squid einzubinden muss die Datei vom SquidDeamon gelesen werde können.
Daher sollten noch die Rechte gesetzt werden. Jetzt muss noch folgender Eintrag in die Konfigurationsdatei squid.conf:
acl domains.deny urlpath_regex i "/etc/squid/domains.deny"
acl domains dstdom_regex i "/etc/squid/domains.deny"
http_access deny domains.deny
http_access deny domains
Hier ist aber zu beachten, dass man die Einträge jeweils VOR den anderen acl und http_access Einträgen in
der Konfigurationsdatei schreibt, da diese von oben nach unten abgearbeitet werden.
Nach dem Speichern sollte man nun Squid die neue Konfiguration „einprügeln“:
squid -k reconfigure
[als root in der Konsole]
Erledigt das für uns.
Die acl und http_access Regeln sind in der Konfigurationsdatei ganz gut beschrieben. Daher gehe ich da nicht weiter
drauf ein. Da wir aber gerade bei der Konfigurationsdatei sind… Einige Einträge können wir gleich noch machen.
Dazu gehen wir ganz an das Ende der Datei. Dort tragen wir folgendes ein:
http_port 192.168.100.1:3128
http_port 127.0.0.1:3128
cache_effective_user squid
cache_effective_group squid
visible_hostname router
unique_hostname router
cache_dir ufs /home/spool/squid 1000 16 256
cache_mgr kernelerror@kernelerror.de
emulate_httpd_log off
cache_mem 16 MB
ftp_user root@kernelerror.de
Jetzt müssen wir uns kurz vergewissern ob wir hiermit nicht gerade doppelte Einträge gemacht haben. Also schauen
wir die Konfigurationsdatei durch, ob die einzelnen Einträge nicht schon irgendwo existieren. Interessant ist
natürlich nur der erste Teil.
Unsere Einträge bewirken folgendes:
http_port 192.168.100.1:3128
http_port 127.0.0.1:3128
Hier werden die lokalen IP Adressen und Portnummern fest gelegt auf denen Squid lauschen soll. Die Adresse 127…
bla ist für den localhost, die Adresse 192.168.100.1 ist für die dritte NIC in meinem ProxyServer
gedacht. Der TCP Port ist jeweils 3128. Wenn man all diese Einstellungen nicht setzt lauscht Squid normalerweise
auf Port 8080, dieses aber auf jeder NIC im System.
cache_effective_user squid
cache_effective_group squid
Hier wird der Username und die Gruppe festgelegt mit welchem Squid die Dateien und Ordner in seinem Cache verarbeitet.
visible_hostname router
unique_hostname router
Hier gebe ich den Computernamen an, welcher dem User angezeigt werden soll.
cache_dir ufs /home/spool/squid 1000 16 256
Hier wird nun angegeben wo genau Squid seine Daten zwischenspeichern soll. Die weitern Angaben sind die maximale
Grösse des Caches in MB, die maximale Anzahl von Ordnern in einem Ordner und die maximale Anzahl von Unterordnern
im Cache. Squid läuft bei mir nun schon seit 4 Jahren. In dieser Zeit habe ich herausgefunden, dass er mit
diesen Einstellungen schnell und stabil läuft. Auf anderen Rechnern mit anderem Dateisystem usw. kann das
natürlich auch anders aussehen. Wieder mal so eine Sache wo man etwas probieren muss.
cache_mgr kernel-error@kernel-error.de
Sollte Squid eine Seite nicht finden, den Zugriff verweigern oder sonst etwas. Sagt er dem User er könne
sich mit seinen Problemen und Sorgen an diese EMail Adresse wenden. Will man möglichst wenig genervt
werden sollte man diese dann gegen /dev/null linken 🙂
emulate_httpd_log off
Squid legt natürlich Logdateien an. Leider formatiert squid die standardmässig so, dass kein Mensch
diese lesen kann. Mit dieser Einstellung kann man Squid aber dazu überreden diese lesbar darzustellen.
cache_mem 16 MB
Diese Einstellung sagt Squid wie viel Arbeitsspeicher er sich maximal unter den Nagel reissen darf. Ich habe
256 MB in diesem System verbaut. Mit 16 MB für den Squid läuft das Teil immer noch schön rund
und Squid kommt auch nicht aus der Puste.
ftp_user root@kernelerror.de
Wird über Squid auf einen FTPServer zugegriffen gibt er diese EMailadresse an. Ob das nötig
ist oder nicht muss man selbst entscheiden.
Nun sollte Squid normalerweise laufen und die Webseiten nach Worten filtern. Sollte noch nicht klar
sein, wie man gleich ganze Domains sperrt, sollte man sich noch mal mit dem Punkt ACLs beschäftigen. Im
Notfall antworte ich auch auf EMails. Tja, jetzt fehlt uns nur noch der Virenscanner, richtig?
Das Programm ANDURAS SurfProtect funktioniert folgendermassen. Wenn man im Internet surft laufen nun ja alle
Daten durch den Proxy. Dieser gibt bestimmte Dateitypen nun über Squirm weiter an SurfProtect. SurfProtect
ist selbst ein PHP Programm welches auf dem lokalen Webserver (es könnte theoretisch auch auf einem anderen
System laufen) läuft. Squirm gibt nun also die Anforderung der Datei virus.exe, von der Internetseite www.virus.com,
weiter an SurfProtect. Dieses öffnet nun ein Popupfenster auf dem Rechner des Users im welchem ihm mitgeteilt wird,
dass er kurz warten soll. Saugt dann die Datei Virus.exe von der angegebenen Quelle und speichert sie im Temp
zwischen. Nun checkt es mit dem Programm Antivir ob die Datei virenverseucht ist oder nicht. Ist sie es, wird dem
User der Zugriff auf diese Datei verwehrt (Bild 1) und diese dann gelöscht. Anderweitig wird dem User gesagt, die Datei
ist virenfrei und kann jetzt mit einem klick auf „Speichern“ abgespeichert werden (Bild 2). SurfProtect speichert
die Datei nun einen Tag lang zwischen, schaut aber bei jeder neuen Anfrage erst nach ob nicht vielleicht die Datei
auf der Quelle verändert wurde. So muss die Datei nicht bei jeder Anfrage neu heruntergeladen werden.
Um die Daten nun mit der Hilfe von Squirm weiter zu reichen muss folgendes in dessen Konfigurationsdatei eingetragen werden:
abortregexi (^http://192.168.0.200/+surfprot/+surfprot\.php.*$)
# rules to redirect certain files to SurfProtect...
regexi (^.*\.zip$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.zip\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.doc$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.doc\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.exe$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.exe\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.gz$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.gz\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.tar$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.tar\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.com$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.com\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.bat$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.bat\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.scr$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.scr\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.rar$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.rar\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.cmd$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.cmd\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.reg$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.reg\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
# Skip all local files
abortregexi (^http://192\.168\.0\.1\.*)
abortregexi (^http://192.168.0.200.*)
Schaut etwas wüst aus? Ist es aber nicht 🙂
regexi (^.*\.reg$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
regexi (^.*\.reg\?.*$) http://192.168.0.200/surfprotect/surfprot.php?url=|\1
Dieser Eintrag sagt: Alle Dateien mit der Endung reg sollten an http://192.168.0.200/surfprotect/surfprot.php?url=
weitergereicht werden. Tja, das ist auch schon alles. Man muss also nur für jede Datei die man scannen will so
einen Eintrag anlegen.
SurfProtect selbst liegt im Ordner /surfprotect unter dem Ordner html im wwwTeil des Apache.
Dort liegen auch die Konfigurationsdateien. Ob man den Zugriff auf diese gewehrt oder nicht, ist einem selbst und den
Einstellungen des Apache überlassen. Die User könnten diese zwar nur lesen aber noch nicht mal mehr das
geht sie ja etwas an. Daher sollte man nur den Zugriff auf die Datei surfprot.php genehmigen.
In der Datei surfport.defaults sollte man nun noch unten folgendes eintragen:
define(SCANNER_INCLUDE, "surfprot_hbac.inc");
Damit wird SurfPortect gesagt es soll das Plugin zur Verwendung des Programmes AntiVir laden.
Damit sollte der Proxy nun auch nach Viren suchen.
Hier nun noch zwei Bilder, welche der User zu sehen bekommt. Das, was sich nun für die User ändert:
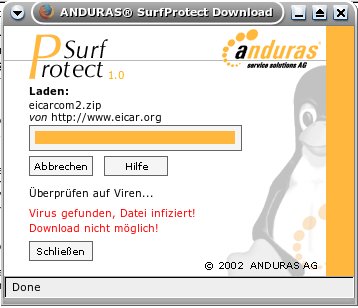
SurfProtect verweigert den Zugriff.
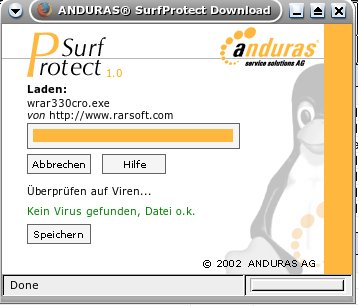
SurfProtect erlaubt den Zugriff.