GeoTagging mit dem i-gatU GT200e Gentoo Linux und Digikam…
Ich habe von meiner Frau einen GPS Datenlogger zum Geburtstag geschenkt bekommen. Damit hat sie mir auch direkt meinen Wunsch nach so einem Gerät erfüllt. Danke.
Allen jenen welche durch eine Suche auf diesen Beitrag gestoßen sind muss ich wohl kaum erzählen was und zu welchem Zweck man dieses kleine Gerät einsetzten kann. Besitzer eines Smartphones werden wohl meist auch nur müde lächeln. Daher reiße ich nur kurz an, was ich mit dem Teil möchte.
Angeschlossen und geladen wird der GT-200e von i-gatU per USB. Ich habe zusätzlich die Möglichkeit das Gerät per Bluetooth zu verbinden. So zum Beispiel mit meinem Nokia Mobiltelefon (ja, vielleicht kaufe ich irgendwann mal etwas neuers). Kismet auf meinem Notebook oder oder oder….
Die aktuelle GPS Position kann mit dem Gerät per Knopfdruck oder je nach Einstellung automatisch im Intervall gespeichert werden. Da ein Akku verbaut ist kann es dieses komplett als Stand-Alone Gerät. Genau dieses ist mein Hauptplan…. Ich packe es einfach in meine Tasche oder befästige es an meiner Spiegelreflexkamera und/oder Digitalkamera und lasse es einfach mitlaufen. Die Akkulaufzeit reichte bei mir schon für 3 Tage, dann habe ich aufgehört zu testen.
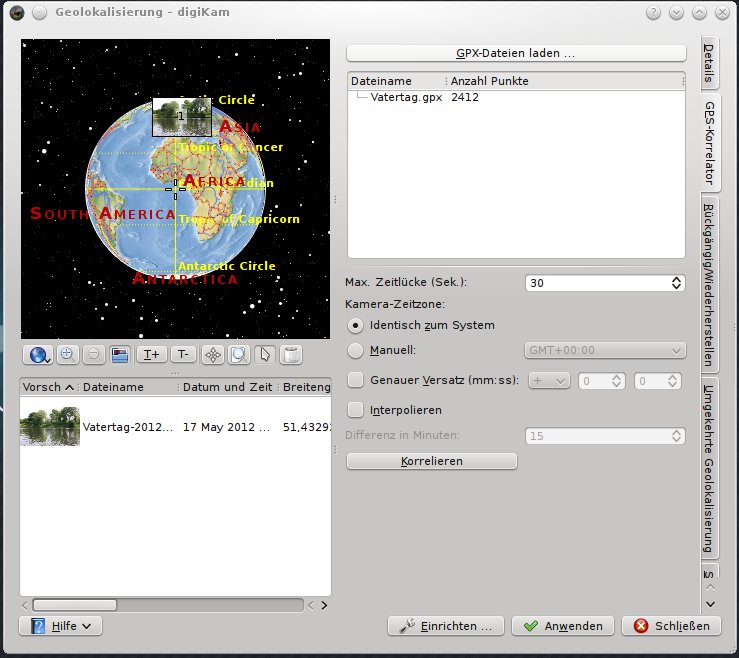
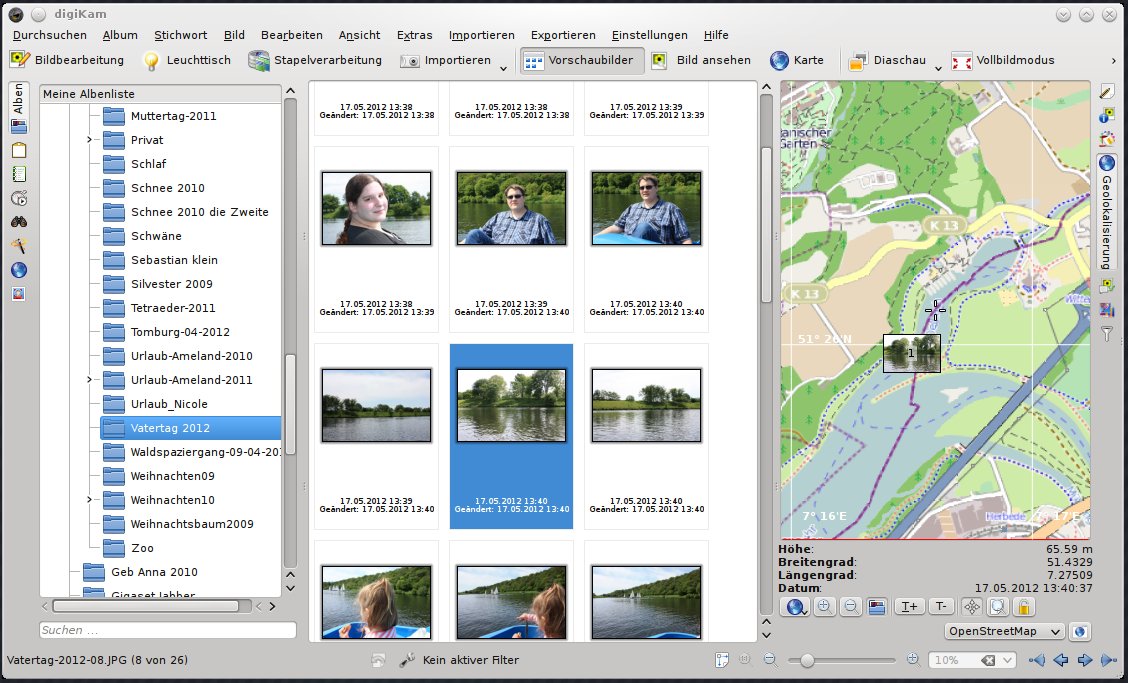
Dieses kleine Ding hängt nun also an meiner Canon EOS 450D und schreibt alle paar Sekunden meinen genauen Standort auf. Zuhause kann ich nun diese Daten vom Gerät als GPX Datei auslesen und zusammen mit meiner Bilderverwaltungssoftware Digikam, die Bilder meiner Kamera mit den GPS Koordinaten vermischen. Somit ist in den Metadaten jedes Bildes gespeichert an welcher Position genau ich es aufgenommen habe.
Natürlich lässt sich anhand der Wegpunkte die genaue Strecke, Geschwindigkeit, Höhe usw… Errechnen und in lustige Grafiken gießen. Dieses ist für mich dass Abfallprodukt.
Wie so oft reicht es auch i-gatU sich hinsichtlich Treiber- und Softwareunterstützung um die Microsoft Windows und Apple MacOS Benutzer zu kümmern. Linux Benutzer müssen sich halt selbst irgendwie kümmern und das haben sie getan. Es gibt das Progrämmchen igotu2gpx der Linux Kernel kommt ab Versionen größer 2.6.3 problemlos mit dem Gerät zurecht.
Um igotu2gpx kompilieren zu können sind im groben folgende Abhängigkeiten zu erfüllen:
– qt4
– boost
– libusb
– chrpath
– marble
– openssl
Dieses sollte sich auf jeder gängigen Distribution durch den Paketmanager erledigen lassen. Unterwegs kümmert sich nun der GT200e um die genaue Positionsbestimmung. Zuhause kann ich dann die Wegpunkte mit igotu2gpx in eine gpx Datei exportieren. Digikam verbindet dann die Bilder mit der passenden GPS Position. Dieses funktioniert über die Uhrzeit. Die Kamera hängt beim Knipsen eines Bildes automatisch die Uhrzeit an das Bild. Diese kann nun mit den Zeiten aus dem gpx Export verglichen werden. So lässt sich herausfinden an welcher Position man gerade beim Knipsen des Bildes gewesen ist. Vorausgesetzt die Kamera hat auch die richtige Uhrzeit und das richtige Datum.
Ich bin nur sehr selten an einem Ort, an welchem ich keine Internetverbindung nutzen kann. Noch seltener würde ich genau dann eine Internetverbindung benötigen. Wenn es dann aber so ist, dann benötige ich sie wirklich!
Nun komme ich in der letzten Zeit immer mal wieder an diese Stelle und ärgere mich. Oft ist zwar ein Kollege oder Bekannter in der Nähe, mit so einem feinen Android Mobiltelefon, nur hilft mir dieses beim Arbeiten auf einer SSH-Shell weniger. Ja, es geht aber wirkliches Arbeiten geht nicht… Zudem bin ich ein Mensch der seinen Windowmanager benutzt, sprich viele offene Fenster. Auf so einem kleinen Mobilding ist mir mehr als eine kurze E-Mail oder etwas Google klicker klacker einfach zu aufwändig.
Das Handy also als Modem mit dem Rechner verbinden? So selten wie ich es im Moment benötige, mich direkt 1 Jahr an einen 20€/Monat Tarif meines Anbieters zu binden? Ne, so geht das nicht….
Vor kurzem war ich nun im Blödmarkt unterwegs. Da lagen in der Grabbelkiste so 15 Euronen O2 Prepaid USB-Sticks.
Dem etwas überforderten Fachberater für die Dinger konnte ich mit etwas Mühe die Information entlocken, dass ich über dieses Angebot „echtes“ Internet erhalte. Damit ist gemeint, dass ich SSH-Sessions auf beliebigen Ports öffnen kann und auch mein IPv6 Tunnelbroker funktionieren sollte. ….Nebenbei, habt ihr im Blödmarkt mal gefragt ob ihr über was auch immer eine Verbindung zu einen IPv6 Tunnelbroker aufbauen könnt? Macht mal, ist lustig.
HTTP / SMTP / IMAP mit und ohne SSL/TLS alles kein Problem!
Mit der 5 Tage x 3,50€ = 17,50€ Sollte einem Test nichts im Wege stehen. Keine Grundgebühr oder sonstige laufenden Kosten… Ich brauche es nicht, ich zahle es nicht. Wenn ich also feststelle das ich es doch oft und gut nutze, so dass sich einer der Knebelverträge des Anbieters meines Vertrauens lohnen würde, dann kann ich das Teil wegwerfen und mich bewusst knebeln lassen. Anderweitig habe ich eine tolle Lösung für den Notfall!
Beim Kauf habe ich jetzt nicht darauf geachtet ob das Teil nun unter bzw. mit meinem Linux (Gentoo) zusammenarbeitet. Den Fachberater im Blödmarkt wollte ich es nun nicht noch fragen, er schien jetzt schon von mir genervt zu sein!
Hey, gut wie ich bin, bekomme ich das Teil schon zum rennen (Boar ist diese Selbstüberschätzung nicht wiederlich?)!
Da meine Frau etwas von: „Rausgeworfenes Geld…. Überflüssiges Spielzeug… und du sitzt eh viel zu viel vor dem Computer!“ murmelte…. _MUSS_ das Teil einfach Laufen.
Tut es nur so ~out of the box~ nicht! Dass hat man nun also davon, man kauft im Blödmarkt halt nichts. Vor allem nicht ohne Verstand, oder gerade deswegen? Wie auch immer, so haben ich es ans Laufen bekommen!
Ich habe hier also den O2 Surfstick MF190 von der Firma ZTE.
Stecke ich diesen einfach in mein System ein und schaue mir an was der Kernel dazu sagt, sehe ich folgendes:
$ dmesg
usb 2-1: new high speed USB device using ehci_hcd and address 3
usb 2-1: New USB device found, idVendor=19d2, idProduct=0083
usb 2-1: New USB device strings: Mfr=3, Product=2, SerialNumber=4
usb 2-1: Product: ZTE WCDMA Technologies MSM
usb 2-1: Manufacturer: ZTE,Incorporated
usb 2-1: SerialNumber: P671A2TMED010000
scsi7 : usb-storage 2-1:1.0
scsi 7:0:0:0: CD-ROM ZTE USB SCSI CD-ROM 2.31 PQ: 0 ANSI: 2
sr1: scsi-1 drive
sr 7:0:0:0: Attached scsi CD-ROM sr1
sr 7:0:0:0: Attached scsi generic sg2 type 5
Der Stick wird also als USB-CDROM Laufwerk (hier liegt die Software für die Windows User) und USB-Festplatte (sofern eine MicroSD-Karte eingelegt ist, wäre es diese) erkannt.
Mal schauen was ein lsusb sagt:
$ lsusb
Bus 002 Device 004: ID 19d2:0083 ONDA Communication S.p.A
19d2 steht für den Hersteller und 0083 für das Gerät selbst. Google sagt 0083 ist der Stick aber im Modus (ich nenne es mal) Datenlaufwerk. Ich will aber Modem 🙂 Hierzu sagt Google man muss ein paar bestimmte Kommandos schicken und schon wechselt der USB-Stick seinen Modus. Findige Leute haben sich da schon einen Kopf zu gemacht und das Programm: usb_modeswitch geschrieben. Also soll emerge mal loslegen:
$ emerge usb_modeswitch
Solange er rechnet könnte ich meinen Kernel ja schon mal davon überzeugen das Gerät zu „ignorieren“. Dazu füge ich in die Datei: /usr/src/linux/drivers/usb/storage/unusual_devs.h folgende Zeilen ein:
Damit Geräte dieser Art überhaupt funktionieren können (und ich nach der Änderung in unusual_devs.h ja eh neu kompilieren muss) sollte die Kernelkonfiguration wie folgt angepasst werden:
Device Drivers ->
USB support --->
<M> OHCI HCD support (If not use Intel or VIA chipset)
<M> UHCI HCD (most Intel and VIA) support (If use Intel or VIA chipset)
<M> USB Serial Converter support --->
[*] USB Generic Serial Driver
<M> USB driver for GSM and CDMA modems
Network device support --->
<*> PPP (point-to-point protocol) support
<*> PPP support for async serial ports
Inzwischen ist usb_modeswitch fertig. Für meinen Stick muss ich leider noch etwas Handarbeit leisten. Denn in der Datei /lib/udev/rules.d/40-usb_modeswitch.rules müssen noch folgende Zeilen hinzugefügt werden:
Damit die neue Regel zur Anwendung kommen noch schnell ein:
$ udevadm control --reload-rules
Jetzt sollte es beim Einstecken vom Stick schon anders aussehen….
$ dmesg
usb 2-1: new high speed USB device using ehci_hcd and address 4
usb 2-1: New USB device found, idVendor=19d2, idProduct=0117
usb 2-1: New USB device strings: Mfr=3, Product=2, SerialNumber=4
usb 2-1: Product: ZTE WCDMA Technologies MSM
usb 2-1: Manufacturer: ZTE,Incorporated
usb 2-1: SerialNumber: P671A2TMED010000
usb-storage 2-1:1.0: device ignored
usb-storage 2-1:1.1: device ignored
usb-storage 2-1:1.2: device ignored
usb-storage 2-1:1.3: device ignored
usbcore: registered new interface driver usbserial
USB Serial support registered for generic
usbcore: registered new interface driver usbserial_generic
usbserial: USB Serial Driver core
USB Serial support registered for GSM modem (1-port)
option 2-1:1.0: GSM modem (1-port) converter detected
usb 2-1: GSM modem (1-port) converter now attached to ttyUSB0
option 2-1:1.1: GSM modem (1-port) converter detected
usb 2-1: GSM modem (1-port) converter now attached to ttyUSB1
option 2-1:1.2: GSM modem (1-port) converter detected
usb 2-1: GSM modem (1-port) converter now attached to ttyUSB2
usbcore: registered new interface driver option
option: v0.7.2:USB Driver for GSM modems
Wohooo ein GSM Modem. Was sagt lsusb?
$ lsusb
Bus 002 Device 004: ID 19d2:0117 ONDA Communication S.p.A.
OK, der Stick wird nun also als Modem erkannt, die Datenlaufwerke werden ignoriert und ich könnte mich ja mal um eine Interneteinwahl kümmern, oder? Nötig ist dafür ppp und (weil es so schön einfach ist) wvdial. Emerge muss das wieder für mich erledigen:
$ emerge ppp wvdial
Nach kurzer Zeit ist er fertig. Nun lege ich mal das ppp Device an:
$ mknod /dev/ppp c 108 0
*umschau* ich habe ja so ein paar Tests hinter mir und Scripte können da knallhart sein. Wenn man denen sagt: „Probiere mal bis geht…“ Dann tun die das auch wenn sie 100 mal die falsche PIN eingeben. Man kann lange suchen bis man darauf kommt die PUK einzugeben. SEHR lange. Ich habe also die PIN-Eingabe abgeschaltet!
wvdial ist schnell konfiguriert. Meine Konfiguration für O2 schaut so aus:
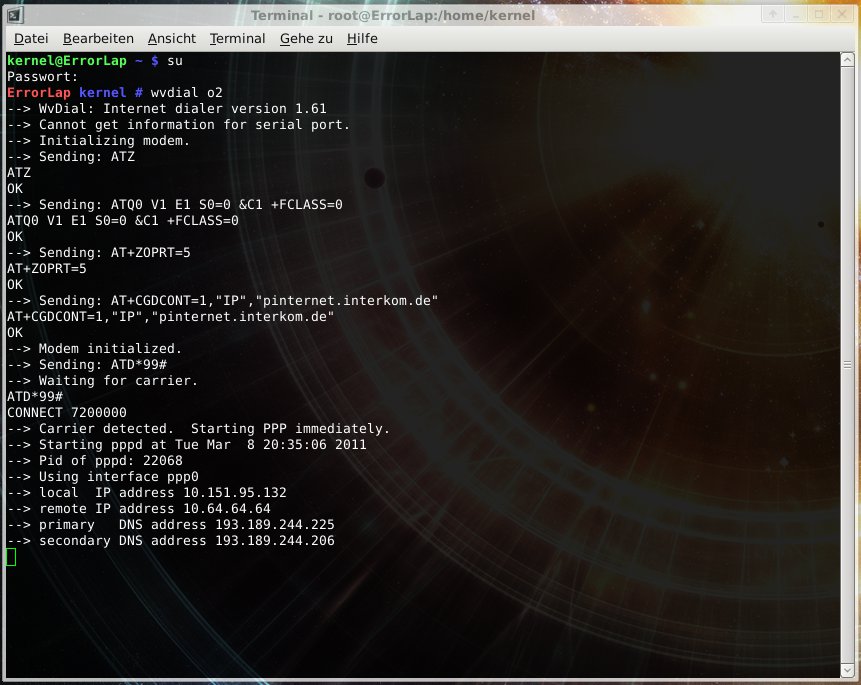
Stecke ich nun meinen (mit abgeschalteter PIN-Eingabe) Surfstick ins Notebook beginnt er rot zu leuchten. Ist der Stick betriebsbereit und hat Netz beginnt er grün zu leuchten 🙂 Einfach, oder?
Die Einwahl funktioniert nun recht einfach mit wvdial:
$ wvdial o2
--> WvDial: Internet dialer version 1.61
--> Cannot get information for serial port.
--> Initializing modem.
--> Sending: ATZ
ATZ
OK
--> Sending: ATQ0 V1 E1 S0=0 &C1 +FCLASS=0
ATQ0 V1 E1 S0=0 &C1 +FCLASS=0
OK
--> Sending: AT+ZOPRT=5
AT+ZOPRT=5
OK
--> Sending: AT+CGDCONT=1,"IP","pinternet.interkom.de"
AT+CGDCONT=1,"IP","pinternet.interkom.de"
OK
--> Modem initialized.
--> Sending: ATD*99#
--> Waiting for carrier.
ATD*99#
CONNECT 7200000
--> Carrier detected. Starting PPP immediately.
--> Starting pppd at Tue Mar 8 20:35:06 2011
--> Pid of pppd: 22068
--> Using interface ppp0
--> local IP address 10.151.95.132
--> remote IP address 10.64.64.64
--> primary DNS address 193.189.244.225
--> secondary DNS address 193.189.244.206
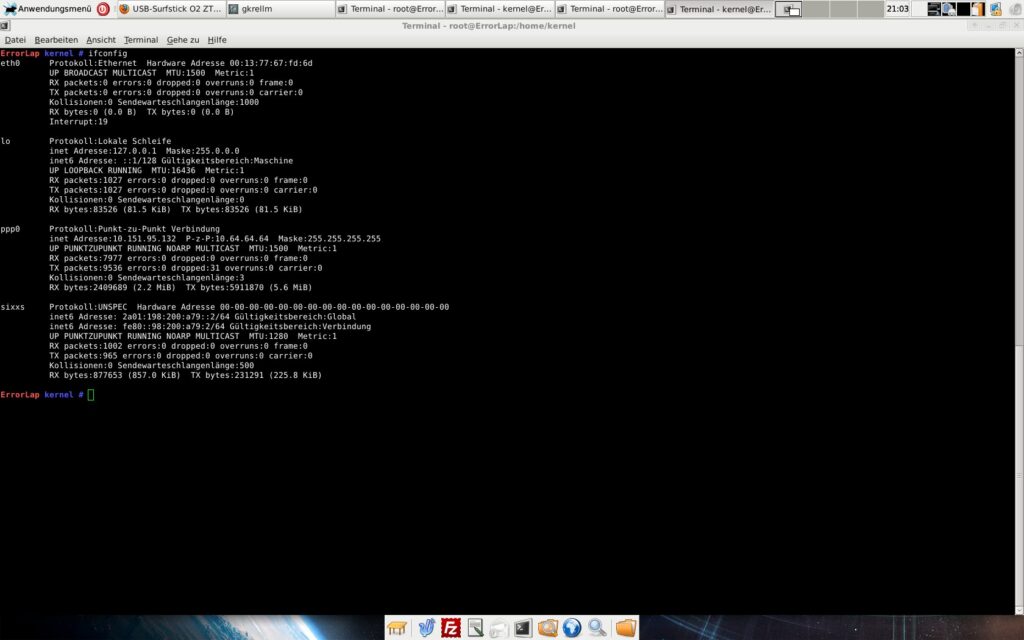
Nun sollte man auch schon online sein. Ein kurzer Blick auf die Interfacekonfiguration zeigt:
Ich wollte wissen, wie gut sich Daten mit Linux-Bordmitteln wiederherstellen lassen. Also habe ich eine alte Festplatte genommen und es systematisch ausprobiert. Erst normal gelöschte Dateien, dann ein RAW-Image, und am Ende habe ich die Platte physisch zerstört, um zu sehen was ddrescue und PhotoRec aus den Trümmern holen.
Vorbereitung: Testplatte befüllen
Die älteste funktionierende Platte aus meinem Fundus: eine WD Expert 136BA. Erst komplett mit Nullen überschrieben, dann partitioniert und als NTFS formatiert:
Die Optionen: -u für Undelete-Modus, -m '*.*' für alle Dateien (mit -m '*.doc' könnte man nur Word-Dateien holen), -p 100 für nur zu 100 % wiederherstellbare Dateien, -d /test als Zielverzeichnis. Bei Bildern könnte man den Prozentsatz auch niedriger setzen, Teile eines JPEG sind besser als nichts.
Alle 154 Dateien kamen vollständig zurück. Einzige Einschränkung: Dateien mit gleichem Namen werden nicht überschrieben. Sollte man beachten oder per Script lösen.
Arbeiten mit RAW-Images
Im Ernstfall arbeitet man nie mit der Originalplatte. Sobald man den Datenverlust bemerkt, am besten sofort den Stecker ziehen. Jeder weitere Betrieb, selbst ein Herunterfahren, kann die gelöschten Daten überschreiben. Also erst ein RAW-Image ziehen:
ntfsundelete funktioniert genauso mit dem Image-File. Gleiche Ergebnisse, gleiche Wiederherstellung. Genau so soll es sein.
Die Festplatte zerstören
Jetzt wird es interessant. Mich hat natürlich interessiert, was bei einer physisch beschädigten Platte passiert. Also Platte wieder voll gemacht und dann aufgeschraubt.
Vorsichtig ein paar Kratzer mit dem Schraubendreher auf die Magnetscheiben gesetzt. Nicht zu viel, aber genug, dass einige Gigabyte unlesbar sein sollten.
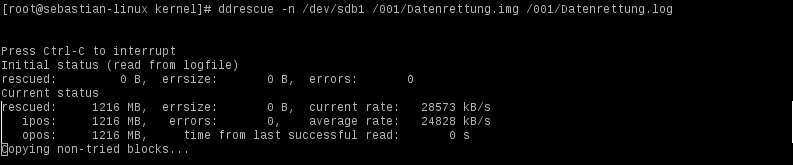
ddrescue: 52 Stunden an einer zerkratzten Platte
Platte wieder zugeschraubt und ddrescue drauf losgelassen:
Nach meiner kleinen Kratzorgie hat ddrescue 52 Stunden an der Platte gefummelt, bevor es durch war.
Wann zum Profi?
Wenn einem die Daten mehr als 3.000 Euro wert sind, sollte man einen professionellen Datenretter aufsuchen. Die nehmen zur Diagnose oft um die 90 Euro und sagen dann, was es wirklich kostet. Bei einem Fall aus 2010 hat ein Kunde mit einer 160 GB HDD und Headcrash einen Kostenrahmen von 15.000 bis 18.000 Euro genannt bekommen. Jede Bewegung an der Platte kann weitere Daten zerstören.
Ich habe selbst mal bei einer Seagate SCSI-Platte die komplette Elektronik von einer baugleichen getauscht, weil sie keinen Spin-Up mehr machte. Lief danach wieder, als wäre nie etwas gewesen. Auch ein Tausch der Schreib-/Leseköpfe hat einmal funktioniert, nachdem einer halb abgerissen war. Die Platte sprang genau ein Mal an, ich konnte sichern, beim nächsten Versuch ging nichts mehr. Solche Experimente klappen nicht immer. Hat man an der Platte herumgefummelt, hat oft auch der Profi keine Chance mehr.
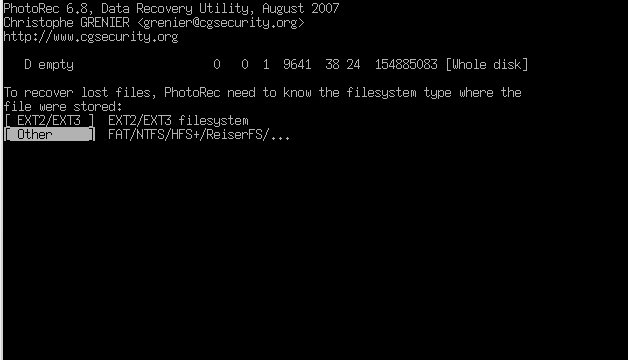
PhotoRec: Dateien anhand des Headers retten
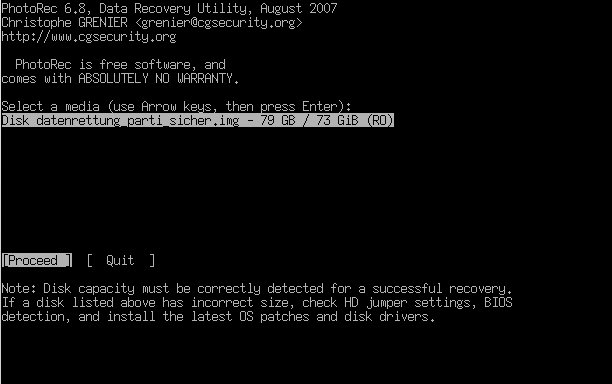
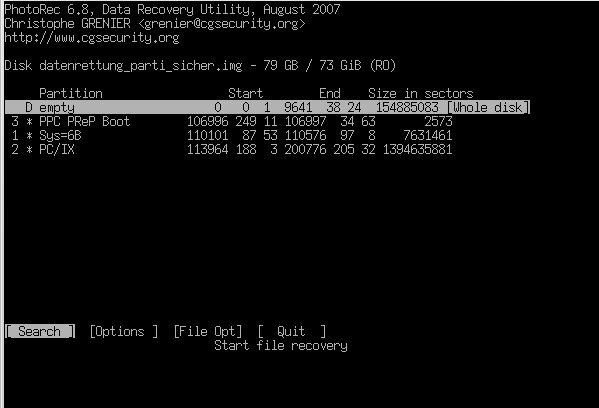
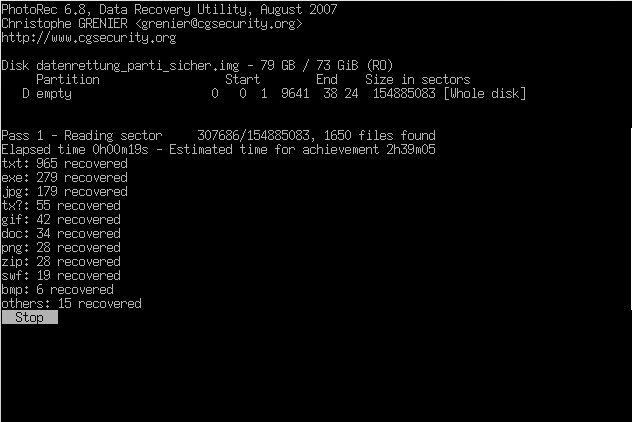
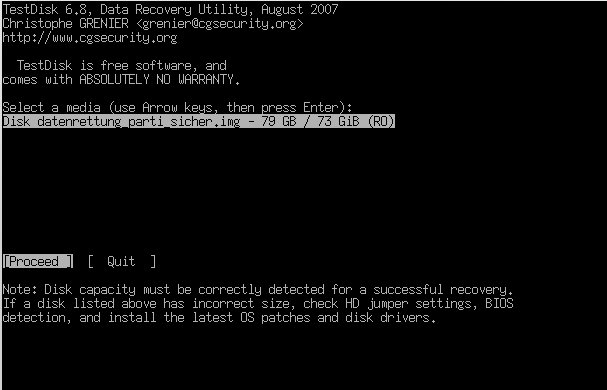
Das ddrescue-Image ließ sich in meinem Fall nicht mehr mounten. Durch die Kratzer war auch das NTFS-Dateisystem total im Eimer, selbst fsck half nicht. Also brauchte ich ein Programm, das Dateien anhand ihres Headers wiederherstellen kann: PhotoRec.
photorec datenrettung_parti_sicher.img
PhotoRec hat erstaunlich viele Dateien aus der zerkratzten Platte zurückgeholt. Wer sich das Programm anschaut, sollte sich auch TestDisk vom gleichen Entwickler ansehen. Damit lassen sich gelöschte Partitionen rekonstruieren und noch vieles mehr.
Update 2026: Was bei SSDs und NVMe anders ist
Der Beitrag oben ist von 2010 und das merkt man. Die meisten Endgeräte haben heute keine drehende Festplatte mehr, sondern eine SSD oder NVMe. Das ändert das Spiel komplett.
Sobald TRIM oder UNMAP aktiv sind, meldet das Dateisystem dem Controller, welche Blöcke nach einem DELETE freigegeben sind. Der Controller löscht diese Zellen oft sofort oder beim nächsten Garbage-Collection-Lauf. Ergebnis: ntfsundelete oder PhotoRec laufen ins Leere, weil die Daten physisch schon weg sind. Wer ein Recovery-Tool an einer SSD ansetzt, sollte das Laufwerk vorher per Software-Hardware-Befehl ruhigstellen, also nicht mounten und keine TRIM-Befehle mehr absetzen lassen.
NVMe legt noch eine Schaufel drauf. Mit nvme sanitize oder nvme format --ses=1 ist nach Sekunden alles weg, kryptografisch sauber. Das ist gut für Hardware-Verkauf oder -Entsorgung, ein Albtraum für Recovery.
Verschlüsselte Datenträger sind ein eigenes Kapitel. BitLocker, LUKS, FileVault, APFS-Encryption: ohne den Schlüssel oder das Recovery-Passwort hilft kein Tool der Welt. Bei einem PCB-Defekt einer SSD wird es zusätzlich kritisch, weil moderne Controller die Verschlüsselung intern anders handhaben als der Host. Selbst wenn die NAND-Chips noch heile sind, bekommt ohne den passenden Controller-State niemand mehr Klartext zurück. Mit anderen Worten: ein einfacher PCB-Tausch wie bei meiner alten Seagate SCSI ist 2026 nicht mehr drin, schon gar nicht im Selbstbau.
Update 2026: Backup schlägt Recovery
Die ehrliche Wahrheit nach 15 Jahren: ich habe nicht mehr ein einziges Mal in echt eine Datenrettung gemacht. Nicht weil die Tools schlechter geworden wären, sondern weil ich Backups habe. Wenn eine Platte stirbt, ziehe ich den letzten Snapshot zurück und gut ist. Recovery ist die Notlösung, wenn das Backup fehlt oder kaputt ist.
Was ich heute tatsächlich nutze:
ZFS-Snapshots mit zfs-auto-snapshot: stündlich, täglich, wöchentlich. Auf der Workstation und im Storage. Versehentliches rm -rf oder ein Crypto-Trojaner sind in Sekunden zurückgerollt.
zfs send / zfs recv auf einen externen Pool und auf ein Offsite-System. Inkrementell, verschlüsselt mit zfs send -w, vollautomatisch per Cron.
Borg / Restic für die Geräte, die kein ZFS sprechen. Deduplizierend, verschlüsselt, push und pull-Modi.
Time Machine auf dem MacBook, weil es genau das macht was es soll.
Die 3-2-1-Regel ist alt und immer noch korrekt: drei Kopien, auf zwei verschiedenen Medien, eine davon räumlich getrennt. Cloud-Sync wie Dropbox, OneDrive oder Google Drive ist dabei kein Backup. Wenn dort etwas gelöscht wird, ist es im selben Moment auch lokal weg. Ein Backup ist immer eine Kopie, die nicht automatisch mitläuft.
Update 2026: Tools und Preise heute
Die guten Nachrichten zuerst: alle vier Tools aus dem Original werden weiter aktiv gepflegt.
GNU ddrescue: aktuell Version 1.28, läuft auf jedem Linux/BSD/macOS. Mit ddrescueview gibt es eine GUI, die das Mapfile visualisiert.
PhotoRec / TestDisk: Version 7.2, von cgsecurity.org. Versteht inzwischen über 500 Dateiformate, auch moderne wie HEIC, AVIF, MKV-Container.
ntfsundelete: Teil der ntfs-3g/ntfsprogs, weiterhin im Standard-Repository jeder Distribution.
SMART und Vorhersage: smartctl aus smartmontools ist Pflicht. Die Werte Reallocated_Sector_Ct, Current_Pending_Sector und Offline_Uncorrectable sagen oft schon Tage vorher, dass die Platte sterben wird.
Bei den Preisen für professionelle Datenrettung hat sich einiges getan. Die Diagnose liegt heute meist zwischen 50 und 200 Euro, oft sogar kostenlos wenn man den Auftrag erteilt. Die eigentliche Rettung ist stark gestaffelt: einfache Logikfehler ab etwa 300 Euro, mechanische Defekte mit Reinraum ab 800 bis 1.500 Euro, schwere Schäden mit Plattentausch und Adaption-Tabellen können immer noch vier- bis fünfstellig werden. Anbieter wie CBL, Ontrack oder Stellar geben kostenlose Erstdiagnose, das nutze ich heute auch wenn nur ein Verdacht im Raum steht.
Ein Hinweis noch: SSD- und NVMe-Recovery ist deutlich teurer als HDD-Recovery, weil der Reinraum-Aufwand durch teure Equipment-Setups für NAND-Reads ersetzt wird. Wer also wirklich wichtige Daten auf einer SSD hatte, fährt mit einem soliden Backup-Konzept finanziell und nervlich besser.
Fazit
Für normal gelöschte Dateien auf NTFS reicht ntfsundelete. Bei physischen Schäden ist ddrescue das Mittel der Wahl, um erst ein Image zu sichern. Und wenn das Dateisystem komplett zerstört ist, kann PhotoRec anhand der Datei-Header noch erstaunlich viel retten. Wichtigste Regel: Nie an der Originalplatte arbeiten, immer zuerst ein Image ziehen.
2026 gilt das alles weiter, mit zwei Einschränkungen. Auf SSDs und NVMe kommt man oft schon gar nicht mehr an die Daten. Und: das beste Recovery ist das, das man nie machen muss. Backup, Backup, Backup.
Dieses soll eine kleine Beschreibung über die Gründe, die eigentliche Installation und Einrichtung meines privaten SambaServers werden. Also kein HowTo!
Sollte jemand Fragen oder Anregungen haben, freue ich mich natürlich über jede E-Mail. Solltest du Fragen stellen achte bitte darauf deine Frage so genau wie irgend mäglich zu stellen. Beschreibe kurz dein Problem, haue mich nicht mit log und configs zu und habe etwas Geduld. Ich bekomme nicht nur eine E-Mail am Tag. Darum werde ich ganz sicher nur auf unfreundliche und ungenaue Fragen antworten. KEINER hat ein Recht drauf von mir Support zu bekommen!!
Nun, die Situation bei mir schaut ca. so aus: Meine Familie, der Nachbar und ich selbst sitzen zusammen im Netzwerk. Zu dem kommt immer mal wieder Besuch zu uns. Da wir auch etwas mehr Platz als der normale Durchschnitt haben, finden auch oft irgendwelche LANs usw. bei uns stat. Zu dem hängt noch eine Firma und ein geschlossenes WLAN mit drin.
Wenn man mehr als nur einen Rechner hat kommt es schnell vor, dass man bestimmte Daten nicht nur an einem Rechner braucht. Aus diesem Grund habe ich mir hier einen FileServer aufgestellt und alle möglichen Daten dort abgelegt. Jetzt stellt sich die Frage wie von einem anderen Rechner an diesen herankommen? Da ich selbst nur LinuxSysteme nutze (der FileServer ist also auch Linux basiert) mache ich das ganze über ssh/scp oder halt über NFS. Jetzt sind aber noch mehr Menschen in meinem Netzwerk. Diese wollen nun auch ihre Daten dort ablege. Zum Einen, weil dort mehr Platz ist als auf ihrem Rechner und zum Anderen weil dort täglich eine Datensicherung gefahren wird. Die Rechte für einen NFSShare sind schnell angelegt… bringt nur leider nichts, wenn es WindowsUser sind, welche auf die Shares zugreifen wollen. Microsoft Systeme managen so etwas fast immer über das SMB Protokoll.
Server Message Block (kurz SMB) ist ein Protokoll für Datei, Druck und andere Serverdienste im Netzwerk unter Microsoft WindowsBetriebssystemen. Es ist der Kern der Netzwerkdienste von Microsofts LANManager, der WindowsProduktfamilie, sowie des LANServers von IBM.
Samba ist eine freie SoftwareSuite, die das Server Message Block Protokoll (SMB) für UnixSysteme verfügbar macht. Dieses Protokoll wird manchmal als CIFS (Common Internet File System), LanManager oder NetBIOSProtokoll bezeichnet.
Samba ist damit in der Lage, Funktionen eines WindowsServer zu übernehmen. Es gilt als stabiler und performanter als die WindowsAlternative und ist, da zudem noch frei verfügbar, auch bei vielen Firmen und Organisationen sehr angesehen.
Würde sagen: Ich mach es mit Samba 🙂
Samba wird recht übersichtlich in einer einfachen Konfigurationsdatei konfiguriert. Diese liegt normalerweise im Ordner /etc/samba und nennt sich smb.conf.
Ich liste erst mal meine hier auf und erläutere dann weiter unten die wichtigsten Einträge!
######### /etc/samba/smb.conf # Anfang #########
[global]
#
#Servername / Domain / usw.
netbios name = kernelerror
server string = HAUPT_Server
#
#Arbeitsgruppe
workgroup = servers
#
#Passwoerter gleichzeitig aedern und Sicherheits..
unix password sync = yes
passwd program = /usr/bin/passwd %U
passwd chat = *password* %n\n *password* %n\n *successfull*
min password length = 2
admin users = kernel
force directory mode = 0750
directory mask = 0750
force create mode = 0750
create mask = 0750
encrypt passwords = Yes
update encrypted = Yes
map to guest = Bad User
host allow 192.168.0. 127.
#
#Server und PDC einstellungen
domain master = Yes
name resolve order = dns host bcast wins
nt acl support = Yes
nt pipe support = Yes
nt smb support = Yes
wins support = Yes
wins proxy = Yes
name resolve order = dns host bcast wins
logon path = \\%L\profiles\%U
time server = Yes
socket options = SO_KEEPALIVE IPTOS_LOWDELAY TCP_NODELAY
keepalive = 120
preferred master = Yes
logon script = %U.bat
domain logons = Yes
os level = 65
logon drive = u:
logon home = \\%L\Profiles\%U
# NT RUMMEL
add user script = /usr/bin/useradd d /dev/null g machines c 'Machine Account' s /bin/false M %u
add user script = /usr/bin/useradd s /bin/false %u
username map = /etc/samba/smbusers
#
# Logs
max log size = 250
log file = /var/log/samba/samba.log.%m
debug level = 3
log level = 1
syslog = 0
#
# Speed
read raw = Yes
write raw = Yes
stat cache = Yes
stat cache size = 50
shared mem size = 5242880
#
# sonstiges
interfaces = 192.168.0.10/24
printing = cups
printcap name = CUPS
load printers = yes
#
# Lange Dateinamen und Umlaute
protocol = NT1
default case = lower
mangle case = no
mangled names = yes
case sensitive = no
preserve case = yes
short preserve case = yes
[netlogon]
comment = Logon Scripts
path = /home/netlogon
browseable = no
[homes]
comment = Heimatverzeichnis
writeable = Yes
browseable = No
[system]
comment = Server
path = /
writeable = yes
browseable = no
read only = no
valid users = kernel
write list = kernel
read list = kernel
[pool]
create mask = 0755
directory mask =0755
comment = Der Pool
path = /home/pool
writeable = yes
browseable = no
read only = no
[printers]
comment = All Printers
path = /var/tmp
printable = Yes
create mode = 0700
browseable = No
writeable = No
[print$]
comment = Printer Drivers
path = /var/lib/samba/drivers
create mask = 0664
directory mask = 0775
######### /etc/samba/smb.conf # Ende #########
Wie man sehen kann ist die Konfigurationsdatei in mehrere Bereiche aufgeteilt. Ein Berich beginnt immer mit:
[bereichname]
Der Bereich „global“ sollte immer vorhanden sein. Einstellungen die man nicht vorgibt werden vom SambaDeamon mit den Standardwerten gefahren. Im Bereich „global“ werden nun alle Einstellungen gesetzt die für den SambaServer selbst gelten. Die ersten beiden Punkte lasse ich aus, da sie sich selbst erklären sollten.
Interessant wird es meiner Meinung nach hier: unix password sync = yes passwd program = /usr/bin/passwd %U passwd chat = *password* %n\n *password* %n\n *successfull* min password length = 2
Hiermit gebe ich dem SambaServer vor, dass die Benutzer welche auf der Unix bzw. Linuxebene angelegt werden auch gleichzeitig im SambaServer angelegt werden. Natürlich mit dem gleichen Passwort, welches aber nicht kürzer als zwei Zeichen lang sein darf. Zu dem können User auf NTBasierten Systemen ihr Passwort von diesen aus selbst ändern, sofern es ihnen erlaubt ist versteht sich. Die User können natürlich mit ihrem Passwort auch auf der Konsole angelegt werden. Man muss aber darauf achten, dass der Username schon auf der Unixebene existiert. Sie müssen nicht zwingend die gleichen Kennwörter unter Unix/Linux und Samba haben. Angelegt wird ein User mit:
smbpasswd -a username [als root auf der Konsole]
Sollte der User schon unter Samba existieren wird sein Eintrag mit einfach nur aktualisiert.
admin users = kernel
Dieser Eintrag gibt den Benutzer an, welcher nach seiner Anmeldung auf den Shares, mit den Rechten des Unix Users Root Dateien und Ordner anlegt / liest / bearbeiten. Hier sollte man vorsichtig sein. Dieser User hat wirklich die gleichen Rechte wie der ROOTUser!!
map to guest = Bad User
Ist dies so angegeben, können nur User auf den Server zugreifen, welche sich auch anmelden. Ein User kann sich am System anmelden, muss aber keinen Zugriff auf einen Share haben.
#Server und PDC einstellungen
Ab diesem Eintrag wird dem SambaServer gesagt das er als PDC für die oben angegebene Domain arbeiten soll. Die einzelnen Punkte haben schöne passende Namen, daher sollte man sie auch so verstehen können. Gibt es Fragen? ==> einfach mailen! Hat man NTBasierte Systeme, welche sich auch am PDC anmelden sollten, muss man einen Computeraccount für den jeweiligen Rechner anlegen. Das ist viel Arbeit pro Rechner. Da NTSysteme das aber selbst können, sollten sie doch die Arbeit für uns machen, oder? Daher müssen wir noch folgendes eintragen:
Können dem Samba Server etwas einheizen. Sie können den Server um 50% schneller laufen lassen. Die Hardware sollte aber mitspielen, sonst verliert man Daten.
Zum Drucken unter Linux nutze ich seit einiger Zeit CUPS. Um Windows jetzt auch den Zugriff auf diese Drucker zu gewähren muss ich Samba angeben, dass ich CUPS zur Druckerverwaltung nutze. Dieses mache ich mit diesem Eintrag:
Wenn man den SambaServer als PDC betreibt möchte man natürlich auch für Windows die Loginscripte nutzen. Damit einfach und schnell die Uhrzeit abgeglichen wird oder Laufwerke und Drucker beim Anmelden eingebunden werden. Dazu muss ein neuer Bereich mit dem Namen „netlogon“ angelegt werden. Das Ganze schaut dann wie folgt aus.
Der Text hinter comment wird als kleine Beschreibung bei den Shares angezeigt. path gibt den Unixpfad zum Ordner an, welcher „freigegeben“ werden soll. Ist browseable auf no gesetzt wird die Freigabe nicht in der Netzwerkumgebung usw. angezeigt.
Ich habe hier folgendes aufgenommen um es zu beschreiben. Man sollte das aber nicht machen! [system] comment = Server path = / writeable = yes browseable = no read only = no valid users = kernel write list = kernel read list = kernel
Hier wurde der Bereich system angelegt. Vielleicht sollte ich an dieser Stelle sagen, dass der Bereichsname auch gleichzeitig der Name des Shares ist. Hier taucht der Schalter writeable und read only auf. Die Schalter machen von der Logik her das gleiche. Ich setzte immer beide um sicher zu gehen das auch wirklich das passiert was ich will. Sie verhindern oder erlauben das Schreiben auf Shares. Der Punkt valid users gibt an, welche user überhaupt das Recht haben auf diesen Share zuzugreifen. write list bestimmt die User die auf dem Share schreiben oder verändern dürfen. read list erlaubt oder verbietet halt das lesen.
Folgende Einträge geben an, mit welchen UnixBerechtigungen Daten auf den Shares geschrieben werden sollen. Unter Daten fallen auch Ordner.
force directory mode = 0750 directory mask = 0750 force create mode = 0750 create mask = 0750
Ich glaube mit diesen Angaben hat jeder nun schon einen kleinen überblick über dass, was mit dem SambaServer möglich ist und wie ich es hier eingesetzt habe.
Navigationssystem / Routenplaner für Linux
Ich habe lange Zeit ein Navigationssystem mit Routenplaner für mein Linux Notebook gesucht.
Jetzt habe ich es gefunden!
Die Software nennt sich Navigator 4 Europe und kommt von der Firma Directions Ltd aus England.
Genaueres findet ihr unter der Homepage der Firma unter: http://www.directions.ltd.uk/
Die Software läuft unter Linux (QT 3) und Windows. Zusammen mit der Software wurde mir auch eine USB GPS-Maus, von der Firma NAVI Lock, geliefert. Diese Firma hat natürlich auch eine Homepage die ihr unter folgender Adresse findet: http://www.navilock.de/
Die GPS-Maus NL-202U wird als serielles Gerät erkannt. Sofern der Kernel passend konfiguriert ist. Es muss also im Kernel oder als Modul die USB/Seriell Unterstützung mit übersetzt werden. Ist das gemacht, sollte das Gerät unter /dev/ttyUSB0, /dev/ttyUSB1…. zu finden sein.
Tipp:
Bei GPS-Geräten unterscheidet man zwischen einem Warm- und einem Kaltstart. Als Kaltstart wird der erste Start des GPS-Gerätes bezeichnet. Hier stellt dieses eine ganze Menge komplexer Berechnungen an und synchronisiert sich, auch Datum und Zeit lassen sich später vom Gerät nehmen. Der Kaltstart kann je nach der Qualität des Gerätes bis zu 10 Minuten dauern. Beim Warmstart geht es etwas schneller, das System synchronisiert sich aber auch kurz. In diesem Zustand sollte man das GPS-Gerät nicht von der Stelle bewegen. Sonst bekommt man vielleicht überhaupt kein Signal. Erst nach dem Abschluss des Kalt- bzw. Warmstarts wird einem die Anzahl der gefundenen Satelliten angezeigt. Man braucht min. 3!
In der Software kann man die Sprache im Menü von Englisch auf Deutsch umstellen. Die sprachgesteuerte Navigation (Ja, die Software erzählt einem wann und wo man abbiegen muss) ist dann auch auf Deutsch, wenn man es bei der Installation mit installiert hat.
Die Software hält eine Menge Kartenmaterial vor, fast über ganz Europa. Hier eine kleine Auflistung:
Andorra 100 % – Kartengrösse: 1 MB
Belgien 100 % – Kartengrösse: 113 MB
Dänemark 100 % – Kartengrösse: 95 MB
Deutschland 100 % – Kartengrösse: 1212 MB
Frankreich 100 % – Kartengrösse: 1237 MB
Finnland 79.41 % – Kartengrösse: 173 MB
Großbritanien 100 % – Kartengrösse: 776 MB
Luxemburg 100 % – Kartengrösse: 10 MB
Italien 91,74 % – Kartengrösse: 958 MB
Niederlande 100 % – Kartengrösse: 178 MB
Nord Irland 16.46 % / Rep. von Irland 45.09 % – Kartengrösse: 13MB
Norwegen 100 % – Kartengrösse: 200 MB
Österreich 100 % – Kartengrösse: 168 MB
Polen 4.23 % – Kartengrösse: 44 MB
Portugal 41.28 % – Kartengrösse: 54 MB
San Marino 100 % – Kartengrösse: 1 MB
Schweden 100 % – Kartengrösse: 340 MB
Schweiz 100 % – Kartengrösse: 113 MB
Spanien 79.54 % – Kartengrösse: 494 MB
Tschechische Rep. 72.9 % – Kartengrösse: 108 M
Die ganze Software ist bei mir auf einer DVD gekommen. Wobei die Einzelnen Karten auf der DVD mit RAR komprimiert sind. Der konsolenbasierte Installer entpackt diese ohne Probleme von alleine. Man sollte vorher sicherstellen das man unrar auf seinem Linux-System installiert hat. Das Entpacken und Installieren von allen Karten dauert dann natürlich etwas.
Leute mit alten Kirsten sollten sich auch beim Arbeiten mit der Software auf längere Wartezeiten einstellen.
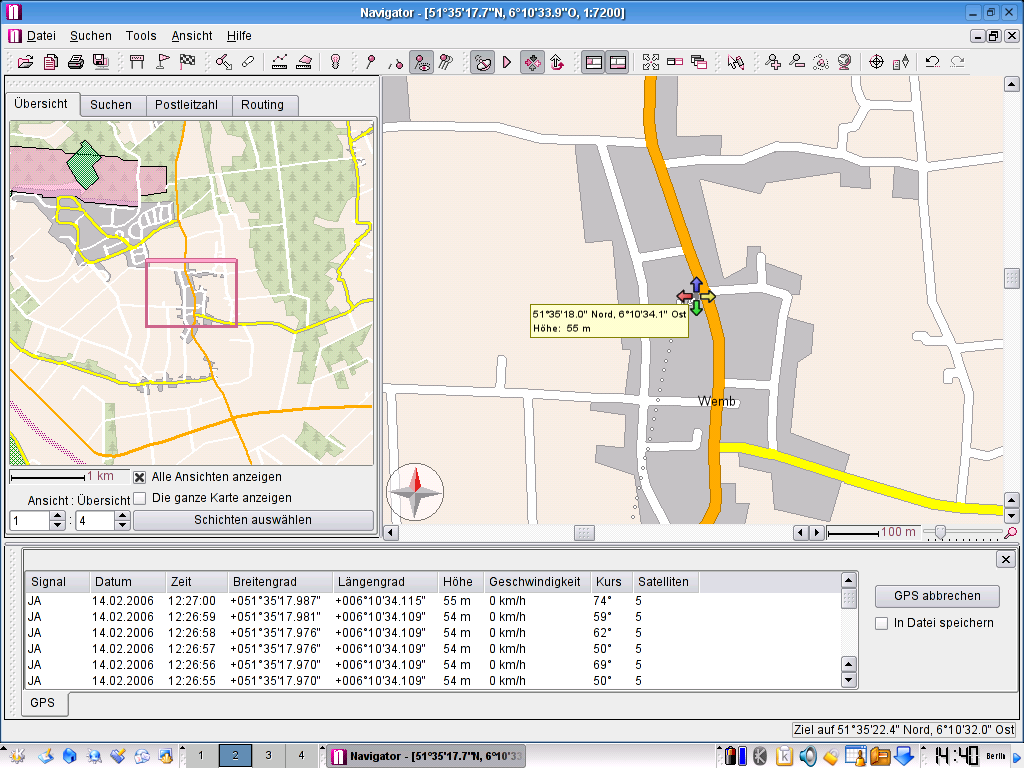
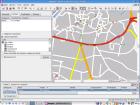
In der Software kann man sehr genau und gezielt suchen. Man kann schon vor der Suche viele Filter anwenden und das Suchergebnis wird einem auch recht übersichtlich präsentiert.
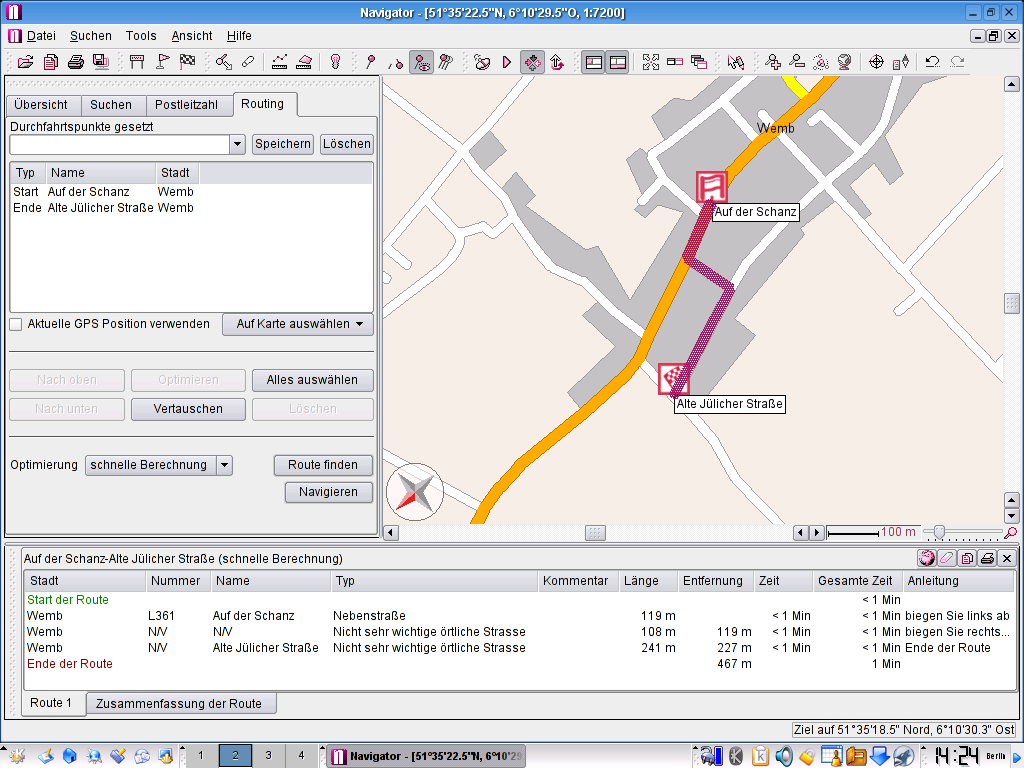
Bei der Routenerstellung kann man unbegrenzt viele Wegpunkte setzten und verschiedene Routenarten und Alternativrouten generieren lassen.
Alles ist ohne Probleme auf Papier zu bringen. Karte sowie auch die Streckenliste. Genaue Entfernung, voraussichtlicher Benzinverbrauch und Kosten lassen sich genau so gut ausgeben.
Keine Software ist perfekt. Daher gibt es immer mal wieder neue Updates, welche direkt von der Homepage des Herstellers herunter geladen werden können. Was ich auch empfehlen würde denn mir ist die gelieferte Version ohne Updates ein paar mal abgeschmiert.
Als Systemvoraussetzung wird unter anderem eine der gängigen grossen Linux-Distributionen (Suse bla…) verlangt. Ich bin das Risiko einfach mal eingegangen und habe es auf Gentoo installiert. Ich kann mich dabei über nichts beklagen.
Soooo… da jeder gerne ein paar Bilder sehen möchte folgen hier nun einige! Ach ja, bevor ich es vergesse. Meiner Meinung nach, ist die Software inkl. GPS-Empfänger sein Geld wert und funktioniert prächtig.
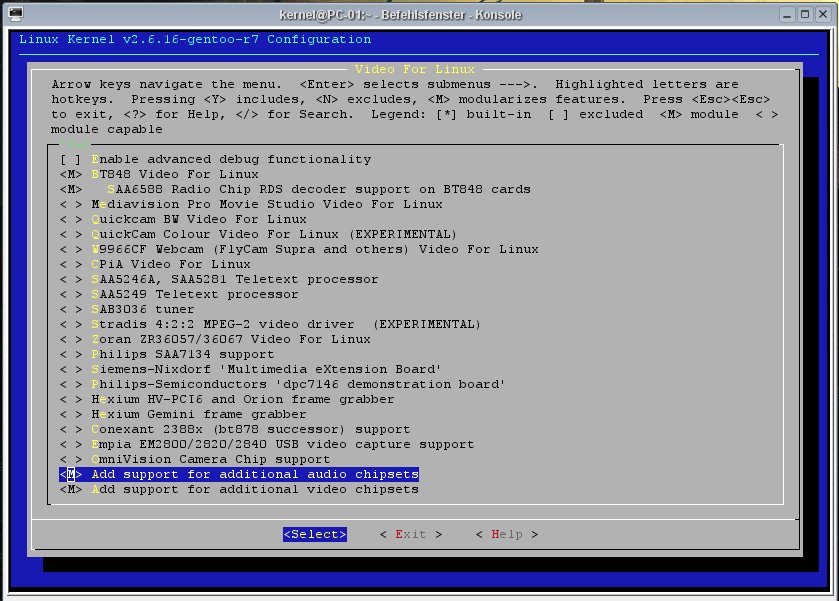
Veraltet: Die Hauppauge PVR-250/350 und der ivtv-Treiber sind seit vielen Jahren obsolet. Aktuelle TV-Karten werden über V4L2 angesprochen.
Wer mit der PVR 350 von Hauppauge einfach nur TV schauen möchte, ohne Mythtv und ohne vdr der wird etwas länger nach einer passenden Anleitung im Internet suchen. Besonders wenn er einen Satelitenresiever oder ähnliches an seinen Composite-Anschluss seiner PVR350 anschliessen will.
Folgene Einstellungen sollten im Kernel gemacht werden:
Ich nutze hier bei mir Gentoo und den Kernel: Linux PC-02 2.6.16-gentoo-r12 #3 PREEMPT Mon Jul 10 23:54:18 CEST 2006 i686 Pentium III (Coppermine) GNU/Linux
Zuerst einmal sollte unter /etc/modules.d/ eine Datei mit dem Namen ivtv angelegt werden, sofern nicht schon vorhanden:
touch /etc/modules.d/ivtv
Der Inhalt dieser Datei sollte nun so abgeänder werden:
alias char-major-81 videodev
alias char-major-81-0 ivtv
alias char-major-61 lirc_i2c
options msp3400 once=1
add below ivtv msp3400 saa7115 saa7127 tuner
add above ivtv ivtv-fb
add above ivtv lirc_dev lirc_i2c
Das ist jetzt auch der Inhalt meiner ivtv-Datei. Diese ist mit den lirc Optionen auch schon ausgelegt auf den Einsatz zusammen mit Mythtv. Es kann aber alles so übernommen werden. Selbst wenn wir am Ende einfach nur TV schauen wollen.
Jetzt sollte der Treiber installiert werden, welcher es ermöglicht den Hauppauge PVR 350 hardware MPEG-2 chip zu „aktivieren“.
Das Treiberpaket nennt sich ivtv. Die offizielle Homepage zu diesem Projekt ist: http://www.ivtvdriver.org/!
Mit der Version 0.4.0-r3 unter Gentoo hatte ich einige Pobleme mit einem Kernel ab Version 2.6.15 aus diesem Grund habe ich zu einer maskierten Version gegriffen. Zu dem ist f�r den Kernel ab Version 2.6.x ja auch die ivtv Version 0.6.x zuständig!
Ich nutze jetzt die Version 0.6.3. Um diese unter Gentoo zu „demaskieren“ hilft folgendes:
Nun kann auch schon mit der Installation des Paketes begonnen werden:
emerge -a ivtv
Ist die installation sauber abgeschlossen kann man sein Modul auch schon laden:
modprobe ivtv
Nun sollte man am besten kurz nachschauen ob das mit dem Laden geklappt hat:
dmesg |grep ivtv
Es sollte sich in etwas so etwas in die Konsole erbrechen:
ivtv: ==================== START INIT IVTV ====================
ivtv: version 0.6.3 (tagged release) loading
ivtv: Linux version: 2.6.16-gentoo-r12 preempt PENTIUMIII REGPARM gcc-4.1
ivtv: In case of problems please include the debug info between
ivtv: the START INIT IVTV and END INIT IVTV lines, along with
ivtv: any module options, when mailing the ivtv-users mailinglist.
ivtv0: Autodetected Hauppauge WinTV PVR-350 card (cx23415 based)
tuner 1-0061: chip found @ 0xc2 (ivtv i2c driver #0)
tda9887 1-0043: chip found @ 0x86 (ivtv i2c driver #0)
saa7115 1-0021: saa7115 found @ 0x42 (ivtv i2c driver #0)
saa7127 1-0044: saa7129 found @ 0x88 (ivtv i2c driver #0)
msp3400 1-0040: MSP4418G-B3 found @ 0x80 (ivtv i2c driver #0)
ivtv0: loaded v4l-cx2341x-enc.fw firmware (262144 bytes)
ivtv0: loaded v4l-cx2341x-dec.fw firmware (262144 bytes)
ivtv0: Encoder revision: 0x02050032
ivtv0: Decoder revision: 0x02020023
ivtv0: Allocate DMA encoder MPEG stream: 128 x 32768 buffers (4096KB total)
ivtv0: Allocate DMA encoder YUV stream: 161 x 12960 buffers (2048KB total)
ivtv0: Allocate DMA encoder VBI stream: 80 x 26208 buffers (2048KB total)
ivtv0: Allocate DMA encoder PCM audio stream: 455 x 4608 buffers (2048KB total)
ivtv0: Create encoder radio stream
ivtv0: Allocate DMA decoder MPEG stream: 16 x 65536 buffers (1024KB total)
ivtv0: Allocate DMA decoder VBI stream: 512 x 2048 buffers (1024KB total)
ivtv0: Create decoder VOUT stream
ivtv0: Allocate DMA decoder YUV stream: 20 x 51840 buffers (1024KB total)
ivtv0: loaded v4l-cx2341x-init.mpg firmware (155648 bytes)
ivtv0: Initialized Hauppauge WinTV PVR-350, card #0
ivtv: ==================== END INIT IVTV ====================
Jetzt kann man schon das erste mal probieren ob man Fernsehen schauen kann. Man braucht nur einen Videoplayer der einen mpeg2 Stream abschpielen kann. Ich nutze dazu fast immer mplayer oder kmplayer.
Ein: mplayer /dev/video0 sollte nun Schnee in den Player zaubern. Nun ist es Zeit seinen Satelitenresiever (oder was auch immer) am Composite-Eingang seiner PVR350 in Gang zu setzen.
Folglich müssen wir unserer Karte nur noch sagen das wir einen anderen Eingang für unser Videosignal nutzen wollen!
ivtvctl -P zeigt uns den gerade genutzten Videoeingang. ivtvctl -n zeigt uns alle möglichen Video Ein- und Ausgänge.
Um ihn zu ändern brauchen wir ivtvctl -p der Composite-Eingang sollte auf 5 oder 6 liegen, also:
ivtvctl -p 5
Na? ist das nicht was? Bild und Ton sollte nun den Schnee aus unserem mplayer vertrieben haben.
Natürlich kann man nun auch mit der Karte ein Video aufnehmen! Einfach mal ein:
In die Konsole hämmern und schon wird aufgebommen. Ist man fertig mit seiner Aufnahmen kann man alles einfach mit STRG + C abbrechen. Die Datei /ORDNERmitPASSENDENrechten/video.mpg ist nun schon ein komplettes mpg Video und man kann damit machen was man will!
Natürlich kann man auch wärend der Aufnahme einfach mal schauen ob alle glatt geht und mit dem mplayer live testen:
mplayer /ORDNERmitPASSENDENrechten/video.mpg
Die Aufnahme kann dabei natürlich weiter laufen. So lässt sich dann auch die „Pause-Funtion“ nutzen, wenn auch etwas umständlich!
Wer Videorekorder, Teletext, TV-Zeitschrift, Pausefunktion, Netzwerkstreamen usw. usw.usw. haben will sollte sich nun doch vielleicht einmal überlegen MythTV oder VDR zu testen. tvtime xawtv und auch kdetv haben wohl zum Teil Plugins für die PVR350, diese kommen aber auch nicht ohne die ivtv-Treiber aus und mir ist noch keines unter die Nase gekommen, welches wirklich sauber Funktioniert hat.
Hinweis: Dieses Script stammt aus 2009 und nutzt iptables auf einem Debian mit Kernel 2.4. Die Konzepte sind zeitlos, aber die Umsetzung ist veraltet. Heute nimmt man nftables statt iptables. Trotzdem: Wer versteht was hier passiert, versteht auch nftables.
Das Setup
Dedizierte Firewall-Maschine mit drei Netzwerkkarten. Ein Interface zum Internet (PPPoE), zwei für interne Netze mit unterschiedlichen Berechtigungen. Default-Policy auf allen Chains: DROP. Alles was nicht explizit erlaubt ist, wird verworfen.
Eigene Chains für sauberes Logging. Jedes verworfene Paket wird mit Prefix geloggt bevor es gedroppt wird:
# MY_REJECT: Protokollieren und zurückweisen
iptables -N MY_REJECT
iptables -A MY_REJECT -p tcp -m limit --limit 7200/h -j LOG --log-prefix "REJECT TCP "
iptables -A MY_REJECT -p tcp -j REJECT --reject-with tcp-reset
iptables -A MY_REJECT -p udp -m limit --limit 7200/h -j LOG --log-prefix "REJECT UDP "
iptables -A MY_REJECT -p udp -j REJECT --reject-with icmp-port-unreachable
# MY_DROP: Portscans stillschweigend verwerfen
iptables -N MY_DROP
iptables -A MY_DROP -m limit --limit 7200/h -j LOG --log-prefix "PORTSCAN DROP "
iptables -A MY_DROP -j DROP
Stealth Scan Detection
Ungültige TCP-Flag-Kombinationen erkennen und verwerfen. Kein normaler Client setzt SYN+FIN gleichzeitig oder schickt ein Paket ohne Flags:
# Keine Flags gesetzt
iptables -A INPUT -p tcp --tcp-flags ALL NONE -j MY_DROP
# SYN und FIN gleichzeitig
iptables -A INPUT -p tcp --tcp-flags SYN,FIN SYN,FIN -j MY_DROP
# SYN und RST gleichzeitig
iptables -A INPUT -p tcp --tcp-flags SYN,RST SYN,RST -j MY_DROP
# FIN ohne ACK
iptables -A INPUT -p tcp --tcp-flags ACK,FIN FIN -j MY_DROP
Connection Tracking und NAT
Stateful Firewall: Bestehende und zugehörige Verbindungen durchlassen, neue nur aus dem internen Netz erlauben. NAT per MASQUERADE für den Internetzugang:
# Loopback erlauben
iptables -A INPUT -i lo -j ACCEPT
iptables -A OUTPUT -o lo -j ACCEPT
# Ausgehend: Alles erlauben
iptables -A OUTPUT -m state --state NEW,ESTABLISHED,RELATED -j ACCEPT
# Forwarding: Neue Verbindungen nur von innen
iptables -A FORWARD -i ! ppp0 -m state --state NEW,ESTABLISHED,RELATED -j ACCEPT
iptables -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
# NAT für interne Netze
iptables -t nat -A POSTROUTING -o ppp0 -s 192.168.0.0/24 -j MASQUERADE
Traffic Shaping mit tc
Mit tc (traffic control) und iptables -t mangle lässt sich die Bandbreite pro Client oder Netz begrenzen. iptables markiert die Pakete, tc ordnet sie in Queues ein:
# HTB Queueing Discipline auf dem internen Interface
tc qdisc add dev eth2 root handle 1:0 htb default 10
tc class add dev eth2 parent 1:0 classid 1:1 htb rate 150kbit ceil 250kbit
tc filter add dev eth2 parent 1: prio 0 protocol ip handle 1 fw flowid 1:1
# Pakete per iptables markieren
iptables -t mangle -A FORWARD -s 192.168.100.0/24 -j MARK --set-mark 1
Kernel-Hardening
Am Ende des Scripts werden Kernel-Parameter gesetzt die über die Firewall hinausgehen:
# SYN-Cookies gegen SYN-Flood
echo 1 > /proc/sys/net/ipv4/tcp_syncookies
# Source-Routing deaktivieren
for i in /proc/sys/net/ipv4/conf/*; do echo 0 > $i/accept_source_route; done
# Redirects ignorieren
for i in /proc/sys/net/ipv4/conf/*; do echo 0 > $i/accept_redirects; done
# Martian-Pakete loggen
for i in /proc/sys/net/ipv4/conf/*; do echo 1 > $i/log_martians; done
# ICMP-Ping ignorieren
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
# TCP-FIN-Timeout gegen DoS
echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout
Die Konzepte aus diesem Script gelten unverändert: Default DROP, Stateful Tracking, Custom Chains für Logging, Stealth Scan Detection, Kernel-Hardening. Nur die Syntax hat sich geändert. Wer heute eine Linux-Firewall baut, nimmt nft statt iptables und erspart sich die Modprobe-Zeilen. Für IPv6 braucht man eine eigene Regelkette, damals mit ip6tables, heute in nftables integriert.
Dieses soll eine kleine Beschreibung über die Gründe, die eigentliche
Installation und Einrichtung meines privaten ProxyServers werden. Also kein HowTo!
Sollte jemand Fragen oder Anregungen haben, freue ich mich natürlich über jede
EMail. Solltest du Fragen stellen achte bitte darauf deine Frage so genau wie irgend
möglich zu stellen. Beschreibe kurz dein Problem, haue mich nicht mit log und configs
zu und habe etwas Geduld. Ich bekomme nicht nur eine EMail am Tag. Darum werde ich ganz
sicher nur auf unfreundliche und ungenaue Fragen antworten. KEINER hat ein Recht drauf von mir
Support zu bekommen!!
Nun, die Situation bei mir schaut ca. so aus: Meine Familie, der Nachbar und ich selbst sitzen
zusammen im Netzwerk. Zu dem kommt immer mal wieder Besuch zu uns. Da wir auch etwas mehr
Platz als der normale Durchschnitt haben, finden auch oft irgendwelche LANs usw. bei uns stat.
Zu dem hängt noch eine Firma und ein geschlossenes WLAN mit drin.
Da ist ein Problem mit der Sicherheit natürlich vorprogrammiert und den überblick kann
man da so einfach auch nicht mehr behalten. Das Netzwerk ist daher in mehrere Bereiche, mit
unterschiedlichen Rechten aufgeteilt worden. Das Netzwerk ist zum Internet hin durch eine Firewall,
Proxy und MTA abgeschirmt. Zu MTA und Firewall sind andere Projektbeschreibungen zu finden.
Die Hauptgründe für die Einrichtung des ProxyServers sind also folgende:
Zentraler check der vom User angeforderten Webseiten auf z.B.: jugendgefährdende Inhalte
Zentraler check der vom User angeforderten Dateien auf Viren
Keine zusätzliche Software auf den Clients
Schneller Zugriff auf oft abgefragte Internetseiten
Mein ProxyServer sollte also folgendes leisten können. Zum einen sollte er die
angeforderten Webseiten auf bestimmte Worte in dessen Text durchsuchen können. Findet er
dort Worte welche nur auf Internetseiten vorkommen sollten welche nicht….. sagen wir mal,
für die tägliche Arbeit am Rechner sinnvoll sind, sollte dieser dann den Zugriff auf
diese Seite verweigern. Bei mir bereits als „bedenkliche“ oder gefährliche Webseiten
bekannte Domains, sollte der Proxy natürlich in jedem Fall den Zugriff verweigern. Es kommt in einem
Netzwerk oft vor, dass ein und die selbe Quelle im Internet mehrmals von verschiedenen Usern angefragt wird.
Warum sollte man also diese Seite für jeden Rechner einmal und vor allem immer wieder aufs Neue vom
Webserver herunterladen? Der ProxyServer sollte also auch in der Lage sein, Webseiten bzw. deren
Inhalte sinnvoll zu cachen. Leider kommen Viren und kleine aber sehr lästige Progämmchen nicht
nur als EMails oder auf Grund von Angriffen ins System, sondern leider auch sehr oft durch unbedachte
Downloads von Dateien der User. Um diese mal wieder vor sich selbst schützen zu können, müssen
alle angeforderten Daten auf Viren und der gleichen getestet werden. Ich selbst habe auf alenl meinen Systemen das
Antivirenprogramm Antivir der Firma H+BEDV Datentechnik GmbH installiert. Ich kann dieses Programm für
Unix, besonders aber für Linux Umgebungen nur empfehlen. Daher ist es logisch, dass ich dieses
Programm am liebsten auch zum Testen der Proxydaten einsetzten möchte. So erspare ich mir die Arbeit
gleich mehrere Virenprogramme zu warten.
Folgendes habe ich mir nun also eingerichtet.
Um sicher zu stellen, dass keine normalen Internetseiten mehr, ohne Zwischenspeicherung, Auswertung und
Virentest bei den User ankommt, habe ich über die Firewall alle direkten Verbindungen auf Port 80
und 21 verboten. Meine Erfahrung hat gezeigt, dass Viren und bedenkliche Webinhalte kaum über
verschlüsselte Seiten (also Port 445) gefunden werden. Diese habe ich auch weiterhin durchgelassen.
Als ProxyServer setze ich das Programm Squid ein. Zur Weitergabe der Daten an den Virenscanner nutze
ich das Programm Squirm. Hier kann ich mir sicher sein, dass alles ohne Probleme zusammenarbeiten wird.
Das eigentliche Scannen der Daten übernimmt, wie schon angedeutet, das Programm Antivir. Das eigentliche
Handling der Daten übernimmt aber das Programm ANDURAS SurfProtect.
Nun aber zur Konfiguration des ganzen!
Beginnen wir mit der Wortfilterung. Um diese zu realisieren und auch ständig erweitern zu können
habe ich mir eine Datei mit dem namen domains.deny im Ordner /etc/squid angelegt. In diese Datei müssen
nun untereinander die Worte geschrieben werden, welche nicht erwünscht sind. Hier ein Auszug aus der Datei:
############ /etc/squid/domains.deny ## Anfang ############
gay
sex
farmsex
nutte
hure
sperma
fotze
arsch
trojaner
hacker
hackertools
crack
keygen
warez
nuke
nuketools
dildo
masturbating
fucking
slut
emule
xmule
edonkey
Kazza
arschficken
spermaschleuder
kindersex
fotzenschleim
############ /etc/squid/domains.deny ## Ende ############
Sollte sich ein User über diese „Einschränkung“ beschweren druckt man am besten die Liste
aus und klärt mit ihm im öffentlichen Gespräch warum er welches Wort denn unbedingt benötigt.
Um dieses nun in den ProxyServer Squid einzubinden muss die Datei vom SquidDeamon gelesen werde können.
Daher sollten noch die Rechte gesetzt werden. Jetzt muss noch folgender Eintrag in die Konfigurationsdatei squid.conf:
Hier ist aber zu beachten, dass man die Einträge jeweils VOR den anderen acl und http_access Einträgen in
der Konfigurationsdatei schreibt, da diese von oben nach unten abgearbeitet werden.
Nach dem Speichern sollte man nun Squid die neue Konfiguration „einprügeln“:
squid -k reconfigure
[als root in der Konsole]
Erledigt das für uns.
Die acl und http_access Regeln sind in der Konfigurationsdatei ganz gut beschrieben. Daher gehe ich da nicht weiter
drauf ein. Da wir aber gerade bei der Konfigurationsdatei sind… Einige Einträge können wir gleich noch machen.
Dazu gehen wir ganz an das Ende der Datei. Dort tragen wir folgendes ein:
Jetzt müssen wir uns kurz vergewissern ob wir hiermit nicht gerade doppelte Einträge gemacht haben. Also schauen
wir die Konfigurationsdatei durch, ob die einzelnen Einträge nicht schon irgendwo existieren. Interessant ist
natürlich nur der erste Teil.
Hier werden die lokalen IP Adressen und Portnummern fest gelegt auf denen Squid lauschen soll. Die Adresse 127…
bla ist für den localhost, die Adresse 192.168.100.1 ist für die dritte NIC in meinem ProxyServer
gedacht. Der TCP Port ist jeweils 3128. Wenn man all diese Einstellungen nicht setzt lauscht Squid normalerweise
auf Port 8080, dieses aber auf jeder NIC im System.
cache_effective_user squid
cache_effective_group squid
Hier wird der Username und die Gruppe festgelegt mit welchem Squid die Dateien und Ordner in seinem Cache verarbeitet.
visible_hostname router
unique_hostname router
Hier gebe ich den Computernamen an, welcher dem User angezeigt werden soll.
cache_dir ufs /home/spool/squid 1000 16 256
Hier wird nun angegeben wo genau Squid seine Daten zwischenspeichern soll. Die weitern Angaben sind die maximale
Grösse des Caches in MB, die maximale Anzahl von Ordnern in einem Ordner und die maximale Anzahl von Unterordnern
im Cache. Squid läuft bei mir nun schon seit 4 Jahren. In dieser Zeit habe ich herausgefunden, dass er mit
diesen Einstellungen schnell und stabil läuft. Auf anderen Rechnern mit anderem Dateisystem usw. kann das
natürlich auch anders aussehen. Wieder mal so eine Sache wo man etwas probieren muss.
cache_mgr kernel-error@kernel-error.de
Sollte Squid eine Seite nicht finden, den Zugriff verweigern oder sonst etwas. Sagt er dem User er könne
sich mit seinen Problemen und Sorgen an diese EMail Adresse wenden. Will man möglichst wenig genervt
werden sollte man diese dann gegen /dev/null linken 🙂
emulate_httpd_log off
Squid legt natürlich Logdateien an. Leider formatiert squid die standardmässig so, dass kein Mensch
diese lesen kann. Mit dieser Einstellung kann man Squid aber dazu überreden diese lesbar darzustellen.
cache_mem 16 MB
Diese Einstellung sagt Squid wie viel Arbeitsspeicher er sich maximal unter den Nagel reissen darf. Ich habe
256 MB in diesem System verbaut. Mit 16 MB für den Squid läuft das Teil immer noch schön rund
und Squid kommt auch nicht aus der Puste.
ftp_user root@kernelerror.de
Wird über Squid auf einen FTPServer zugegriffen gibt er diese EMailadresse an. Ob das nötig
ist oder nicht muss man selbst entscheiden.
Nun sollte Squid normalerweise laufen und die Webseiten nach Worten filtern. Sollte noch nicht klar
sein, wie man gleich ganze Domains sperrt, sollte man sich noch mal mit dem Punkt ACLs beschäftigen. Im
Notfall antworte ich auch auf EMails. Tja, jetzt fehlt uns nur noch der Virenscanner, richtig?
Das Programm ANDURAS SurfProtect funktioniert folgendermassen. Wenn man im Internet surft laufen nun ja alle
Daten durch den Proxy. Dieser gibt bestimmte Dateitypen nun über Squirm weiter an SurfProtect. SurfProtect
ist selbst ein PHP Programm welches auf dem lokalen Webserver (es könnte theoretisch auch auf einem anderen
System laufen) läuft. Squirm gibt nun also die Anforderung der Datei virus.exe, von der Internetseite www.virus.com,
weiter an SurfProtect. Dieses öffnet nun ein Popupfenster auf dem Rechner des Users im welchem ihm mitgeteilt wird,
dass er kurz warten soll. Saugt dann die Datei Virus.exe von der angegebenen Quelle und speichert sie im Temp
zwischen. Nun checkt es mit dem Programm Antivir ob die Datei virenverseucht ist oder nicht. Ist sie es, wird dem
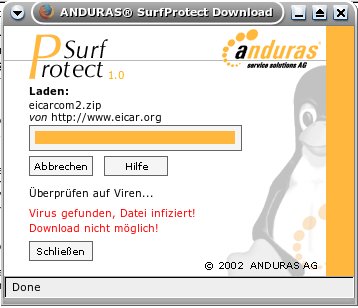
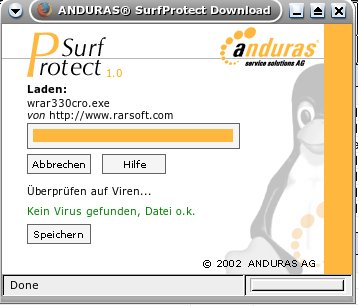
User der Zugriff auf diese Datei verwehrt (Bild 1) und diese dann gelöscht. Anderweitig wird dem User gesagt, die Datei
ist virenfrei und kann jetzt mit einem klick auf „Speichern“ abgespeichert werden (Bild 2). SurfProtect speichert
die Datei nun einen Tag lang zwischen, schaut aber bei jeder neuen Anfrage erst nach ob nicht vielleicht die Datei
auf der Quelle verändert wurde. So muss die Datei nicht bei jeder Anfrage neu heruntergeladen werden.
Um die Daten nun mit der Hilfe von Squirm weiter zu reichen muss folgendes in dessen Konfigurationsdatei eingetragen werden:
Dieser Eintrag sagt: Alle Dateien mit der Endung reg sollten an http://192.168.0.200/surfprotect/surfprot.php?url=
weitergereicht werden. Tja, das ist auch schon alles. Man muss also nur für jede Datei die man scannen will so
einen Eintrag anlegen.
SurfProtect selbst liegt im Ordner /surfprotect unter dem Ordner html im wwwTeil des Apache.
Dort liegen auch die Konfigurationsdateien. Ob man den Zugriff auf diese gewehrt oder nicht, ist einem selbst und den
Einstellungen des Apache überlassen. Die User könnten diese zwar nur lesen aber noch nicht mal mehr das
geht sie ja etwas an. Daher sollte man nur den Zugriff auf die Datei surfprot.php genehmigen.
In der Datei surfport.defaults sollte man nun noch unten folgendes eintragen:
define(SCANNER_INCLUDE, "surfprot_hbac.inc");
Damit wird SurfPortect gesagt es soll das Plugin zur Verwendung des Programmes AntiVir laden.
Damit sollte der Proxy nun auch nach Viren suchen.
Hier nun noch zwei Bilder, welche der User zu sehen bekommt. Das, was sich nun für die User ändert:
Ich habe mir vor ein paar Tagen eine neue Grafikkarte geleistet. Es ist eine Gainward PowerPack Ultra /1980. Auf dieser ist ein GeForce 6600GT Chip mit 256MB DDR3 RAM verbastelt. Nun hat die Karte einen Analogen VGA Connector und einen DVI Connector. Ich selbst habe hier noch einen 17” CRT Monitor in der Ecke stehen. Da ist mir nun eine Idee gekommen….
Ich könnte ja einfach zwei Monitore an meinen Linux Rechner anschließen. An meinem Hauptrechner ist ein 19” CRT Monitor mit Analogeingang angeschlossen. Diesen einfach mit dem DVI Adapter an den DVI Connector der VGA-Karte und den 17“ CRT Monitor (auch Analogeingang) an den normalen Analog VGA Connector der VGA-Karte.
Tja… einschalten und schaut selbst:
Beim Booten zeigen beide Monitore schon mal das gleiche an. Zumindest bis der X-Server gestartet wird. Bei mir werkelt der X.org.
Ist dieser gestartet wird der zweite Monitor abgeschaltet und alles läuft weiter wie gehabt. 🙁
Also schnell STRG + ALT + F1 gedrückt als root angemeldet und direkt mit dem vi in die xorg.conf….
Hier habe ich nun folgendes eingetragen:
Hier ist der Eintrag Option „Xinerama“ „on“hinzugekommen. Dann die Screen-Sektion!
Hier sind die beiden Screens (unten steht mehr) eingetragen. Wichtig ist das RightOf… Dieses gibt an, welche Monitor wo seht. Ok und den Identifier habe ich etwas umbenannt das ist aber für die Funktion uninteressant!
Die weiteren Punkte sind wie so oft selbsterklärend, finde ich zumindest.
Veraltet: CAcert-Zertifikate wurden nie in die Standard-Truststores der Browser aufgenommen. Kostenlose TLS-Zertifikate gibt es bei Let’s Encrypt.
CAcert ist eine feine Sache. Leider sind deren Root-Zertifikate noch nicht in allen Browsern und Programmen integrieret.
Ich habe mir nun Gedanken dazu gemacht:
Wie schaffe ich es die CAcert-Root-Zertifikate in Anwendungen von Microsoft (Word, Outlook, Internetexplorer..) und Mozilla (Thunderbird, Firefox…) so zu integrieren das sie immer als vertrauenswürdig erkannt werden? Auch bei allen anderen Usern auf dem System und denen die später noch ein neues Konto bekommen…
Natürlich könnte ich bei jedem User die Zertifikate einzeln mit der Hand importieren und als vertrauenswürdig einstufen. Es ist aber sehr aufwändig und bestimmte User haben damit ein, nennen wir es Problem! Es muss also automatisch gehen.
Für die Microsoftprodukte habe ich eine einfache Lösung gefunden. Mit >>dieser<< Regestrierungsdatei werden die CAcert-Root-Zertifikate automatisch ins System übernommen. Ab diesem Moment sind in allen Microsoftanwendungen, bei allen Usern (vorhandenen und neuen) eines Systems die Zertifikate gültig.
Bei Mozilla ist es nicht ganz so einfach. Hier geht es am einfachsten so:
!!Firefox sollte noch nicht auf dem System installiert sein!!
Dann installiert man den Firefox wie gewohnt, startet ihn und importiert die CAcert-Root-Zertifikate als vertrauenswürdig. Jetzt Firefox zu machen und lassen! Bisher alles klar und einfach. Aber nun…
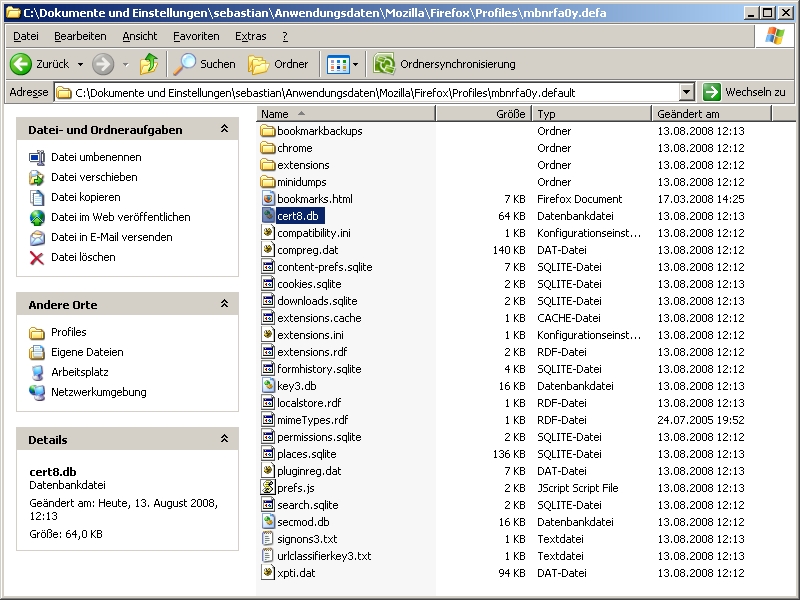
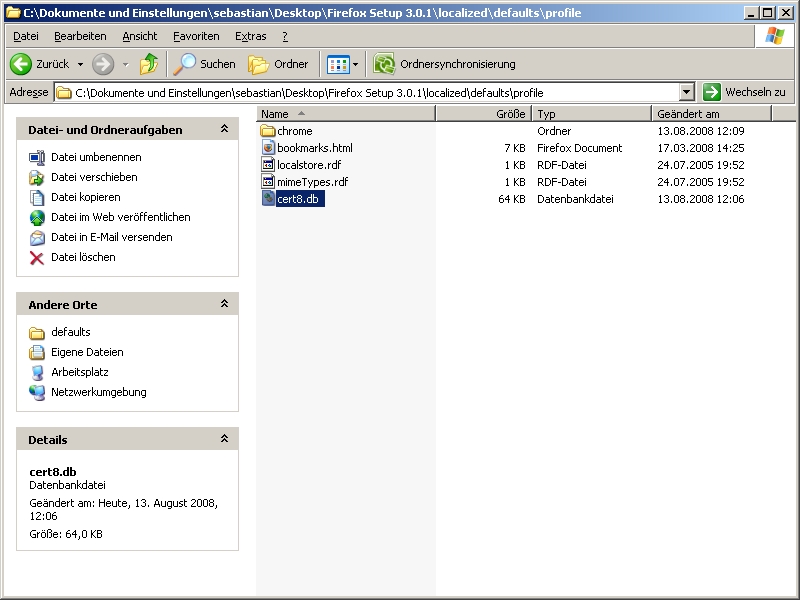
Jetzt sucht man unter: Dokumente und Einstellungen\seinUsername\Anwendungsdaten\Mozilla\Firefox\Profiles\irgendwas.default\ die Datei cert8.db. Gefunden? Gut… Merken wo!
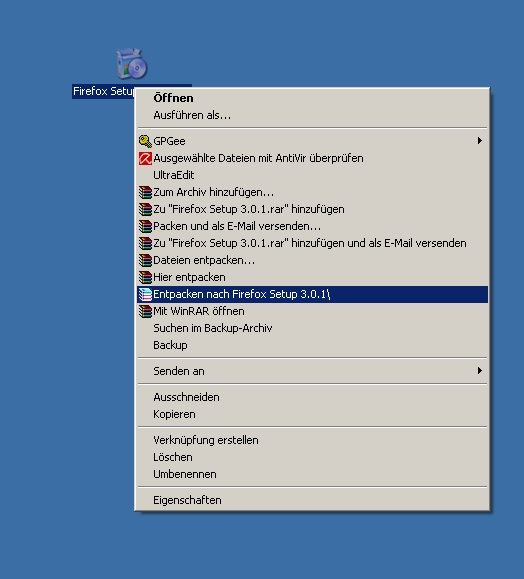
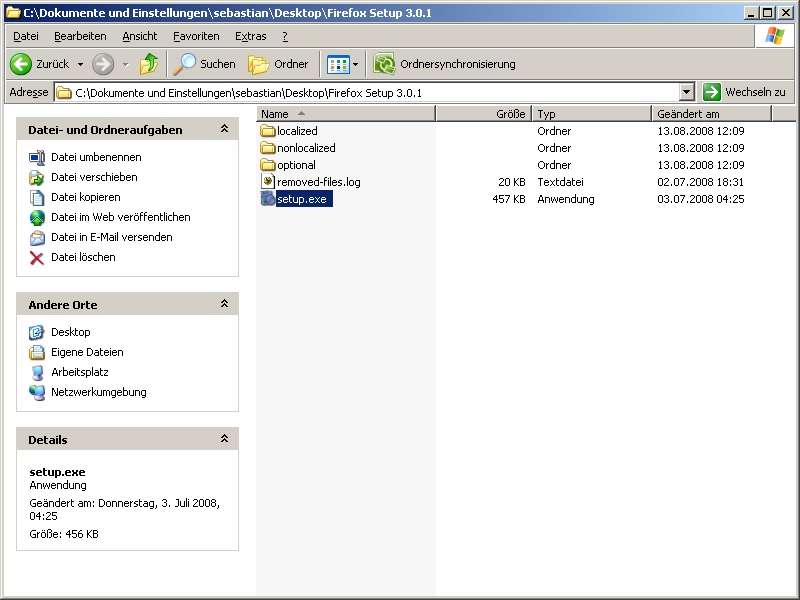
Jetzt das Firefoxinstallerpacket entpacken. Am einfachsten vielleicht mit WinRAR.
Nun kopiert man die cert8.db in den, gerade entpackten Ordner, Firefox Setup 3.0.1\localized\defaults\profile\
Startet man nun die Firefoxinstallation über die setup.exe sind die CAcert-Root-Zertifikate immer automatisch im Firefox integriert. Da immer wenn ein User das erste mal den Firefox startet, sein default Profile zusammengestellt wird. Es wird also immer die cert8.db mit in sein Profil kopiert. In dieser liegen die Zertifikate. Also auch unserer importierten CAcert-Root-Zertifikate. Dieses Packet könnte man nun immer für seine Installationen nutzen und vielleicht auch weitergeben. Will man allen existierenden Usern die Zertifikate unterschieben, muss man einfach nur die cert8.db in dessen Ordner packen (Dokumente und Einstellungen\seinUsername\Anwendungsdaten\Mozilla\Firefox\Profiles\irgendwas.default\).
So funktioniert es auch unter Thunderbird. Bei Linux funktioniert es auch über diese Datei.
Ich diese Infos helfen dem Einen oder Anderen. Wenn noch jemand Infos dazu hat, freue ich mich natürlich über zuschriften!











 Beim Booten zeigen beide Monitore schon mal das gleiche an. Zumindest bis der X-Server gestartet wird. Bei mir werkelt der X.org.
Ist dieser gestartet wird der zweite Monitor abgeschaltet und alles läuft weiter wie gehabt. 🙁
Also schnell STRG + ALT + F1 gedrückt als root angemeldet und direkt mit dem vi in die xorg.conf….
Hier habe ich nun folgendes eingetragen:
Beim Booten zeigen beide Monitore schon mal das gleiche an. Zumindest bis der X-Server gestartet wird. Bei mir werkelt der X.org.
Ist dieser gestartet wird der zweite Monitor abgeschaltet und alles läuft weiter wie gehabt. 🙁
Also schnell STRG + ALT + F1 gedrückt als root angemeldet und direkt mit dem vi in die xorg.conf….
Hier habe ich nun folgendes eingetragen:


{kind=link}