Unique Local IPv6 Addresses sind eines dieser Themen, über die man meist erst stolpert, wenn man IPv6 ernsthaft benutzt. Nicht beim ersten „IPv6 ist an“-Häkchen, sondern dann, wenn man anfängt, Netze sauber zu trennen, VPNs aufzubauen, interne Services umzuziehen oder einfach keine Lust mehr auf NAT und IPv4-Private hat. Wer die IPv6-Grundlagen auffrischen will, findet dort den Einstieg.
ULA sollen genau das sein: lokal, eindeutig genug, nicht global routbar. Im Prinzip der IPv6-Nachfolger von 10/8 & Co. Klingt simpel. Ist es auch – bis man merkt, dass Betriebssysteme mit ULA manchmal Dinge tun, die man nicht intuitiv erwartet.
Fangen wir vorne an.
Der reservierte Adressraum für ULA ist fc00::/7. Das liest man oft so, und formal ist das auch korrekt. Praktisch relevant ist davon aber nur fd00::/8. Das sogenannte L-Bit (local) muss gesetzt sein. Der andere Teil, also fc00::/8, ist bis heute nicht weiter definiert und sollte in realen Netzen schlicht nicht verwendet werden. Wenn man ULA nutzt, dann immer fd….
Eine typische ULA sieht dann so aus:
fdXX:XXXX:XXXX::/48
Aufgeschlüsselt:
| 8 Bit | 40 Bit | 16 Bit | 64 Bit |
| fd | Global ID | Subnet | Interface ID |
fd → Local-Bit gesetzt- Global ID → pseudozufällig, soll Kollisionen vermeiden
- Subnet → klassische Subnetzstruktur
- Interface ID → wie bei anderen IPv6-Unicast-Adressen
Die Global ID ist nicht „zentral vergeben“, sondern wird lokal generiert. Ziel ist nicht Sicherheit, sondern praktische Eindeutigkeit, falls Netze später zusammengeführt werden. In der Praxis funktioniert das erstaunlich gut.
Bis hierhin ist alles noch harmlos. Die eigentliche Verwirrung beginnt in dem Moment, in dem ein Host mehrere mögliche Wege zum Ziel hat.
Dual-Stack ist heute der Normalfall. IPv4 und IPv6 gleichzeitig. Und plötzlich steht ein System vor der Frage:
Nehme ich IPv4? Nehme ich IPv6? Und wenn IPv6 – welche Adresse eigentlich?
Die Antwort darauf regelt RFC 6724. Dort ist die Default Address Selection definiert. Vereinfacht gesagt: eine Prioritätenliste für Adresspräfixe. Jedes Präfix bekommt eine Präzedenz. Höher gewinnt.
Und genau hier liegt der Punkt, der viele überrascht:
IPv6 ULA haben nach RFC 6724 eine niedrigere Priorität als IPv4.
Das heißt ganz konkret:
Ist ein Ziel sowohl über IPv4 als auch über IPv6-ULA erreichbar, wird IPv4 bevorzugt.
Das fühlt sich erstmal kontraintuitiv an. IPv6 ist doch „das Neue“. Aber aus Sicht des Standards ist die Logik klar: ULA sind bewusst lokal begrenzt. IPv4 ist – trotz aller Altlasten – global eindeutig. Also gewinnt IPv4.
In der Praxis sieht man dieses Verhalten regelmäßig, vor allem auf Linux- und FreeBSD-Systemen, die sich sehr nah am RFC orientieren. Windows und Apple-Systeme mischen zusätzlich noch Happy-Eyeballs-Mechanismen hinein, was das Verhalten manchmal schwerer nachvollziehbar macht, am Grundprinzip aber nichts ändert.
Wenn man verstehen will, was ein System tatsächlich tut, hilft ein Blick in die jeweilige Prefix-Policy.
Diagnose: Welche Prioritäten nutzt mein System?
Linux:
ip -6 addr show
ip -6 route show
ip -f inet6 addrlabel show
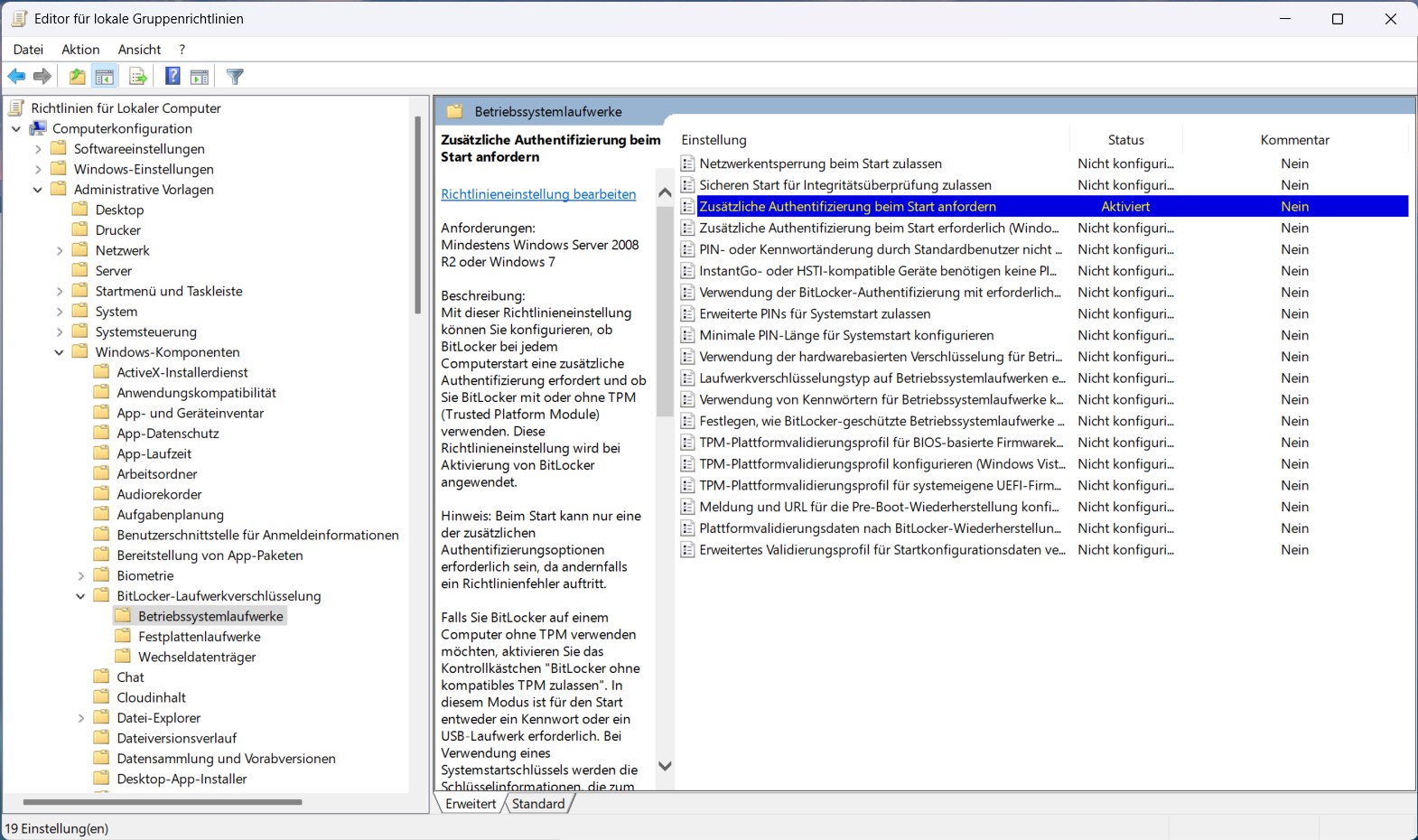
Interessant ist vor allem die Ausgabe der Address-Labels. Dort sieht man, mit welcher Präzedenz fd00::/8, IPv4-Mapped-Adressen und andere Präfixe bewertet werden.
Windows:
netsh interface ipv6 show prefixpolicies
Hier sieht man sehr direkt, welche Präzedenz Windows den einzelnen Präfixen zuordnet. In der Default-Konfiguration liegt ULA unter IPv4.
FreeBSD:
ip6addrctl
Auch hier ist die RFC-6724-Policy gut sichtbar.
Spätestens an dieser Stelle wird klar, warum ein interner Dienst trotz sauber konfigurierter IPv6-ULA plötzlich doch über IPv4 angesprochen wird. Das System macht exakt das, was der Standard vorsieht.
Nun kann man sagen: „Okay, verstanden.“
Oder man kann sagen: „Das ist nicht das Verhalten, das ich will.“
Beides ist legitim.
Anpassung: ULA bewusst höher priorisieren
Wenn ULA für interne Kommunikation wichtiger sind als IPv4 – etwa in reinen IPv6-Infrastrukturen mit IPv4 nur als Fallback – kann man die Präzedenz anpassen.
Linux (/etc/gai.conf):
# IPv6 ULA höher priorisieren als IPv4
precedence fd00::/8 45
Nach einem Reload des Stacks oder Neustart gilt die neue Reihenfolge.
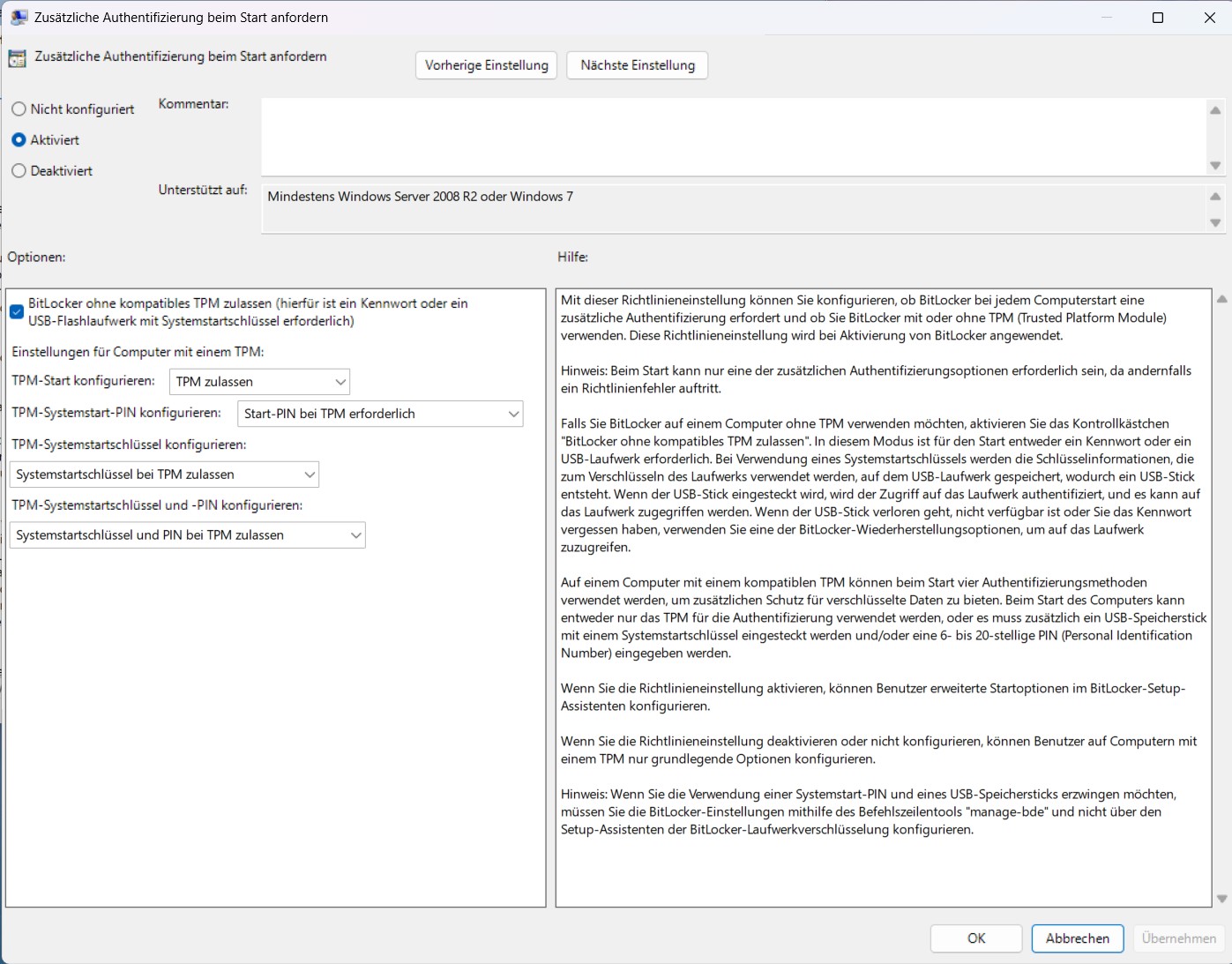
Windows:
netsh interface ipv6 set prefixpolicy fd00::/8 precedence=45 label=1
Damit liegt ULA über IPv4. Windows speichert diese Einstellung persistent.
FreeBSD:
Je nach Version über ip6addrctl oder entsprechende rc-Settings.
Wichtig: Das ist keine rein kosmetische Änderung. Man greift hier bewusst in die Adressauswahl ein. Das sollte man nur tun, wenn man das Netzdesign verstanden hat und weiß, warum man es will.
ULA sind kein Ersatz für Global Unicast Addresses. Sie sind auch kein Allheilmittel. Sie sind ein Werkzeug. Ein gutes – aber eben eines mit klar definiertem Scope.
Spannend ist, dass es inzwischen Entwürfe gibt, die das Verhalten von RFC 6724 weiterentwickeln. Ziel ist unter anderem, ULA-zu-ULA-Kommunikation besser zu priorisieren und bestimmte unerwünschte IPv4-Fallbacks zu vermeiden (ähnlich dem Problem mit Carrier Grade NAT und IPv6). Stand heute ist das aber noch nicht flächendeckend umgesetzt. Man sollte sich also nicht darauf verlassen, sondern das Verhalten der eigenen Systeme prüfen.
Am Ende bleibt:
ULA funktionieren. Sie sind sauber spezifiziert. Aber ihre Priorität ist kein Zufall, sondern eine bewusste Designentscheidung. Wer sie einsetzt, sollte wissen, warum IPv4 manchmal „gewinnt“ – und dann entscheiden, ob das so bleiben soll oder nicht.
Wie so oft bei IPv6 liegt das eigentliche Problem nicht im Protokoll, sondern in den Erwartungen, die man aus der IPv4-Welt mitbringt.
Siehe auch: IPv6 Grundlagen
Fragen? Einfach melden.