Wer eine moderne TLS-Verbindung debuggt, stolpert früher oder später über eine Zeichenkette wie X25519MLKEM768. Sie steht im nginx-Log, sie taucht in der Ausgabe von openssl s_client auf, sie klebt in jeder Handshake-Analyse. Und sie sieht aus, als wären da zwei Dinge aus Versehen zusammengeschoben worden. Sind sie aber nicht.
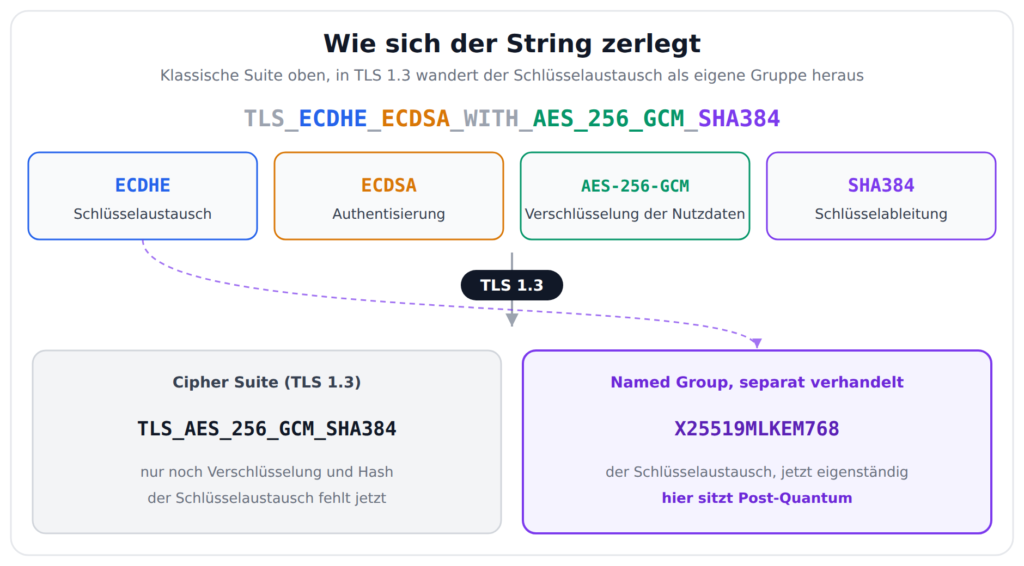
Genau wie die klassischen Cipher Suites folgt auch dieser Name einem klaren Schema. Man muss nur wissen, wo man den Schnitt ansetzt. Vor Jahren habe ich hier schon einmal so eine Zeichenkette auseinandergenommen, damals TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384. Heute ist die Post-Quantum-Welt dran. Ich möchte X25519MLKEM768 einmal komplett durchleuchten: was jeder Teil bedeutet, warum das Ganze so gebaut ist und was es bewusst nicht abdeckt.
Kurze Auffrischung: die vier Teile einer klassischen Cipher Suite
Ein klassischer Suite-Name wie TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 beschreibt vier Bausteine. Der Schlüsselaustausch legt fest, wie sich beide Seiten auf ein gemeinsames Geheimnis einigen, hier ECDHE. Die Authentisierung sagt, womit das Serverzertifikat signiert ist, hier ECDSA. Die eigentliche Verschlüsselung der Nutzdaten macht AES-256-GCM. Und der Hash SHA384 steckt in der Schlüsselableitung und sichert das Handshake-Transkript ab. Die Integrität der übertragenen Nutzdaten übernimmt bei dieser Suite dagegen schon AES-256-GCM selbst, als AEAD-Verfahren braucht es dafür keinen separaten Hash mehr. Wer das im Detail nachlesen mag, findet es im verlinkten Altbeitrag.
Diese vier Slots sind der Rahmen. Post-Quantum betrifft in diesem Beitrag genau einen davon, den Schlüsselaustausch. Die Authentisierung ließe sich ebenfalls quantensicher machen, sie bleibt hier aber vorerst klassisch, dazu am Ende mehr. Der Schlüsselaustausch ist der springende Punkt, den man zuerst verstehen muss.
In TLS 1.3 wandert der Schlüsselaustausch aus dem Namen
Der erste Grund, warum X25519MLKEM768 nicht in der Cipher Suite steht, ist eine Änderung aus TLS 1.3. Dort ist der Schlüsselaustausch aus dem Suite-Namen herausgewandert. Eine TLS-1.3-Suite heißt nur noch TLS_AES_256_GCM_SHA384, also Verschlüsselung plus Hash. Vom Schlüsselaustausch steht da kein Wort mehr.
Stattdessen handeln Client und Server den Schlüsselaustausch separat aus, über die sogenannten Supported Groups. X25519MLKEM768 ist so eine Gruppe. Sie steht neben der Cipher Suite, nicht in ihr. Genau deshalb sitzt Post-Quantum an dieser Stelle: die Sache, die der Quantencomputer bedroht, ist der Schlüsselaustausch, und der wird in TLS 1.3 als eigene Gruppe verhandelt. Die Suite selbst bleibt unangetastet.
Warum überhaupt Post-Quantum?
Ein ausreichend großer Quantencomputer bricht mit dem Shor-Algorithmus die Mathematik hinter dem klassischen Schlüsselaustausch. Diffie-Hellman, RSA, die elliptischen Kurven: alles, was auf dem diskreten Logarithmus oder der Faktorisierung großer Zahlen beruht, fällt. Nicht ein bisschen schwächer, sondern gebrochen.
Die symmetrische Seite trifft es weit weniger hart. Gegen AES und die SHA-2-Familie hilft einem Quantencomputer nur der Grover-Algorithmus, und der halbiert lediglich die effektive Schlüssellänge. AES-256 verhält sich gegen Grover ungefähr so wie AES-128 gegen einen klassischen Rechner, und das ist weiterhin weit außerhalb des Machbaren. Deshalb muss der symmetrische Teil der Cipher Suite gar nicht ersetzt werden. Man nimmt die größere Variante, und die Sache ist erledigt. Nur der asymmetrische Schlüsselaustausch braucht wirklich Ersatz.
Der Haken ist der Zeitfaktor. Ein Angreifer, der heute Datenverkehr mitschneidet und wegspeichert, braucht den Quantencomputer nicht heute. Er kann warten. Kommt die Maschine in zehn oder fünfzehn Jahren, entschlüsselt er den alten Mitschnitt rückwirkend. Man nennt das harvest now, decrypt later. Für alles, was auch in fünfzehn Jahren noch vertraulich sein soll, ist die Bedrohung damit schon heute real. Das ist der Grund, warum man nicht wartet, bis es den Quantencomputer gibt.
Was ist ein KEM, und wie unterscheidet es sich von Diffie-Hellman?
Bevor wir den Namen zerlegen, ein Begriff, den man dafür braucht. Diffie-Hellman, auch in seiner elliptischen Variante ECDHE, funktioniert symmetrisch: beide Seiten werfen einen öffentlichen Wert in die Leitung, jede rechnet mit ihrem eigenen geheimen Wert und dem öffentlichen der Gegenseite, und am Ende haben beide dasselbe gemeinsame Geheimnis heraus. Verschickt hat es niemand, es entsteht auf beiden Seiten gleichzeitig.
Ein KEM, ein Key Encapsulation Mechanism, geht anders vor. Es kennt drei Schritte. Eine Seite erzeugt ein Schlüsselpaar und schickt den öffentlichen Teil. Die andere Seite führt mit diesem öffentlichen Schlüssel die Encapsulation aus. Dabei entstehen in einem Schritt zwei zusammengehörige Dinge: ein frisches gemeinsames Geheimnis und ein Chiffretext dazu. Der Chiffretext geht zurück. Die erste Seite entkapselt ihn mit ihrem privaten Schlüssel und hält dasselbe Geheimnis in der Hand. Encapsulate und Decapsulate, daher der Name.
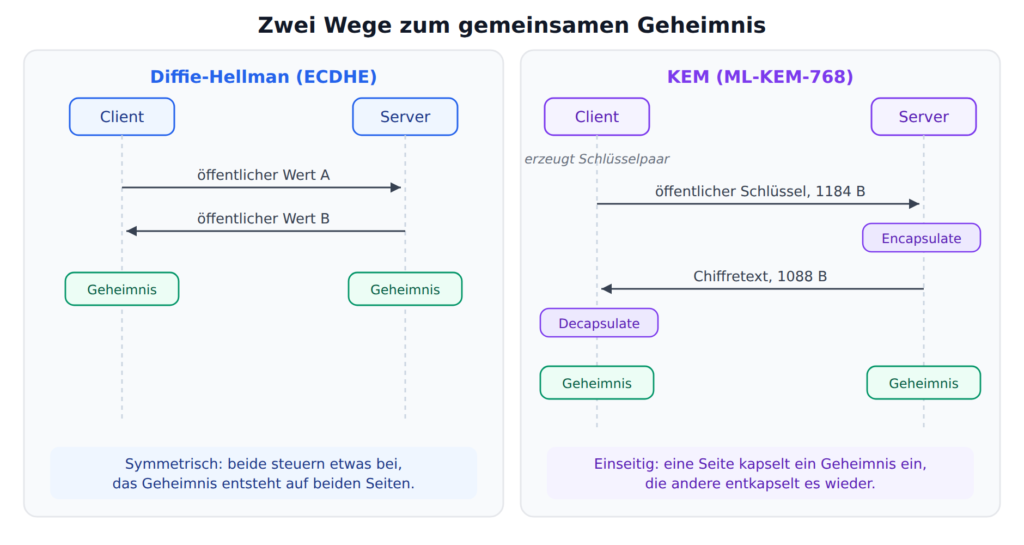
Im TLS-Handshake ist die Rollenverteilung dabei klar. Der Client erzeugt das ML-KEM-Schlüsselpaar und legt den öffentlichen Schlüssel in sein key_share, also gleich in den ClientHello. Der Server nimmt diesen Schlüssel, kapselt ein frisches Geheimnis ein und schickt den Chiffretext in seinem ServerHello zurück. Der Client entkapselt ihn und beide haben dasselbe Geheimnis. Genau deshalb ist es der 1184 Byte große öffentliche Schlüssel, der den ClientHello aufbläht, und nicht der Chiffretext. Klein bleibt der ServerHello damit trotzdem nicht: dort steckt der 1088 Byte lange ML-KEM-Chiffretext plus der 32 Byte lange X25519-Anteil. Beide Seiten schleppen also einen großen hybriden Share. Der Client-Share ist mit 1216 Byte nur rund 96 Byte größer als der 1120 Byte große Server-Share.
Warum nicht einfach Diffie-Hellman mit einem quantensicheren Verfahren? Weil die gitterbasierte Mathematik, auf der ML-KEM beruht, sich nicht sauber in das symmetrische DH-Schema pressen lässt. Die KEM-Form passt zu dem, was Gitter gut können: etwas einkapseln und wieder herausholen. Deshalb ist der neue Standard ein KEM und kein neues Diffie-Hellman. Wer die Denke von ECDHE im Kopf hat, muss hier einmal umschalten.
Der klassische Teil: X25519
Jetzt zum Namen selbst. X25519 ist der Teil, den es schon lange gibt. Es ist Diffie-Hellman über der elliptischen Kurve Curve25519, schnell, seit Jahren im breiten Einsatz und gründlich untersucht. In einer klassischen TLS-1.3-Verbindung macht X25519 den Schlüsselaustausch ganz allein. Sein öffentlicher Anteil ist mit 32 Byte winzig, die Rechnung ist billig, und in Sachen Vertrauen hat es sich über Jahre bewiesen.
Sein einziges Problem ist der Quantencomputer. Gegen Shor hält X25519 nicht. Es allein weiterzuverwenden hieße, sich genau der harvest-now-Bedrohung auszuliefern. Es einfach wegzuwerfen wäre aber auch schade, denn es ist bewährt. Diese Spannung löst der zweite Teil.
Der Post-Quantum-Teil: ML-KEM-768
MLKEM768 ist der neue Teil. ML-KEM steht für Module-Lattice-Based Key Encapsulation Mechanism, das quantensichere KEM, das die NIST im August 2024 als FIPS 203 standardisiert hat. Wem der Name CRYSTALS-Kyber etwas sagt: das ist der Vorgänger, ML-KEM ist die standardisierte Fassung davon.
Die Sicherheit von ML-KEM beruht nicht auf dem diskreten Logarithmus, sondern auf Gitterproblemen, konkret auf dem Module-LWE-Problem. Das ist eine ganz andere mathematische Baustelle, und nach heutigem Kenntnisstand hilft auch ein Quantencomputer dort nicht weiter. Die 768 im Namen ist keine Byte-Angabe, sondern der Parametersatz. Er ist der NIST-Sicherheitskategorie 3 zugeordnet, deren Referenzniveau sich grob am Aufwand eines Angriffs auf AES-192 orientiert. Eine exakte Zahl wie 192 Bit sollte man daraus aber nicht ableiten, die Kostenmodelle für Gitterangriffe und klassische Schlüsselsuche sind nicht dasselbe. Kategorie 3 ist der übliche Mittelweg zwischen dem kleineren ML-KEM-512 und dem größeren ML-KEM-1024.
Man muss die Gittermathematik nicht beherrschen, um die Grundidee zu greifen. Grob gesagt versteckt ML-KEM sein Geheimnis in einem System aus vielen Gleichungen, dem absichtlich ein kleines Rauschen beigemischt wurde. Ohne den privaten Schlüssel lässt sich das Rauschen nicht sauber herausrechnen, und den richtigen Wert trotzdem zu finden, gilt auch für einen Quantencomputer als hart. Shor greift hier ins Leere, weil es weder um Faktorisierung noch um diskrete Logarithmen geht. Das ist der ganze Trick: eine Härte, für die keine Quanten-Abkürzung bekannt ist.
Interessant sind die Größen. Der öffentliche Schlüssel von ML-KEM-768 ist 1184 Byte groß, der Chiffretext 1088 Byte. Zum Vergleich: der X25519-Anteil misst 32 Byte. Das gemeinsame Geheimnis, das am Ende herausfällt, ist bei beiden gleich klein, nämlich 32 Byte. Der Zugewinn an Sicherheit steckt also nicht im Ergebnis, sondern im Aufwand, es auszuhandeln. Diese Größe wird später noch wichtig.
Warum beide zusammen? Der Hybrid-Gedanke
Das Entscheidende an X25519MLKEM768 ist, dass beide Verfahren zugleich laufen. Es ist ein hybrider Schlüsselaustausch. X25519 liefert ein gemeinsames Geheimnis, ML-KEM-768 liefert ein zweites. Diese beiden Geheimnisse werden aneinandergehängt und wandern gemeinsam in den Schlüsselplan von TLS 1.3, also durch die HKDF-Ableitung, aus der am Ende die eigentlichen Sitzungsschlüssel fallen.
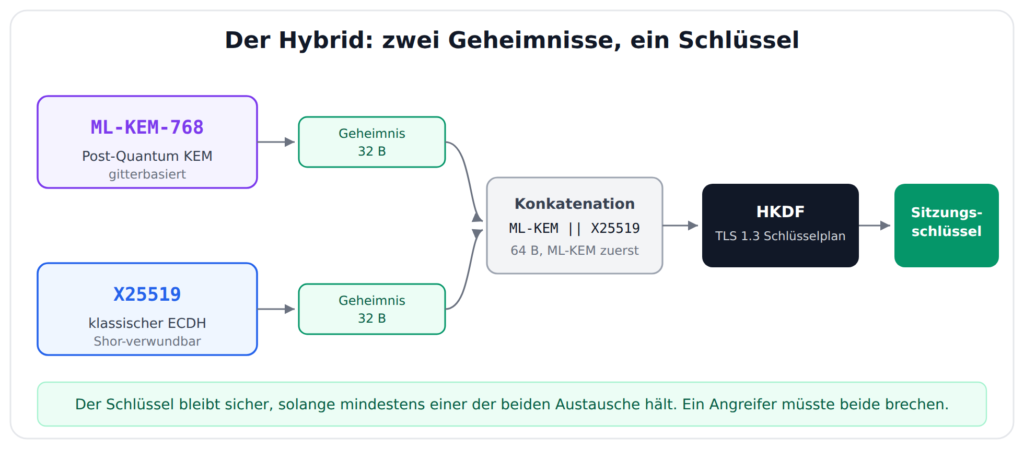
So, wie es für X25519MLKEM768 in TLS 1.3 standardisiert ist, bleibt das Ergebnis sicher, solange mindestens einer der beiden Schlüsselaustausche sicher ist. Erst wenn ein Angreifer beide bricht, fällt der Schlüssel. Diese Garantie hängt allerdings an der sauberen Einbindung in den TLS-1.3-Schlüsselplan, bloßes Aneinanderhängen zweier Geheimnisse ist nicht in jedem Protokoll automatisch sicher. Und das ist der ganze Sinn der Übung. ML-KEM ist quantensicher, aber noch jung. Sollte in der Gitterkryptografie doch eine Schwäche gefunden werden, hält immer noch das klassische X25519 die Stellung. Sollte umgekehrt der Quantencomputer kommen, fällt X25519, aber ML-KEM trägt weiter. Man müsste beide gleichzeitig knacken, und das ist mit heutigem Wissen für keine der beiden Seiten in Sicht. Man bekommt die neue Sicherheit, ohne die alte aufzugeben.
Kleine Kuriosität am Rande: im Namen steht X25519 vorne, auf dem Draht und bei der Kombination der Geheimnisse liegt der ML-KEM-Teil zuerst. Der Name folgt einer Konvention, die Byte-Anordnung einer anderen. Fürs Verständnis ist das egal, für eine eigene Implementierung nicht. Der allgemeine Rahmen für hybride Schlüsselaustausche in TLS 1.3 ist übrigens inzwischen als RFC 9954 veröffentlicht. Der konkrete Codepoint X25519MLKEM768 mitsamt seiner genauen Kodierung steckt dagegen noch in einem eigenen Entwurf, draft-ietf-tls-ecdhe-mlkem, den die TLS-Arbeitsgruppe im März 2025 angenommen hat. Zum Zeitpunkt dieses Beitrags ist dieser Teil noch kein veröffentlichtes RFC, er liegt aber schon beim RFC Editor. Im echten Datenverkehr ist er trotzdem längst unterwegs.
Der Preis: der Handshake wird größer
Die 1184 Byte haben eine Nebenwirkung. Ein klassischer ClientHello passt bequem in ein Paket. Packt man den ML-KEM-Schlüssel dazu, wird es eng, und manche fehlerhaften Middleboxes oder ältere Mailserver kommen mit dem größeren ClientHello nicht klar. Bei HTTPS bricht der TLS-Handshake dann in der Regel einfach ab, einen automatischen Rückfall auf Klartext gibt es dort nicht. Kritischer sind opportunistische Protokolle wie SMTP mit STARTTLS: dort kann, je nach lokaler TLS-Policy, nach einem gescheiterten TLS-Versuch tatsächlich unverschlüsselt weiter zugestellt werden. Das ist aber eine Eigenschaft des Anwendungsprotokolls und seiner Policy, nicht von TLS selbst.
Standardmäßig schickt OpenSSL 3.5 den hybriden Schlüssel gleich im ersten ClientHello mit, X25519MLKEM768 ist dort als vorhergesagter Key Share vorgesehen. Genau deshalb passt der ClientHello unter Umständen nicht mehr in ein einzelnes TCP-Segment. Wer das vermeiden will, kann Delayed Key-Share konfigurieren: der Client bietet die Gruppe dann zwar in den Supported Groups an, schickt den großen Share aber noch nicht mit. Bevorzugt der Server sie, fordert er ihn per HelloRetryRequest nach, was eine zusätzliche Rundreise kostet. Bei Postfix habe ich genau diesen Weg über das vorangestellte Fragezeichen in der Kurvenliste eingerichtet und auf dem Draht mit tcpdump nachvollzogen. Der Link steht unten. Für das Verständnis des Namens reicht: der Post-Quantum-Teil ist groß, und der Handshake muss sich darauf einstellen.
Was hier nicht post-quantum ist: die Authentisierung
Ein Punkt wird gern übersehen. X25519MLKEM768 schützt den Schlüsselaustausch, nicht die Authentisierung. Dass man wirklich mit dem richtigen Server spricht und nicht mit jemandem in der Mitte, hängt an zwei klassischen Signaturen. Die Zertifikatskette ist von der CA mit ECDSA oder RSA signiert, und der Server beweist zusätzlich im Handshake mit einer eigenen Signatur über das Transkript, dem CertificateVerify, dass er den passenden privaten Schlüssel besitzt. Beide sind heute noch klassisch, an dieser Stelle steckt also weiterhin nichts Quantensicheres.
Das ist kein Versehen, sondern eine Frage der Reihenfolge. Die quantensicheren Signaturverfahren gibt es durchaus, ML-DSA und SLH-DSA sind standardisiert. Nur bekommt man praktisch von keiner öffentlichen CA heute ein post-quantum signiertes Zertifikat. Die ganze Kette aus Wurzel, Zwischenzertifikat und Serverzertifikat müsste mitziehen, Browser und Betriebssysteme müssten die neuen Wurzeln kennen, und das dauert Jahre.
Warum ist das trotzdem vertretbar? Weil die Bedrohung bei der Server-Authentisierung im TLS-Handshake eine andere ist. Diese Signatur muss vor allem in dem Moment halten, in dem die Verbindung aufgebaut wird. Ein Quantencomputer in fünfzehn Jahren kann eine damals abgeschlossene Verbindung nicht rückwirkend fälschen, sie ist längst vorbei. Harvest now, decrypt later trifft also die Vertraulichkeit, nicht die Echtheit eines vergangenen Handshakes. Andere Signaturen, etwa unter Dokumenten oder Firmware, müssen dagegen oft noch Jahrzehnte halten, das ist ein eigener Fall. Deshalb ist der Schlüsselaustausch das dringende Problem und darf zuerst quantensicher werden. Die Signaturen kommen später, und dafür bleibt mehr Zeit.
Und in der Praxis?
Das alles klingt nach Zukunft, ist aber längst Gegenwart. Ich habe über fünfzehn Tage mitgeloggt, welche Gruppe die Clients auf diesem Blog tatsächlich aushandeln. Ergebnis: rund 57 Prozent aller Handshakes liefen bereits über X25519MLKEM768, bei aktuellen Browsern waren es um die 77 Prozent. Das ist kein Laborwert, sondern normaler Besucherverkehr. Der Schlüsselaustausch, den ich hier zerlegt habe, ist für den Großteil der Verbindungen zu dieser Seite schon der Normalfall.
Sehen kann man das selbst mit einem Blick von außen. Ein openssl s_client -connect host:443 zeigt in seiner Ausgabe die ausgehandelte Gruppe, und wenn dort X25519MLKEM768 steht, dann läuft genau der hybride Schlüsselaustausch, den wir hier auseinandergenommen haben. Auf der Serverseite kann man dieselbe Information über die Log-Variable $ssl_curve mitschreiben, was ich für die Auswertung unten genau so gemacht habe.
Wer das selbst einrichten will, muss vor allem eines wissen: es hängt an der Krypto-Bibliothek, also an OpenSSL 3.5 oder neuer, nicht am Webserver oder Mailserver selbst. Die konkreten Anleitungen für nginx sowie für Postfix und Dovecot habe ich getrennt aufgeschrieben, dazu die Auswertung, aus der die Zahlen oben stammen. Die Links stehen gleich hier drunter.
Kurz zusammengefasst
X25519MLKEM768 ist kein Tippfehler und kein Buzzword, sondern eine saubere Konstruktion. Ein klassischer Schlüsselaustausch und ein quantensicherer laufen parallel, ihre Geheimnisse werden zusammengeführt, und der Handshake ist nur zu knacken, wenn beide fallen. Der symmetrische Teil der Verbindung bleibt klassisch, weil er es sich leisten kann. Die Authentisierung bleibt vorerst auch klassisch, weil sie nicht so eilt. Und wenn man den Namen einmal an der richtigen Stelle auseinandernimmt, steht da nichts Geheimnisvolles mehr, sondern genau das, was drinsteckt.
Siehe auch
- TLS-ECDHE mit AES-256-GCM-SHA384, was bedeutet das eigentlich, die klassische Variante dieser Zerlegung
- Post-Quantum TLS für nginx auf FreeBSD 15, die praktische Einrichtung im Web
- Post-Quantum TLS für E-Mail mit Postfix und Dovecot, dasselbe für den Mailserver
- Postfix 3.11.1 mit OpenSSL 3.5, mit dem genauen Blick auf Delayed Key-Share und HelloRetryRequest
- 15 Tage $ssl_curve ausgewertet, wo die 57 Prozent herkommen
Etwas unklar geblieben, anderer Meinung oder eine Ergänzung? Gern einfach fragen.