Seit bestimmt zehn Jahren steht hier ein Voltcraft Charge Manager CM 2016 auf dem Schreibtisch. Irgendwann bei Conrad gekauft, als die tatsächlich noch Geschäfte in der Innenstadt hatten. Damals mit zwei kleinen Kindern war der Akkuverbrauch enorm. Spielzeugautos, Taschenlampen, Fernbedienungen, irgendwas war immer leer. Einwegbatterien waren teurer als heute (zumindest in meiner Erinnerung), und so wurde das Ladegerät schnell zum wichtigsten Gerät im Haushalt.
Das CM 2016 hat sechs unabhängige Ladeschächte (vier für AA/AAA, zwei für 9V-Blöcke) und kann deutlich mehr als nur Laden. Es misst Kapazitäten, erkennt defekte Akkus, kann Lade-/Entladezyklen fahren und hält Akkus per Trickle-Charge am Leben. Wer seine Akkus ernsthaft pflegen will, braucht so ein Gerät. Damit halten die Zellen länger, man kann sie wiederaufbereiten und erkennt rechtzeitig, wann einer reif für die Tonne ist.

In den letzten Jahren wurde es zugegebenermaßen weniger eingesetzt. Trotzdem laufen noch immer diverse Smarthome-Geräte und Notfall-Taschenlampen mit Akkus, und da ist ein ordentliches Ladegerät einfach Pflicht.
Das Problem: kein Linux, kein gar nichts
Das CM 2016 kommt mit einer Windows-Software. CM2016 Logger V2.10, eine .NET-Anwendung von 2013. Unter Linux funktioniert die selbstverständlich nicht. Es gibt ein paar Projekte, die das Gerät auf der Kommandozeile auslesen können, ein Java-Tool hier, ein Python-Script dort. Eine echte GUI für Linux oder FreeBSD? Fehlanzeige. Selbst als ich vor ein paar Tagen noch einmal gesucht habe: nichts. Eine kommerzielle Java-GUI existiert zwar, aber nur als 30-Tage-Trial.
Also habe ich mich selbst daran gesetzt.
Das Ergebnis: eine native GTK4-Anwendung
Das Ergebnis ist eine vollständige Desktop-Anwendung in Python mit GTK4 und libadwaita. Quelloffen, MIT-lizenziert, auf GitHub:
https://github.com/Kernel-Error/voltcraft-cm2016
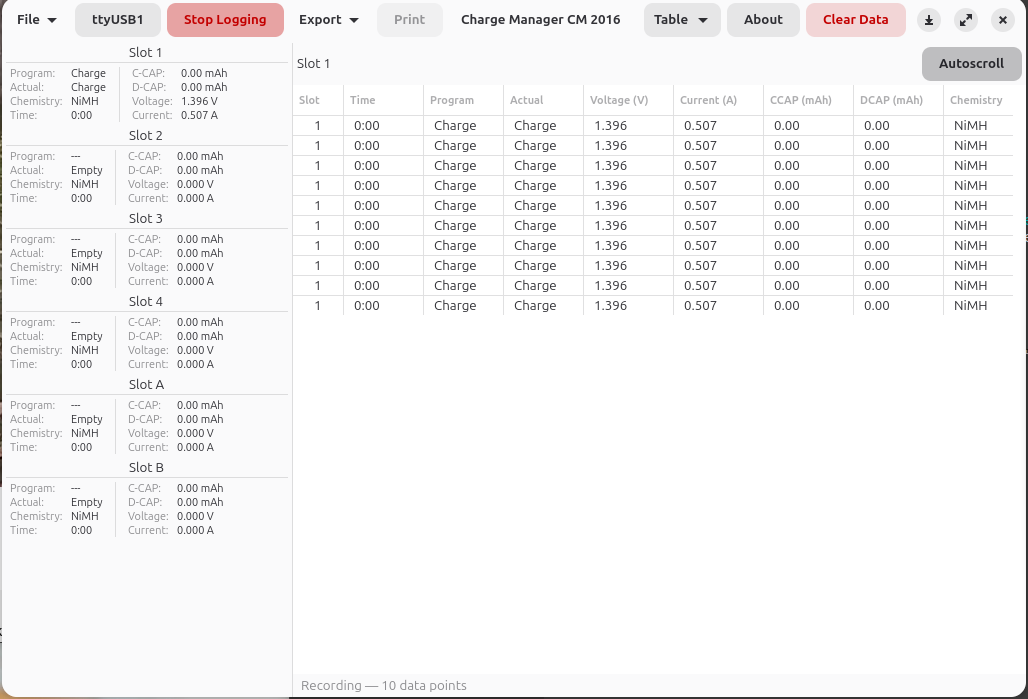
Die App erkennt das CM 2016 automatisch per USB (Silicon Labs CP210x Chip) und zeigt alle sechs Schächte in Echtzeit an. Alle zwei Sekunden kommen neue Messdaten rein: Spannung, Strom, Kapazität, Laufzeit, Programmstatus.
Was die App kann
- Echtzeit-Überwachung aller 6 Ladeschächte mit Autoscroll und Slot-Filterung
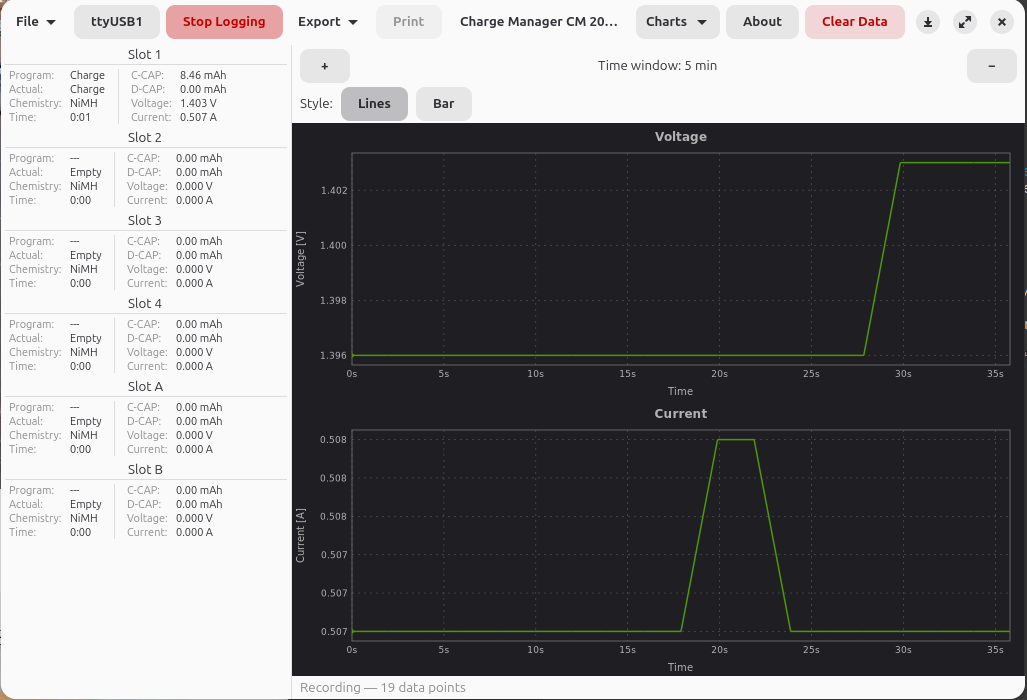
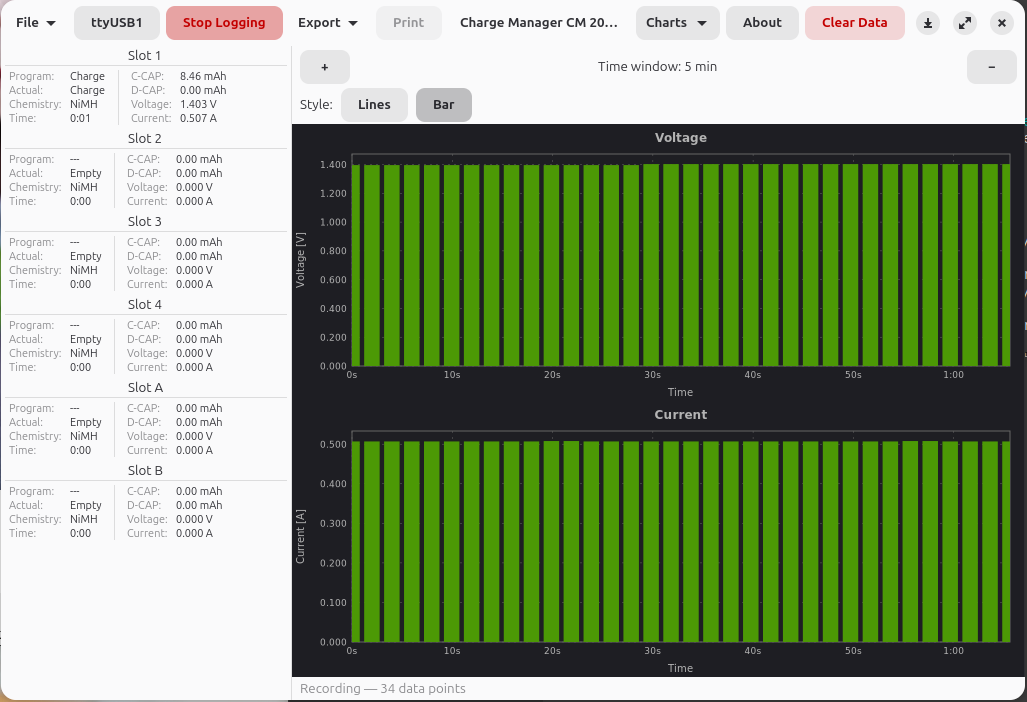
- Spannungs- und Strom-Diagramme als Linien- oder Balkendiagramm mit Zeitfenster-Steuerung
- Chart-Zoom per Maus-Drag, Scrollrad oder Tastatur, dazu Daten-Tooltips
- Export als CSV oder Spreadsheet (.xlsx mit eingebetteten Diagrammen)
- Druckfunktion für Messprotokolle im DIN A4 Querformat
- Speichern und Laden von Aufzeichnungen (.cm2016 Dateien), inklusive Crash-Recovery über Temp-Dateien
- Sleep-Inhibit: das System schläft nicht ein, solange aufgezeichnet wird
- 7 Sprachen: Deutsch, Englisch, Französisch, Niederländisch, Italienisch, Spanisch, Polnisch
Das Protokoll: nicht ganz so dokumentiert wie gedacht
Das CM 2016 sendet alle zwei Sekunden einen 127-Byte-Frame über die serielle Schnittstelle (19200 Baud, 8N1). Die ersten sieben Bytes sind immer CM2016 , dann folgen zehn Bytes Header und je 18 Bytes pro Ladeschacht.
Klingt einfach. Ist es auch, bis man die existierende Dokumentation mit echten Messdaten vergleicht. Dabei sind mir ein paar Dinge aufgefallen, die so nirgendwo korrekt dokumentiert waren:
- Kapazitätsfelder sind 32-Bit Little-Endian, nicht 24-Bit wie es in mehreren Quellen steht. Charge-Capacity und Discharge-Capacity belegen jeweils vier Bytes.
- Der dokumentierte Byte-Swap für Discharge-Capacity war falsch. Mehrere Referenzprojekte haben die Bytes in der falschen Reihenfolge gelesen, was zu absurden Kapazitätswerten geführt hat.
- Die Header-Bytes 7-16 waren bisher größtenteils undokumentiert. Tatsächlich stecken da die Firmware-Version, die eingestellte Akku-Chemie (NiMH/NiZn), Temperaturdaten und ein Action-Counter drin. Alles Big-Endian, im Gegensatz zu den Slot-Daten, die Little-Endian sind.
- Die Kapazitätsskalierung hängt vom Slot-Typ ab: Slots 1-4 (AA/AAA) teilen durch 100, die beiden 9V-Slots teilen durch 1000. Gleiches gilt für den Strom: AA/AAA-Slots durch 1000, 9V-Slots durch 10000.
Das alles musste mit dem echten Gerät verifiziert werden. Akku rein, verschiedene Programme durchlaufen lassen, Rohwerte mit dem Display vergleichen. Klassisches Reverse Engineering, nur eben mit Ladeströmen statt mit Netzwerkpaketen.
Technik unter der Haube
Die Anwendung nutzt GTK4 mit libadwaita für eine zeitgemäße GNOME-Oberfläche. Dark Mode funktioniert automatisch. Die Diagramme werden mit Cairo gerendert, Benachrichtigungen laufen über den libadwaita ToastOverlay. Für den seriellen Zugriff kommt pyserial zum Einsatz, die CP210x-Erkennung läuft über die USB Vendor/Product ID von Silicon Labs.
Der Spreadsheet-Export erzeugt .xlsx-Dateien mit eingebetteten Diagrammen über openpyxl. Die Druckfunktion generiert DIN A4 Querformat mit allen Slots und Diagrammen. Sessions lassen sich als .cm2016-Dateien speichern und wieder laden, und falls die Anwendung während einer Aufzeichnung abstürzt, gibt es eine automatische Recovery über Temp-Dateien.
Insgesamt 135 Unit-Tests decken Parser, Protokoll und die Export-Funktionen ab.
Installation
Die App braucht GTK 4.14+ und libadwaita 1.5+. Unter Debian/Ubuntu/Mint:
sudo apt install python3-gi python3-gi-cairo gir1.2-gtk-4.0 gir1.2-adw-1 git clone https://github.com/Kernel-Error/voltcraft-cm2016.git cd voltcraft-cm2016 python3 -m venv --system-site-packages .venv source .venv/bin/activate pip install -e .
Unter Fedora:
sudo dnf install python3-gobject gtk4 libadwaita
Unter Arch:
sudo pacman -S python-gobject gtk4 libadwaita
Dann einfach cm2016 starten, USB-Kabel anschließen, fertig.
Ein .deb-Paket gibt es auf der GitHub Releases Seite. Ein Flatpak-Manifest liegt im Repository, die Einreichung bei Flathub ist eingereicht.
Falls jemand das gleiche Gerät hat und Fragen zur App oder zum Protokoll hat, einfach fragen.
Siehe auch: NB-2033-U: Reverse Engineering eines Fingerabdrucklesers für Linux










 Der OpenSolaris fork Openindiana und gPodder
Der OpenSolaris fork Openindiana und gPodder