WordPress hat seit Jahren das wunderbare wordpress-activitypub von Matthias Pfefferle und Automattic. Damit wird ein WordPress-Blog zu einem nativen Mastodon-Account, jeder Beitrag landet in den Timelines der Follower, Likes und Reposts kommen zurück. Für Grav gab es genau das nicht. Die Website meiner Frau läuft auf Grav, sie schreibt hin und wieder fachlich, und seit längerem wollte ich diesen Blog vernünftig ins Fediverse bringen. Bisher half feed2toot, also RSS in Mastodon-Posts übersetzt, das funktioniert zwar, ist aber kein ActivityPub. Keine Profilseite, keine Follower-Beziehung, kein nativer Hashtag-Index, keine saubere Article-Card. Also will ich versuchen selbst etwas zu schreiben. Das Ergebnis heißt grav-plugin-fediverse-publisher, ist seit ein paar Tagen als v0.1.0 draußen und läuft auf ihrer Webseite produktiv.
Das Repo liegt auf GitHub unter Kernel-Error/grav-plugin-fediverse-publisher (MIT). Release v0.1.0 inklusive Changelog gibt es hier. Eine Vorstellung mit Bitte um Feedback liegt im Grav-Discourse-Forum: I tried to build an ActivityPub plugin for Grav.
Warum überhaupt, und warum jetzt
Im Grav-Forum gibt es einen Thread aus dem Jahr 2019: Grav & ActivityPub. Dort hat über sechs Jahre hinweg dreimal jemand explizit nach genau dieser Funktion gefragt. Antworten gab es kaum, Code gar nicht. Das ist die Sorte Lücke die ich charakteristisch finde für kleinere Open-Source-Ökosysteme: alle finden es gut, niemand setzt sich hin. WordPress hatte über Jahre dieselbe Situation, bis Pfefferle das wordpress-activitypub-Plugin gebaut und Automattic später übernommen hat. Für Grav ist niemand vorbeigekommen.
Bei mir kam dazu, dass ich einen echten produktiven Anwendungsfall habe. Nicole, meine Frau, betreibt einen Grav-Blog im Rahmen ihrer weiteren Ausbildung. Inhaltlich vollkommen anders gelagert als alles was hier üblicherweise federiert, aber genau deshalb auch ein wertvoller Stress-Test: andere Zielgruppe, andere Empfängerinstanzen, anderes Hashtag-Vokabular. Wenn das Plugin dort sauber läuft, läuft es überall.
Phase 0: Machbarkeitscheck mit Scope-Disziplin
Bevor eine Zeile produktiver Code entstand, gab es eine Phase 0: gibt es die Lücke wirklich, ist das PHP-Bibliotheks-Ökosystem für ActivityPub brauchbar, und schaffe ich die langfristige Wartung als Solo-Entwickler? Verdikt: ja, aber nur als Broadcast-only-MVP. Konkret heißt das, der Blog kann senden, also Beiträge als Create-Activity an alle Follower-Inboxes ausliefern, sowie auf Standard-ActivityPub-Queries antworten (Actor-Profile, Outbox, Followers, NodeInfo, WebFinger, HTTP-Signaturen rein und raus). Nicht im Scope sind Replies als Kommentare zurück in Grav, Multi-Actor-Setups, Authorized Fetch und Theme-seitige Patches. Diese Disziplin durchzuhalten war im Verlauf ein paar Mal anstrengend, hat sich aber durchweg ausgezahlt.
Vor der ersten Code-Zeile entstanden vier ADRs (Architecture Decision Records) zu Storage, HTTP-Signaturen, asynchronem Push und Content-Negotiation. Diese ADRs habe ich zweimal kritisch gegenlesen lassen. In Runde zwei kamen drei Lücken zum Vorschein, die ich allein übersehen hätte. Die ungemütlichste: landrok/activitypub verifiziert beim Parsen verlinkter Objekte still im Hintergrund Netzwerk-I/O. Das hätte die gesamte SSRF-Härtung des Inbound-Pfads ausgehebelt. Konsequenz: landrok nur für die Erzeugung von AS-2.0-Objekten und WebFinger benutzen, der gesamte sicherheitsrelevante Inbound-Pfad geht nicht mehr durch landrok. Phpseclib übernimmt die Krypto direkt, der HTTP-Signature-Verifier ist eigene Implementierung. Insgesamt sind über die ADR-Reviews und ein nachgelagertes Review der ersten Implementierung acht sicherheitsrelevante Fixes eingeflossen, bevor das Plugin produktiv ging.
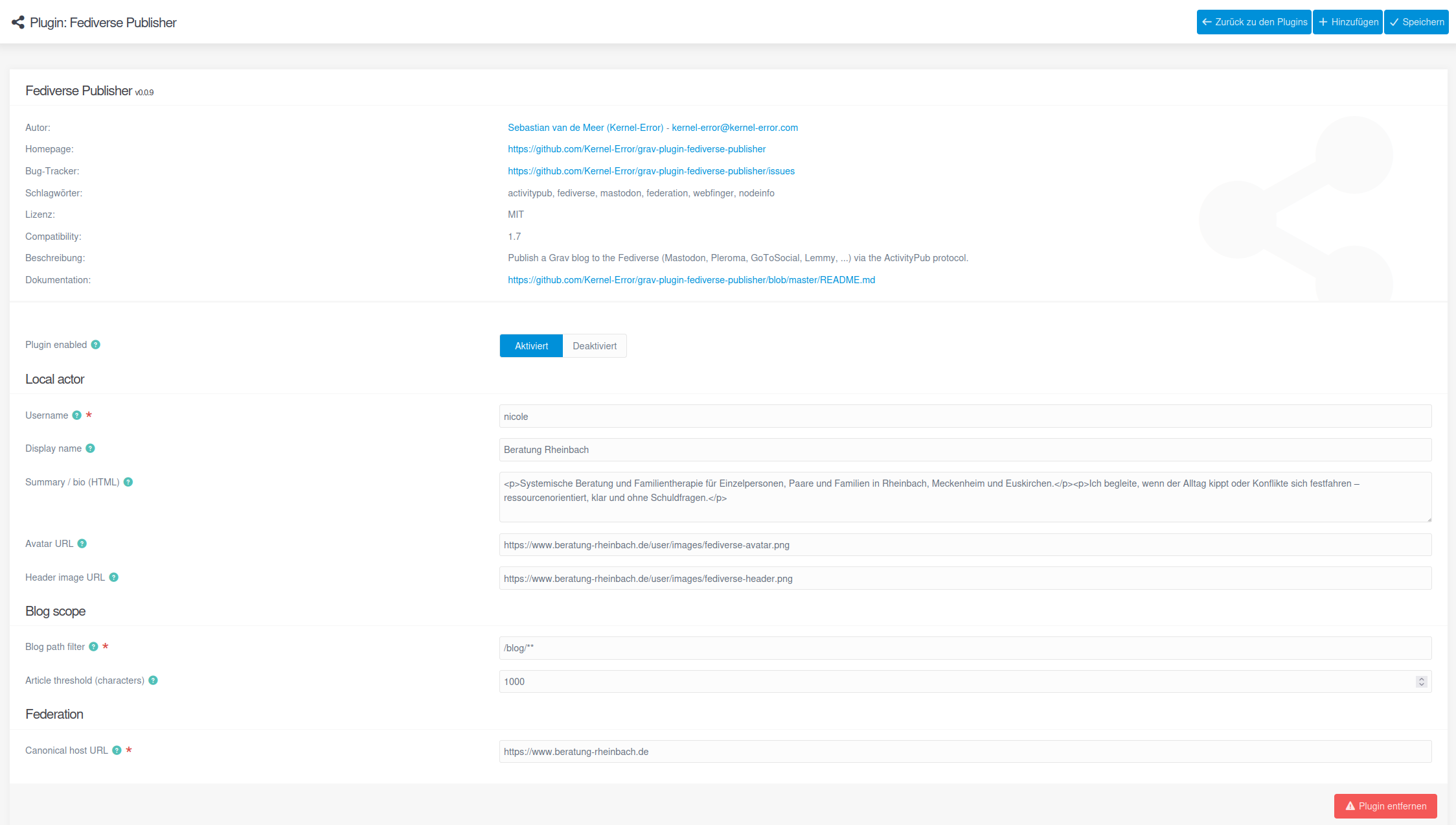
Stack-Entscheidungen
Die wichtigsten Bauklotz-Entscheidungen in Stichworten:
landrok/activitypubfür die AS-2.0-Objekte und WebFingerphpseclib/phpseclibfür die Krypto direkt, ohne Umweg über landrok auf dem Inbound-Pfad- HTTP-Signaturen nach
draft-cavage-12, für Sign und Verify selbst implementiert - SQLite per PDO im WAL-Modus für Follower-Tabelle und Push-Queue
- Synthetic Endpoints via
onPluginsInitialized, ein Pattern ausgrav-plugin-form, mit PSR-7-Responses statt Symfony HttpFoundation - Outbound-Queue mit echtem Idempotenz-Anker per
INSERT OR IGNOREauf(activity_id, recipient_inbox) - Retry-Schedule 1m / 5m / 30m / 2h / 12h / 24h mit Jitter, Cap bei sieben Versuchen, danach
status='dead' - SSRF-gehärteter keyId-Fetch: HTTPS-only, Block privater IP-Bereiche, keine Redirects, 64 KiB Response-Cap, Negative-Cache
- Strikte Identity-Bindung:
keyId,publicKey.ownerundactivity.actormüssen nach Normalisierung auf dieselbe Actor-URL zeigen
Wer den vollen technischen Aufschrieb sucht, findet die ADRs als Markdown-Dateien im Repo unter docs/adr/. Die sind als Lese-Doku formuliert, nicht als Mitschrift.
Neun Iterationen in zwei Tagen, jede mit echtem Erkenntnisgewinn
Wenn jemand fragt, warum ein scheinbar geradliniges Plugin neun Patch-Versionen gebraucht hat: weil jede einzelne dieser Versionen eine echte Produktions-Erkenntnis war, die ich nicht in einem theoretischen Vorab-Design hätte antizipieren können. Hier in kompakt, weil die Liste für sich spricht:
- v0.0.1: Boot-Crash auf der Produktion. Composer hat
psr/logv3 reingezogen, Grav 1.7 bringt aber v1. Resultat: ganze Site HTTP 500, und das obwohl das Plugin noch gar nicht aktiviert war. Grav ruftautoload()bei jedem installierten Plugin schon beim Boot auf. - v0.0.2:
psr/logauf^1.1gepinnt, defensivestry/catchim Plugin-Entry, Preflight-Check via explizitemrequire_oncestatt Autoload-Pfad. - v0.0.3: SQL-Quoting-Falle. PHP 8.3 mit aktuellem libsqlite parst Double-Quoted-Strings als Identifier, nicht als String-Literale. Klassischer Fall, früh genug erkannt, danach konsequent Single-Quotes überall. Im selben Schritt das Listing-Page-Filter geschärft, dazu Actor-Endpoints fertig gemacht.
- v0.0.4: Router-Wiring vergessen. Die Routen für
followersundfollowingwaren im Code zwar vorhanden, aber nicht registriert. Mastodon zeigte hartnäckig „0 followers“ obwohl reale Follower in der DB lagen. Plus Diagnostics-Logging für Outbound-401-Antworten, damit ich die nächste Klasse von Bugs überhaupt sehen konnte. - v0.0.5: psr/log-Konflikt war tiefer als gedacht. Die Default-Einstellung
autoload(prepend=true)hat den Plugin-eigenen Vendor-Pfad über Grav 2.0s gebundeltespsr/logv3 gezogen, was unter Grav 2.0 in ganz neue Fehlerbilder kippte. Fix:prepend=false. Im selben Schritt ein neues, mandatorischescanonical_host-Config-Feld eingeführt, sonst signiert die Cron mal ebenkeyId=http://localhost/..., was kein Empfänger akzeptiert. Ab hier läuft im Dev parallel ein zweiter Container mit Grav 1.7.52 und PHP 8.3.31 (matcht die Produktion byte-genau). Dieser Dual-Grav-Stack fängt seitdem alle Bugs der Klasse „passt auf einer Major-Version, kracht auf der anderen“ lokal ab, statt sie über Nicole laufen zu lassen. - v0.0.6: AS-2.0-Spec-Violation. Bei rückdatierten Posts war
updated < published, was strenge ActivityPub-Implementierungen wie GoToSocial und Pleroma silently droppen. HTTP 202 vom Empfänger, aber kein Eintrag in der Timeline. Fix war eine Zeile Clamp, der Fehler dahinter aber lehrreich: ein 2xx-Status sagt zu Federation-Erfolg gar nichts. - v0.0.7: der echte Showstopper. Grav-Admin 1.10 und neuer routet Page-Saves nicht mehr durch
onAdminAfterSave, sondern durchonFlexAfterSave(über das Flex-Objects-Plugin). Folge: User speichert einen Beitrag im Admin, der Save feuert, das Plugin macht nichts, kein Queue-Eintrag, keine Federation. Im selben Release dann auch AS-2.0-Hashtag-Federation hinzugefügt. Hashtags sind in der Praxis der primäre Discovery-Pfad für einen Actor mit null Followern, weil Mastodons Hashtag-Index fremde Actors automatisch aufnimmt. Drittens kam ein neuesbroadcast:post-CLI-Kommando rein, das einen einzelnen Pfad in die Queue legt, für Recovery und Backfill. - v0.0.8: Hotfix nach Hotfix. Meine Diagnostik-Zeile in v0.0.7 hat
iterator_to_array($event)auf RocketThemes Event-Klasse aufgerufen. Die implementiertArrayAccess, aber nichtTraversable. Ergebnis:TypeErrorbei jedem Admin-Save, HTTP 500, Nicole sah eine 624 KB große Fehlerseite. Diese Klasse Bug ist genau die Sorte, die das „passt schon“-Gefühl belohnt. Fix:iterator_to_arrayraus, Logik in eine testbarePageSaveDiagnostics-Klasse extrahiert, 13 neue Unit-Tests die alle möglichen Event-Object-Shapes durchfuzzen. Wenn schon dasselbe Problem mehrfach, dann wenigstens mit Tests dagegen. - v0.0.9: stale Collection. Auch nach v0.0.8 hat der Broadcaster bei frischen Posts nicht gefeuert. Ursache:
$pages->find()arbeitet auf einem Pre-Save-Snapshot der Pages-Collection. Frisch gespeicherte Inhalte sind zu dem Zeitpunkt noch nicht drin. Fix: eine neuefindByPage(PageInterface)-Methode, die direkt das Event-Payload nimmt, statt durch die stale Collection zu spazieren. Plus per-bail INFO-Logging: jede Regression dieser Klasse ist seither ein einzigergrepentfernt von actionable. Mit v0.0.9 lief es dann durch, sauber, unter Last, an echten Followern auf realen Instanzen.
v0.1.0 ist im Wesentlichen v0.0.9 mit ehrlichem README, einem Changelog der die ganze Geschichte oben dokumentiert, und dem Vorstellungspost im Grav-Forum. Mir war wichtig, das Ding nicht als „stable“ zu vermarkten. Es ist Early Access, ich bin solo, ich brauche Tester.
Methodisch: drei Dinge die den Unterschied gemacht haben
Aus den neun Iterationen kann man ein paar Schlüsse ziehen, die ich selbst spannender finde als die einzelnen Bugs.
Erstens, der Dual-Grav-Dev-Stack. Zwei Container, derselbe Plugin-Source, einmal Grav 1.7.52 und einmal Grav 2.0 RC. Eingerichtet als Reaktion auf das psr/log-Drama in v0.0.5. Seitdem werden Bugs der Klasse „passt unter Major X, crasht unter Major Y“ lokal sichtbar, bevor sie Nicole erreichen. Das ist im Tagesgeschäft die langweiligste Investition, die ich gemacht habe, und gleichzeitig die wertvollste.
Zweitens, ein dedizierter Production-Feedback-Loop. Deployment und Smoke-Test auf der Live-Site liefen über einen sauber getrennten Track. Dort wird das Plugin installiert, gegen mastodon.social und bonn.social geprüft, eine Feedback-Notiz zurück in das Planungs-Verzeichnis geschrieben. Lokal wird daraufhin triagiert, gefixt, die Patch-Version gebumpt, gepusht. Beide Tracks haben klare Scopes: Deploy-Zugang und Auth bleiben dort wo das auch tatsächlich passiert, Architektur-Wissen und Code-Änderungen im anderen Bereich. Klingt nach Overhead, war aber der Grund, warum ich Bugs wie das onFlexAfterSave-Routing-Problem aus v0.0.7 überhaupt in akzeptabler Zeit gefunden habe: der Live-Blog war der Detektor, nicht meine lokale Dev-Maschine.
Drittens, externes Gegenlesen an sicherheitskritischen Stellen. HTTP-Signaturen, Inbox-Verifikation, SSRF-Härtung, Identity-Binding. Überall wo ein Fehler in einer realen Verwundbarkeit landet, ging der Code durch eine zusätzliche Review-Runde mit eigenem Blickwinkel. Vier potenzielle Regressionen sind dabei aufgefallen, die ich allein gemacht oder übersehen hätte. Ein zweites Augenpaar ersetzt kein Sicherheits-Audit, hebt aber das untere Drittel der „hätte mir auch auffallen können“-Klasse Fehler ziemlich zuverlässig nach oben.
Wie das für einen Mastodon-User aussieht
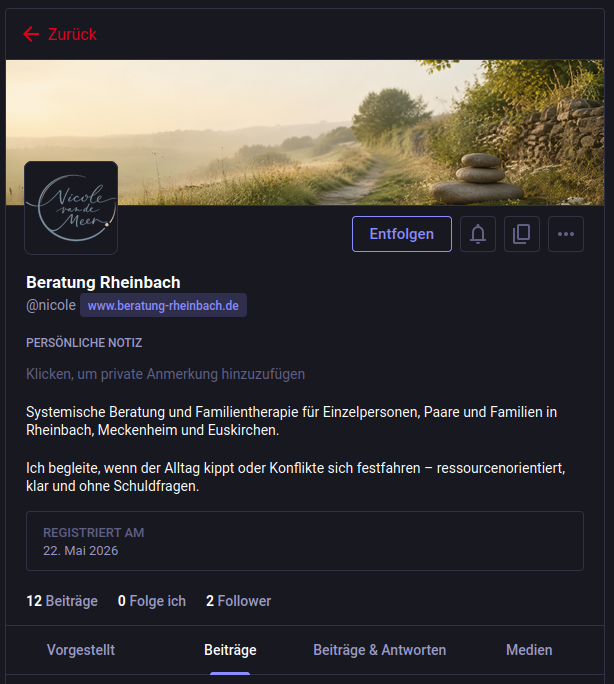
Genau das war das Ziel. Ein Mastodon-User abonniert @nicole@www.beratung-rheinbach.de, drückt auf Folgen, und sieht ab dem nächsten Beitrag jeden neuen Artikel direkt in der Home-Timeline. Avatar und Header werden gezogen, Bio steht da, die Profilseite zeigt alle bisher federierten Beiträge, und die Hashtags am Ende jedes Posts landen im Hashtag-Index der Empfängerinstanz. Letzteres ist nicht kosmetisch. Für einen Account mit null Followern ist der Hashtag-Index der primäre Discovery-Pfad, weil Mastodon dabei auch Posts fremder Actors mitnimmt, die zum gleichen Tag federieren.
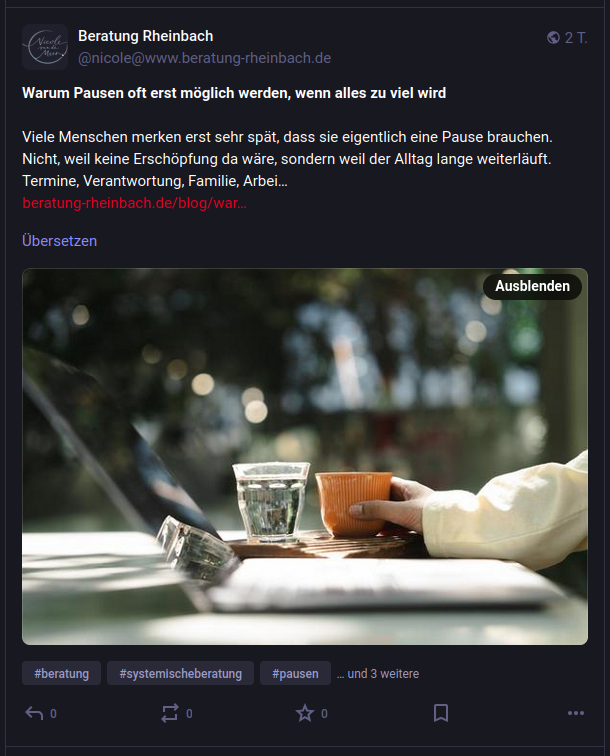
Die End-to-End-Latenz vom Speichern im Grav-Admin bis zur Anzeige in der Heimat-Timeline eines Followers liegt bei rund 15 Sekunden. Das ist der asynchrone Push aus der SQLite-Queue plus der üblichen ActivityPub-Delivery. Fällt eine Instanz aus, retryed das Plugin nach Schedule. Erreicht der Push nach sieben Versuchen kein 2xx, markiert die Queue den Eintrag als dead und lernt aus dem letzten Statuscode, ob die Instanz dauerhaft weg ist oder ob es nur ein vorübergehendes Problem war.
Was geplant ist, und was bewusst draußen bleibt
Roadmap für v0.2, ohne festes Datum:
Update-Activity bei Re-Saves. Auf Mastodon kosmetisch, für Pleroma und Misskey möglicherweise relevant, da diese die Post-Card neu ziehen.Delete-Federation. Aus Compliance-Sicht eine sinnvolle Komplettierung.push:purge-old-activitiesals Housekeeping-CLI, damit die SQLite-Datei nicht ewig wächst.- Breitere Peer-Tests gegen Friendica und Misskey, um die HTTP-Signatur-Verifikation gegen weitere Implementierungen abzusichern.
Was explizit nicht kommt, jedenfalls nicht als integraler Plugin-Bestandteil:
- Replies aus dem Fediverse als Kommentare zurück in den Grav-Blog. Sehr beliebte Wunschfunktion, aber sie sprengt das Broadcast-only-Scope und bringt eine ganze eigene Klasse von Spam-, Moderations- und Persistenz-Fragen mit, die ich nicht halbgar lösen will.
- Multi-Actor pro Grav-Instanz. Ein Blog ist ein Actor, fertig.
- Authorized Fetch. Ist aktuell ohnehin nur eine Untermenge der Mastodon-Welt, und die Kosten in Komplexität stehen nicht im Verhältnis zum Nutzen für ein Plugin in diesem Stadium.
- Theme-seitige Patches. Das Plugin hängt sich nicht in die Twig-Templates des Blogs.
Die nächsten Schritte sind bewusst reaktiv. Statt einer langen Vorab-Roadmap warte ich, was aus der Community zurückkommt. Erste Reaktion im Discourse-Thread: ein User schlägt Software-Release-Changelogs als zweiten Anwendungsfall vor. Anderer Content-Shape als ein normaler Blog-Broadcast, aber technisch derselbe Page-Save-zu-Create-Activity-Pfad. Notiert für v0.2. Im alten 2019er-Thread habe ich ebenfalls einen Cross-Link gesetzt, damit Leute die nach Grav und ActivityPub googeln in der ersten Trefferzeile beim Repo landen statt bei sechs Jahre alten Fragen ohne Antwort.
Ehrliche Einordnung
Das Plugin läuft, aber es läuft auf einer Grav-Instanz unter genau einer Konfiguration mit zwei test Followern auf zwei Mastodon-Instanzen. Das ist ein winziger Ausschnitt aus dem, was Fediverse so an Implementierungen, Versionen und Edge-Cases zu bieten hat. Ich habe gegen die ActivityPub-Spec implementiert, gegen die HTTP-Signature-Drafts gelesen und gegen Mastodons faktisches Verhalten validiert. Pleroma- und Misskey-Spezifika sind nur sekundär berücksichtigt, Friendica gar nicht. Wer das Plugin auf einer eigenen Grav-Installation ausprobiert und gegen seine Lieblings-Mastodon-Heimat-Instanz federiert, hilft mir mehr als jeder weitere Unit-Test, den ich allein schreiben kann.
Wenn etwas nicht läuft, ist ein Issue im Repo der direkteste Weg. Eine Antwort im Forum-Thread erreicht zusätzlich auch andere Grav-Anwender die womöglich Ähnliches sehen. Über die Kontaktseite hier auf dem Blog komme ich genauso an Mails.
Bleibt eine kleine Beobachtung für alle, die sich an ähnliche Projekte heranwagen. Zwei Tage Iterationen, neun Patch-Releases, ein Production-Inzident mit der 624-KB-Fehlerseite. Das ist genau der Realismus, den ein Plugin im ersten echten Einsatz mitbringt. Es wäre bequemer, das im Changelog wegzulassen und v0.1.0 als unbefleckte erste Veröffentlichung zu inszenieren. Mir war es wichtiger, die Story so zu erzählen, wie sie ablief, weil ich diesen Schreibstil bei anderen Open-Source-Projekten selbst sehr schätze.
Siehe auch: ts3level (anderes Solo-Projekt, andere Domain, gleicher Workflow).
Fragen, Kommentare, Bug-Reports, oder einfach Lust auf einen kurzen Austausch zum Plugin gerne über die fragen-Seite oder direkt als Issue im Repo.