Ich wollte wissen, wie gut sich Daten mit Linux-Bordmitteln wiederherstellen lassen. Also habe ich eine alte Festplatte genommen und es systematisch ausprobiert. Erst normal gelöschte Dateien, dann ein RAW-Image, und am Ende habe ich die Platte physisch zerstört, um zu sehen was ddrescue und PhotoRec aus den Trümmern holen.
Vorbereitung: Testplatte befüllen
Die älteste funktionierende Platte aus meinem Fundus: eine WD Expert 136BA. Erst komplett mit Nullen überschrieben, dann partitioniert und als NTFS formatiert:
dd if=/dev/zero of=/dev/sdb1 mkfs.ntfs -L TestDatenloeschung -T /dev/sdb1
Einen ca. 1,53 GB großen Ordner mit verschiedensten Dateien habe ich dann so lange auf die Platte kopiert, bis sie voll war.
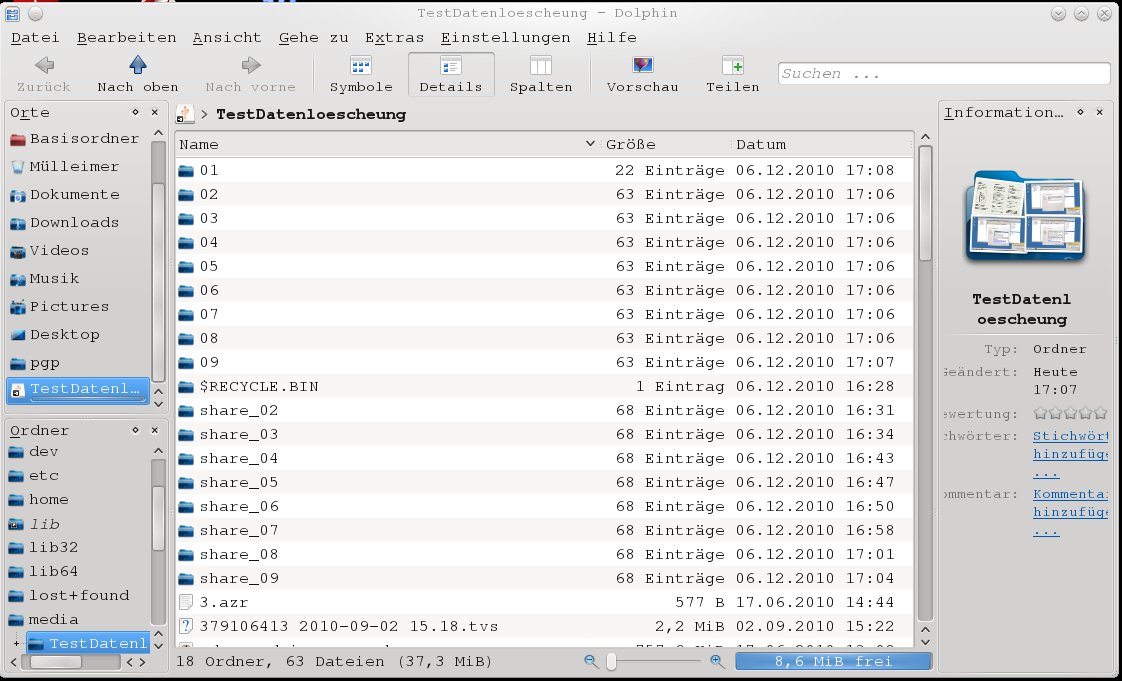
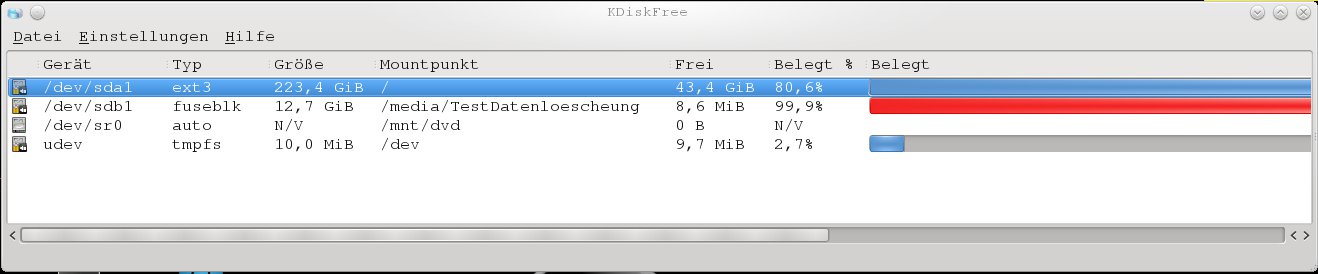
ntfsundelete: Gelöschte Dateien wiederherstellen
Erster Scan, noch ohne etwas gelöscht zu haben:
ntfsundelete -s /dev/sdb1 # Files with potentially recoverable content: 0
Logisch, es wurde ja noch nichts gelöscht. Also ein paar Dateien weg und erneut scannen:
ntfsundelete -s /dev/sdb1 # Files with potentially recoverable content: 154
154 Dateien. Jetzt die Wiederherstellung:
ntfsundelete /dev/sdb1 -u -m '*.*' -p 100 -d /test
Die Optionen: -u für Undelete-Modus, -m '*.*' für alle Dateien (mit -m '*.doc' könnte man nur Word-Dateien holen), -p 100 für nur zu 100 % wiederherstellbare Dateien, -d /test als Zielverzeichnis. Bei Bildern könnte man den Prozentsatz auch niedriger setzen, Teile eines JPEG sind besser als nichts.
Alle 154 Dateien kamen vollständig zurück. Einzige Einschränkung: Dateien mit gleichem Namen werden nicht überschrieben. Sollte man beachten oder per Script lösen.
Arbeiten mit RAW-Images
Im Ernstfall arbeitet man nie mit der Originalplatte. Sobald man den Datenverlust bemerkt, am besten sofort den Stecker ziehen. Jeder weitere Betrieb, selbst ein Herunterfahren, kann die gelöschten Daten überschreiben. Also erst ein RAW-Image ziehen:
dd if=/dev/sdb1 of=/001/TestRettung.img # 26709984+0 Datensätze ein # 13675511808 Bytes (14 GB) kopiert, 701,766 s, 19,5 MB/s
ntfsundelete funktioniert genauso mit dem Image-File. Gleiche Ergebnisse, gleiche Wiederherstellung. Genau so soll es sein.
Die Festplatte zerstören
Jetzt wird es interessant. Mich hat natürlich interessiert, was bei einer physisch beschädigten Platte passiert. Also Platte wieder voll gemacht und dann aufgeschraubt.


Vorsichtig ein paar Kratzer mit dem Schraubendreher auf die Magnetscheiben gesetzt. Nicht zu viel, aber genug, dass einige Gigabyte unlesbar sein sollten.



ddrescue: 52 Stunden an einer zerkratzten Platte
Platte wieder zugeschraubt und ddrescue drauf losgelassen:
ddrescue -n /dev/sdb1 /001/datenrettung.img /001/datenrettung.log ddrescue -d -n -r3 /dev/sdb1 /001/datenrettung.img /001/datenrettung.log
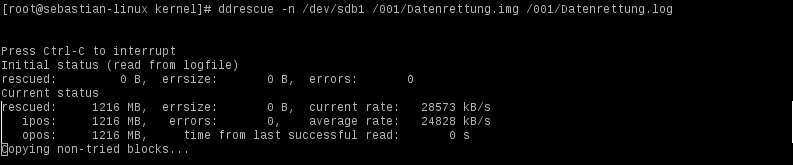
Nach meiner kleinen Kratzorgie hat ddrescue 52 Stunden an der Platte gefummelt, bevor es durch war.
Wann zum Profi?
Wenn einem die Daten mehr als 3.000 Euro wert sind, sollte man einen professionellen Datenretter aufsuchen. Die nehmen zur Diagnose oft um die 90 Euro und sagen dann, was es wirklich kostet. Bei einem Fall aus 2010 hat ein Kunde mit einer 160 GB HDD und Headcrash einen Kostenrahmen von 15.000 bis 18.000 Euro genannt bekommen. Jede Bewegung an der Platte kann weitere Daten zerstören.
Ich habe selbst mal bei einer Seagate SCSI-Platte die komplette Elektronik von einer baugleichen getauscht, weil sie keinen Spin-Up mehr machte. Lief danach wieder, als wäre nie etwas gewesen. Auch ein Tausch der Schreib-/Leseköpfe hat einmal funktioniert, nachdem einer halb abgerissen war. Die Platte sprang genau ein Mal an, ich konnte sichern, beim nächsten Versuch ging nichts mehr. Solche Experimente klappen nicht immer. Hat man an der Platte herumgefummelt, hat oft auch der Profi keine Chance mehr.
PhotoRec: Dateien anhand des Headers retten
Das ddrescue-Image ließ sich in meinem Fall nicht mehr mounten. Durch die Kratzer war auch das NTFS-Dateisystem total im Eimer, selbst fsck half nicht. Also brauchte ich ein Programm, das Dateien anhand ihres Headers wiederherstellen kann: PhotoRec.
photorec datenrettung_parti_sicher.img
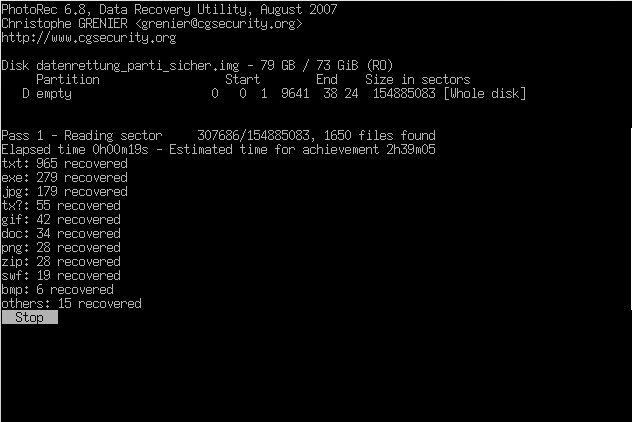
PhotoRec hat erstaunlich viele Dateien aus der zerkratzten Platte zurückgeholt. Wer sich das Programm anschaut, sollte sich auch TestDisk vom gleichen Entwickler ansehen. Damit lassen sich gelöschte Partitionen rekonstruieren und noch vieles mehr.
Fazit
Für normal gelöschte Dateien auf NTFS reicht ntfsundelete. Bei physischen Schäden ist ddrescue das Mittel der Wahl, um erst ein Image zu sichern. Und wenn das Dateisystem komplett zerstört ist, kann PhotoRec anhand der Datei-Header noch erstaunlich viel retten. Wichtigste Regel: Nie an der Originalplatte arbeiten, immer zuerst ein Image ziehen.
Fragen? Einfach melden.