
Wer eine TeamSpeak-3-Identity mit einem höheren Security Level haben möchte als das, was der offizielle Client innerhalb eines Menschenlebens rausrechnet, kommt um GPU-Hilfe nicht herum. Es gibt da seit Jahren eine Handvoll Drittanbieter-Tools. Was bisher fehlte, war der unspektakuläre letzte Schritt: das gefundene Ergebnis wieder in die .ini zu schreiben. Genau diese Lücke schließt ts3level, ein neues Open-Source-Tool, an dem ich die letzten Wochen gesessen habe.
Das Repo liegt auf GitHub unter Kernel-Error/ts-identities-security-level (MIT-Lizenz). Release v0.1.0 inklusive prebuilt Tarball für x86_64 Linux mit glibc ≥ 2.39 gibt’s hier. Der Tarball ist rund 2 MB groß, mehr braucht es nicht.
Das Problem: Single-Thread-CPU vs. exponentielles Wachstum
Das „Security Level“ einer TS3-Identity ist nichts anderes als ein Proof-of-Work. Man variiert einen uint64-Counter und hashed solange SHA1(pubkey_b64 || decimal(counter)) bis vorne genug Null-Bits stehen. Pro Level verdoppelt sich der durchschnittliche Aufwand. Der offizielle TS3-Client rechnet das in einem einzelnen CPU-Thread. Ab ungefähr Level 50 wird das schlicht unbrauchbar.
Es gibt seit Jahren GPU-beschleunigte Drittanbieter-Hasher. landave/TSIdentityTool ist die CPU-Referenz in C, mittlerweile dormant. landave/TeamSpeakHasher bringt das auf OpenCL, der CUDA-Fork von thissepic ist aktuell das aktivste Tool und schafft auf einer RTX 4070 Ti rund 20 GH/s. bratkartoffel/ts3idtools macht das in C mit pthreads auf der CPU.
Allen gemeinsam ist die UX-Lücke: keines schreibt das Ergebnis zurück. Der typische Workflow ist Pubkey aus der .ini extrahieren, Hasher füttern, Counter aufschreiben, Counter manuell in die .ini patchen, Datei re-importieren. landave begründet das bewusst mit Privatekey-Schutz, der Hasher soll den Private Key gar nicht erst zu sehen kriegen. Eine sehr saubere Trennung, aber für den Endanwender eine ziemlich friktionsreiche Angelegenheit.
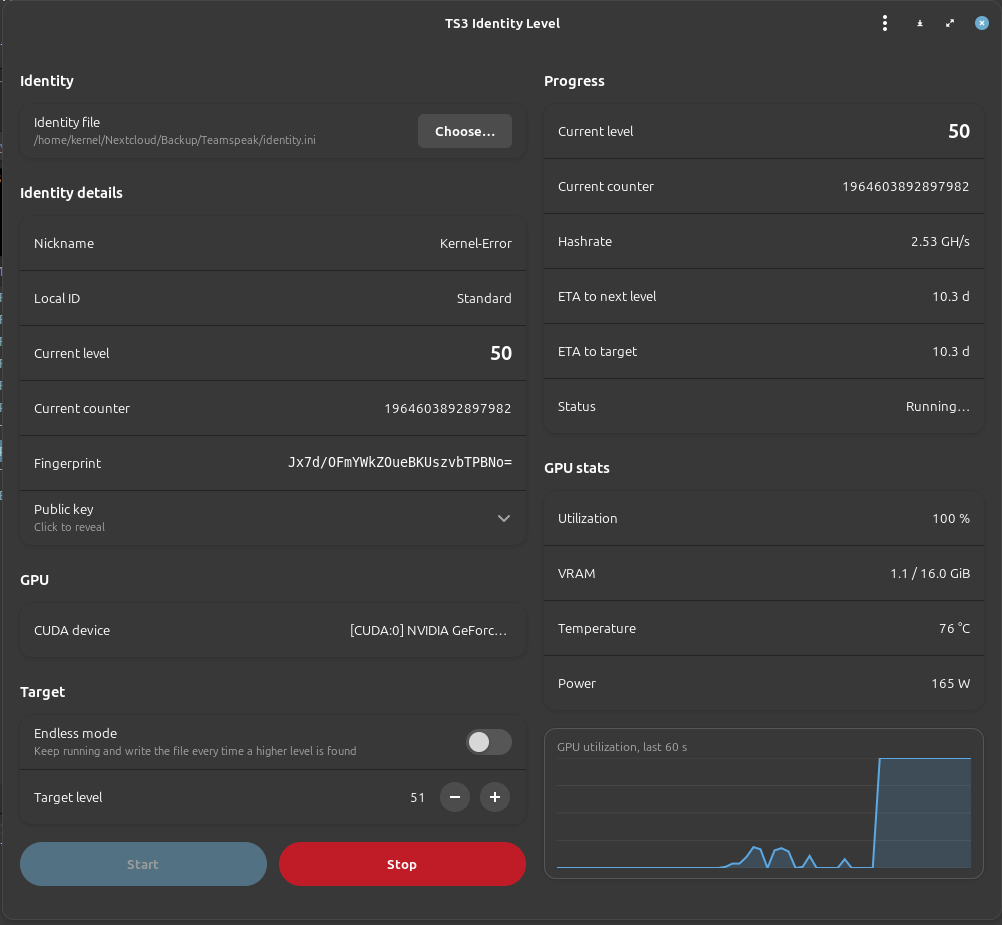
Genau dort setzt ts3level an. Man zeigt auf seine .ini, der Rest passiert automatisch. Atomarer Write, einmaliges .bak, fertig. Drumherum eine GTK-GUI, NVML-Telemetrie, Übersetzungen auf en/de/es/fr, eine ehrliche ETA-Anzeige und ein Identity-Details-Panel, damit man nicht jedes Mal die Datei von Hand parsen muss.
Wie funktioniert „Security Level“ überhaupt?
Die Kernformel ist erfrischend einfach:
level = leading_zero_bits( SHA1( pubkey_b64 || decimal(counter) ) )
pubkey_b64 ist die base64 der public-key-only ASN.1 DER eines ECDSA-Keys auf der Kurve secp256r1 (NIST P-256). Es ist genau der String, den der TS3-Client im Identity-Dialog unter „Public Key“ anzeigt. decimal(counter) ist die ganz normale Dezimaldarstellung des uint64 ohne Padding, also "42" und nicht "0042". Konkatenation passiert auf ASCII-Stringebene, nicht auf irgendwelchen rohen Bytes. Klingt banal, ist aber tatsächlich die häufigste Fehlerquelle bei Re-Implementierungen.
Das Zählen der führenden Null-Bits läuft byte-0-zuerst und innerhalb jedes Bytes von LSB nach MSB. Genau die hashcat-Konvention. In Python wäre das:
zero_bytes = 0
while zero_bytes < 20 and hash[zero_bytes] == 0:
zero_bytes += 1
zero_bits = 0
if zero_bytes < 20:
b = hash[zero_bytes]
while not (b & 1):
zero_bits += 1
b >>= 1
level = 8 * zero_bytes + zero_bits
Die Wahrscheinlichkeit dass ein einzelner Hash mindestens Level L erreicht ist 1 / 2^L. Im Mittel braucht es also 2^L Versuche pro angestrebtes Level. Auf meiner Testkarte, einer RTX 4060 Ti bei rund 2,4 GH/s, sieht das so aus:
| Ziel-Level | Mittlere Wartezeit |
|---|---|
| 40 | ~7 Minuten |
| 45 | ~4 Stunden |
| 50 | ~5 Tage |
| 55 | ~5 Monate |
| 60 | ~14 Jahre |
Diese Werte sind statistische Mittelwerte. Die echte Wartezeit ist exponentialverteilt, man kann also mit Faktor 2 bis 3 schneller oder langsamer Glück haben. Genau deshalb zeigt das Tool die ETA auch als das was sie ist (ein Mittelwert), und nicht als seriös wirkenden Countdown.
Was im .ini-File steckt
Eine exportierte TS3-Identity sieht ungefähr so aus:
[Identity] id=Standard identity="<counter>V<base64_obfuscated_blob>" nickname=Kernel-Error phonetic_nickname=
Der Teil hinter dem V ist doppelt base64-codiert, mit einer XOR-Schicht dazwischen. Das hat landave per Black-Box-Analyse aus dem Client-Verhalten rekonstruiert. Schematisch:
data = base64_decode(blob_b64) # outer base64 hash_part = data[20:] # everything past the first 20 bytes sha = sha1(hash_part) data[0:20] ^= sha # undo SHA-1 mask data[0:min(100, len)] ^= TSKEY # undo static-key XOR inner_ascii = data # ASCII-base64 of the ASN.1 DER asn1_der = base64_decode(inner_ascii) # inner base64
Der amüsante Stolperstein dabei: TSKEY ist im C-Original definiert als const char *TSKEY = "b9dfaa7bee...";. Das sind nicht die 64 Hex-Bytes, sondern die 128 ASCII-Zeichen der Hex-Darstellung selbst. Eine Stunde Debugging, bis ich gemerkt habe woran es liegt. Ist halt einer dieser Punkte, bei denen die Spec ohne Quelltext nicht reichen würde.
Im inneren DER liegt der libtomcrypt-formatierte Keypair:
SEQUENCE {
BIT STRING flags -- 1 bit; 0 = public-only, 1 = with private key
SHORT INTEGER keysize -- 32 for P-256
INTEGER x
INTEGER y
[INTEGER k] -- only when flags = 1
}
Für den Hash-Input brauchen wir nur die public-only Variante dieses DER-Blobs: gleiche Struktur, flags=0, X, Y, und der private Skalar k fällt einfach raus. Der Hasher bekommt damit nie den privaten Schlüssel zu sehen. Genau diese Trennung, die landave aus gutem Grund eingeführt hat, bleibt erhalten. Das Auto-Patchen der .ini passiert in einem separaten Modul, das den Counter zurückschreibt, ohne den Private Key überhaupt anzufassen.
Warum eine GPU
SHA-1 ist ein dankbarer Kandidat für massiv-paralleles Hashing. Es gibt keine Datenabhängigkeiten zwischen verschiedenen Counter-Werten, jede der zigtausend GPU-Threads kann einen anderen Counter testen und das Ergebnis unabhängig vergleichen. Ein moderner Desktop-Kern auf der CPU kommt vielleicht in den niedrigen dreistelligen MH/s-Bereich für SHA-1, eine RTX 4060 Ti im Tool rund 2,4 GH/s. Das reicht um aus Level 50 statt „mehreren Jahren“ so etwas wie „mehreren Tagen“ zu machen, also einen Bereich, in dem ein Run überhaupt erst Sinn ergibt.
Das Tool macht nichts Heldenhaftes mit dem Kernel: simples SHA-1 in CUDA C, ein Counter pro Thread, atomarer Compare-and-Swap auf der „bester gefundener Level“-Variable im global memory. Hochoptimierte Hasher wie der von thissepic kommen mit Midstate-Precompute und LOP3.LUT-Tricks auf ungefähr das fünffache. Dieser Teil steht auf der Roadmap, ist aber für den ersten Release bewusst nicht angegangen worden. Der eigentliche Mehrwert von ts3level ist UX und Auto-Patch, nicht der letzte ausgequetschte GH/s.
Was das Tool macht: zwei Binaries, ein Source-Tree
Aus dem Workspace fallen zwei Binaries:
ts3level: headless CLI mit Progress-Spinner, gut für Server, tmux, SSH-Sessionsts3level-gui: GTK4 + libadwaita Desktop-Anwendung, übersetzt in en/de/es/fr
Konkrete Use-Cases, die im Auge waren beim Entwurf:
- Die eigene TS-Identity von einem aktuellen Level (z. B. 45) auf ein Wunsch-Level (z. B. 55) hochrechnen, ohne sich mit base64-Blobs und Counter-Werten herumzuschlagen.
- Headless auf einem Server mit einer NVIDIA-Karte über Nacht laufen lassen, morgens fertige
.iniaus dem Backup-Verzeichnis ziehen. - Endless-Mode: das Tool läuft permanent, jedes Mal wenn ein höheres Level gefunden wird, wird die Datei sofort aktualisiert. Wer kein konkretes Ziel hat und einfach gucken will, was an einem Wochenende rauskommt, fährt damit ganz gut.
- Identity-Details ablesen, ohne die
.iniper Hand zu parsen: Nickname, Fingerprint (also die TS3-„Unique ID“), Public Key, Current Level, Current Counter.
Beim Start auf eine frisch generierte Demo-Identity sieht der CLI-Output so aus:
Using device: [CUDA:0] NVIDIA GeForce RTX 4060 Ti (cc 8.9, 34 SMs, 15.6 GiB) Nickname: DemoUser Local ID: DemoStandard Fingerprint: 3cltecu4AFn+OK7Lx3Ish6wZN+Y= Current level: 25 (counter: 7131210) note: target 1 <= 25 (current level): raising to 26 Target: 26
Und während der Run läuft sieht die Statuszeile so aus:
⠹ level: 50 counter: 1964603892897982 2.45 GH/s ETA→+1: 0.4s ETA→target: 10.3d GPU: 100% 76°C 165W (10s)
In der GUI ist genau dieselbe Information da, plus ein 60-Sekunden-Ringbuffer-Graph der GPU-Auslastung. Praktisch wenn man parallel zockt und sehen will, ob der Hash-Run noch genug Luft hat oder die Karte sich gegen das Spiel durchsetzen muss.
Architektur (kurz)
Komplett Rust, fünf Crates in einem Workspace:
crates/ts3level-core/ parser, obfuscation, pubkey extraction, CPU SHA-1, atomic writer crates/ts3level-engine/ HashEngine trait, preflight, driver loop, NVML telemetry crates/ts3level-cuda/ SHA-1 kernel in CUDA C, bound via cudarc crates/ts3level-cli/ clap + indicatif + gettext crates/ts3level-gui/ gtk4-rs + libadwaita + Cairo graph
Beim Build ruft build.rs einmal nvcc --fatbin auf und erzeugt eine Fatbin mit echtem SASS für sm_70, sm_75, sm_80, sm_86, sm_89, sm_90, plus PTX-Fallback für künftige Architekturen. Diese Fatbin wird per include_bytes! direkt in das Rust-Binary einkompiliert. Der Endanwender braucht damit nur den NVIDIA-Treiber, kein CUDA-Toolkit. libcuda.so.1 und libnvidia-ml.so.1 werden zur Laufzeit per dlopen gezogen, das funktioniert ab Treiber 525 ohne Klimmzüge.
Das Zurückschreiben in die .ini macht das Tool über flock(LOCK_EX) auf die Datei, einmaliges .bak wenn keines existiert, neue Bytes in eine tempfile::NamedTempFile im selben Verzeichnis, fsync, anschließend rename(2) drüber. POSIX-atomar. Bei Stromausfall mittendrin gibt es entweder die alte oder die neue Datei, nie ein halbgares Gemisch.
Vor jedem Run prüft ein Preflight neun Bedingungen: libcuda ladbar, CUDA-Devices vorhanden, Zugriffsrechte auf /dev/nvidia*, .ini lesbar, schreibbar, Parent-Dir schreibbar, Datei strukturell gültig, kein konkurrierender Lock, genug Platz für eine .bak. Fehler werden als strukturierte Codes ausgegeben, dokumentiert in der README. Backtraces gibt es nicht, weil sie für Endanwender nur Lärm sind.
Tests stehen bei 68 verteilt über alle Crates: 40 in ts3level-core (Parser, Obfuscation, Pubkey, Level-Berechnung, Writer, Sign-Prefix-Edge-Cases), 18 in ts3level-engine (Preflight, Driver, ETA, GpuStats), 3 in ts3level-cuda (eine Million Counter Parity GPU vs. CPU, Hashrate-Probe), 7 in ts3level-cli (Smoke-Tests, End-to-End gegen eine echte GPU, i18n).
Validierung gegen den echten TS3-Client
Einfacher aber wichtiger Schritt: nachdem das Tool intern korrekt aussah, habe ich eine reale Identity aus dem TS3-Client exportiert und parallel den vom Tool berechneten Fingerprint und das Security Level mit der Anzeige im Client verglichen. Beides byte-identisch. Heisst: die Algorithmus-Spec stimmt, es gibt kein Off-by-One zwischen meiner Implementierung und dem, was ein TS-Server für die Identifikation tatsächlich sieht. Wer den Counter mit ts3level hochrechnet, bekommt eine Identity, die der Client genauso akzeptiert, als hätte er den Aufwand selbst betrieben.
Hardware-Support
Out-of-the-Box im prebuilt Tarball:
| Generation | Beispiele | Compute Cap |
|---|---|---|
| Volta | Titan V, V100 | sm_70 |
| Turing | RTX 2060/70/80, T4 | sm_75 |
| Ampere DC | A100 | sm_80 |
| Ampere Consumer | RTX 3060/70/80/90 | sm_86 |
| Ada | RTX 4060/70/80/90 | sm_89 |
| Hopper | H100 | sm_90 |
| Blackwell und künftige | RTX 5xxx, GB200 | sm_100+ via JIT |
Pascal (GTX 10-Serie) und älter sind bewusst nicht dabei. Eine Zeile in build.rs ergänzen und neu bauen reicht, dann läuft auch das, nur ist die SHA-1-Performance auf diesen Karten ohnehin nicht konkurrenzfähig.
Installation
Auf Ubuntu, Mint oder Debian sieht das so aus:
sudo apt install nvidia-driver-550 libgtk-4-1 libadwaita-1-0 gettext-base sudo usermod -aG render $USER # log out and back in afterwards curl -LO https://github.com/Kernel-Error/ts-identities-security-level/releases/download/v0.1.0/ts3level-v0.1.0-x86_64-linux.tar.gz tar -xzf ts3level-v0.1.0-x86_64-linux.tar.gz cd ts3level-v0.1.0-x86_64-linux sudo install -m755 bin/ts3level /usr/local/bin/ sudo install -m755 bin/ts3level-gui /usr/local/bin/ sudo cp -r share/locale/* /usr/share/locale/
Verifizieren mit ts3level --list-devices. Die volle Installationsanleitung inklusive Rechte-Setup und Troubleshooting steht im Repo unter docs/installation.md.
Bekannte Grenzen und Roadmap
Ehrlich bleiben:
- 2,4 GH/s auf der 4060 Ti sind nur ungefähr ein Achtel dessen, was thissepic mit hand-optimierten Kernels rausholt. Midstate-Precompute, In-Place-Counter-Inkrement und LOP3.LUT-PTX-Tricks würden das in den 10 GH/s-Bereich heben. Steht auf der Roadmap, aber nicht für den ersten Release.
- v0.1 ist NVIDIA-only. Das
HashEngine-Trait ist allerdings genau dafür gedacht: ein OpenCL-Backend für AMD und Intel wäre ein relativ entspannter Drop-In. - Kein Flatpak bisher. Wer auf älteren Distros sitzt, etwa Ubuntu 22.04 mit glibc 2.35, muss aus den Quellen bauen. Lässt sich machen, ist aber nicht das Plug-and-Play das man von einem Tarball erwartet.
- Pascal und älter brauchen den oben erwähnten Einzeiler in
build.rs.
Die volle Roadmap mit Effort/Impact-Einschätzung liegt im Repo unter docs/roadmap.md.
Lizenz, Repo, Disclaimer
MIT-Lizenz, Repo unter github.com/Kernel-Error/ts-identities-security-level. Releases inklusive prebuilt Tarball werden auf der Releases-Seite veröffentlicht.
Dieses Tool ist nicht mit der TeamSpeak Systems GmbH affiliiert, von ihr endorsed oder gesponsort. „TeamSpeak“ ist eine Wortmarke der TeamSpeak Systems GmbH und wird hier ausschließlich beschreibend verwendet.
Das Tool kommuniziert nicht mit TS-Servern, umgeht keine Zugangsbeschränkungen, rechnet ausschließlich offline auf einer Datei, die dem Anwender selbst gehört. Algorithmisch dasselbe was der offizielle Client auch tut, nur eben auf der GPU. §69d UrhG (Beobachtung, Untersuchung und Testen von Software) deckt die Black-Box-Analyse ab, aus der die Algorithmus-Specs in Tools wie landave/TSIdentityTool über Jahre öffentlich entstanden sind. §202c StGB greift nicht: kein Bypass einer Zugangskontrolle, keine fremden Systeme, eigene Daten. Mein Versuch einer rechtliche Einordnung steht im Repo unter docs/legal.md.
Siehe auch: Voltcraft CM 2016 mit GTK4-GUI unter Linux (anderes GTK4-Projekt, andere Hardware), peon-ping Sound-Benachrichtigungen (kleines Rust-Tool fuer den Desktop).
Fragen, Kommentare oder Verbesserungsvorschläge gerne über die fragen-Seite oder als Issue im Repo.